 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeME$^3$-BEV: Mamba-Enhanced Deep Reinforcement Learning for End-to-End Autonomous Driving with BEV-Perception
Aug 08, 2025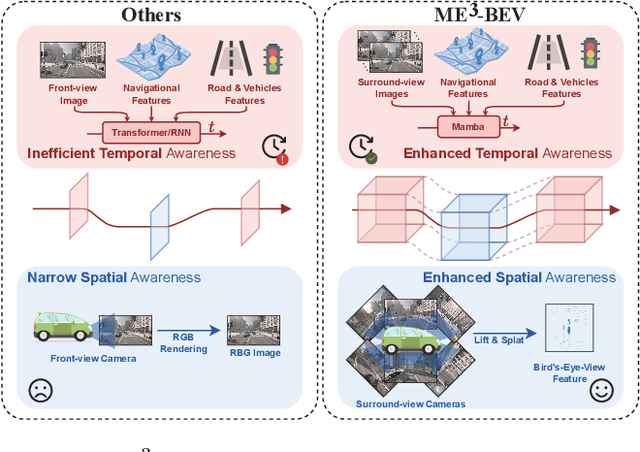
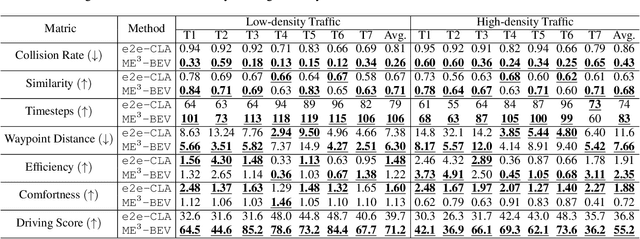
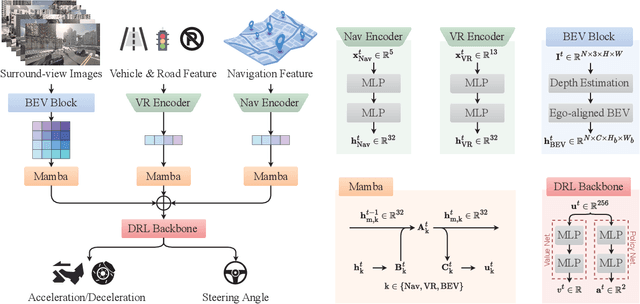

Autonomous driving systems face significant challenges in perceiving complex environments and making real-time decisions. Traditional modular approaches, while offering interpretability, suffer from error propagation and coordination issues, whereas end-to-end learning systems can simplify the design but face computational bottlenecks. This paper presents a novel approach to autonomous driving using deep reinforcement learning (DRL) that integrates bird's-eye view (BEV) perception for enhanced real-time decision-making. We introduce the \texttt{Mamba-BEV} model, an efficient spatio-temporal feature extraction network that combines BEV-based perception with the Mamba framework for temporal feature modeling. This integration allows the system to encode vehicle surroundings and road features in a unified coordinate system and accurately model long-range dependencies. Building on this, we propose the \texttt{ME$^3$-BEV} framework, which utilizes the \texttt{Mamba-BEV} model as a feature input for end-to-end DRL, achieving superior performance in dynamic urban driving scenarios. We further enhance the interpretability of the model by visualizing high-dimensional features through semantic segmentation, providing insight into the learned representations. Extensive experiments on the CARLA simulator demonstrate that \texttt{ME$^3$-BEV} outperforms existing models across multiple metrics, including collision rate and trajectory accuracy, offering a promising solution for real-time autonomous driving.
Hierarchical End-to-End Autonomous Driving: Integrating BEV Perception with Deep Reinforcement Learning
Sep 26, 2024End-to-end autonomous driving offers a streamlined alternative to the traditional modular pipeline, integrating perception, prediction, and planning within a single framework. While Deep Reinforcement Learning (DRL) has recently gained traction in this domain, existing approaches often overlook the critical connection between feature extraction of DRL and perception. In this paper, we bridge this gap by mapping the DRL feature extraction network directly to the perception phase, enabling clearer interpretation through semantic segmentation. By leveraging Bird's-Eye-View (BEV) representations, we propose a novel DRL-based end-to-end driving framework that utilizes multi-sensor inputs to construct a unified three-dimensional understanding of the environment. This BEV-based system extracts and translates critical environmental features into high-level abstract states for DRL, facilitating more informed control. Extensive experimental evaluations demonstrate that our approach not only enhances interpretability but also significantly outperforms state-of-the-art methods in autonomous driving control tasks, reducing the collision rate by 20%.
OFVL-MS: Once for Visual Localization across Multiple Indoor Scenes
Aug 23, 2023



In this work, we seek to predict camera poses across scenes with a multi-task learning manner, where we view the localization of each scene as a new task. We propose OFVL-MS, a unified framework that dispenses with the traditional practice of training a model for each individual scene and relieves gradient conflict induced by optimizing multiple scenes collectively, enabling efficient storage yet precise visual localization for all scenes. Technically, in the forward pass of OFVL-MS, we design a layer-adaptive sharing policy with a learnable score for each layer to automatically determine whether the layer is shared or not. Such sharing policy empowers us to acquire task-shared parameters for a reduction of storage cost and task-specific parameters for learning scene-related features to alleviate gradient conflict. In the backward pass of OFVL-MS, we introduce a gradient normalization algorithm that homogenizes the gradient magnitude of the task-shared parameters so that all tasks converge at the same pace. Furthermore, a sparse penalty loss is applied on the learnable scores to facilitate parameter sharing for all tasks without performance degradation. We conduct comprehensive experiments on multiple benchmarks and our new released indoor dataset LIVL, showing that OFVL-MS families significantly outperform the state-of-the-arts with fewer parameters. We also verify that OFVL-MS can generalize to a new scene with much few parameters while gaining superior localization performance.