 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRockTrack: A 3D Robust Multi-Camera-Ken Multi-Object Tracking Framework
Sep 18, 2024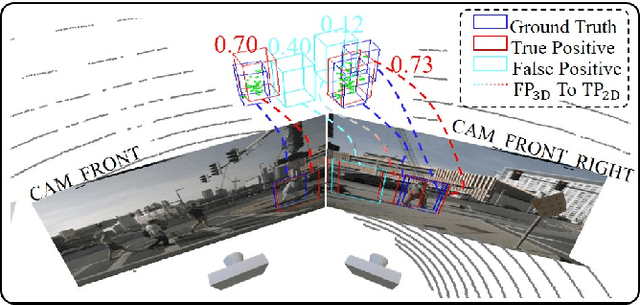
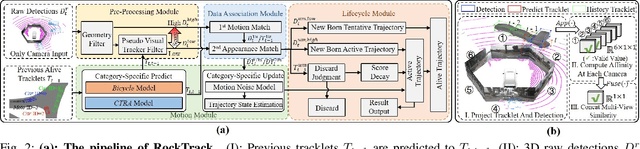

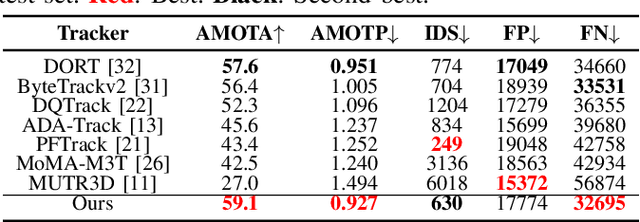
3D Multi-Object Tracking (MOT) obtains significant performance improvements with the rapid advancements in 3D object detection, particularly in cost-effective multi-camera setups. However, the prevalent end-to-end training approach for multi-camera trackers results in detector-specific models, limiting their versatility. Moreover, current generic trackers overlook the unique features of multi-camera detectors, i.e., the unreliability of motion observations and the feasibility of visual information. To address these challenges, we propose RockTrack, a 3D MOT method for multi-camera detectors. Following the Tracking-By-Detection framework, RockTrack is compatible with various off-the-shelf detectors. RockTrack incorporates a confidence-guided preprocessing module to extract reliable motion and image observations from distinct representation spaces from a single detector. These observations are then fused in an association module that leverages geometric and appearance cues to minimize mismatches. The resulting matches are propagated through a staged estimation process, forming the basis for heuristic noise modeling. Additionally, we introduce a novel appearance similarity metric for explicitly characterizing object affinities in multi-camera settings. RockTrack achieves state-of-the-art performance on the nuScenes vision-only tracking leaderboard with 59.1% AMOTA while demonstrating impressive computational efficiency.
Fast-Poly: A Fast Polyhedral Framework For 3D Multi-Object Tracking
Mar 20, 2024



3D Multi-Object Tracking (MOT) captures stable and comprehensive motion states of surrounding obstacles, essential for robotic perception. However, current 3D trackers face issues with accuracy and latency consistency. In this paper, we propose Fast-Poly, a fast and effective filter-based method for 3D MOT. Building upon our previous work Poly-MOT, Fast-Poly addresses object rotational anisotropy in 3D space, enhances local computation densification, and leverages parallelization technique, improving inference speed and precision. Fast-Poly is extensively tested on two large-scale tracking benchmarks with Python implementation. On the nuScenes dataset, Fast-Poly achieves new state-of-the-art performance with 75.8% AMOTA among all methods and can run at 34.2 FPS on a personal CPU. On the Waymo dataset, Fast-Poly exhibits competitive accuracy with 63.6% MOTA and impressive inference speed (35.5 FPS). The source code is publicly available at https://github.com/lixiaoyu2000/FastPoly.
OFVL-MS: Once for Visual Localization across Multiple Indoor Scenes
Aug 23, 2023



In this work, we seek to predict camera poses across scenes with a multi-task learning manner, where we view the localization of each scene as a new task. We propose OFVL-MS, a unified framework that dispenses with the traditional practice of training a model for each individual scene and relieves gradient conflict induced by optimizing multiple scenes collectively, enabling efficient storage yet precise visual localization for all scenes. Technically, in the forward pass of OFVL-MS, we design a layer-adaptive sharing policy with a learnable score for each layer to automatically determine whether the layer is shared or not. Such sharing policy empowers us to acquire task-shared parameters for a reduction of storage cost and task-specific parameters for learning scene-related features to alleviate gradient conflict. In the backward pass of OFVL-MS, we introduce a gradient normalization algorithm that homogenizes the gradient magnitude of the task-shared parameters so that all tasks converge at the same pace. Furthermore, a sparse penalty loss is applied on the learnable scores to facilitate parameter sharing for all tasks without performance degradation. We conduct comprehensive experiments on multiple benchmarks and our new released indoor dataset LIVL, showing that OFVL-MS families significantly outperform the state-of-the-arts with fewer parameters. We also verify that OFVL-MS can generalize to a new scene with much few parameters while gaining superior localization performance.
Poly-MOT: A Polyhedral Framework For 3D Multi-Object Tracking
Jul 31, 2023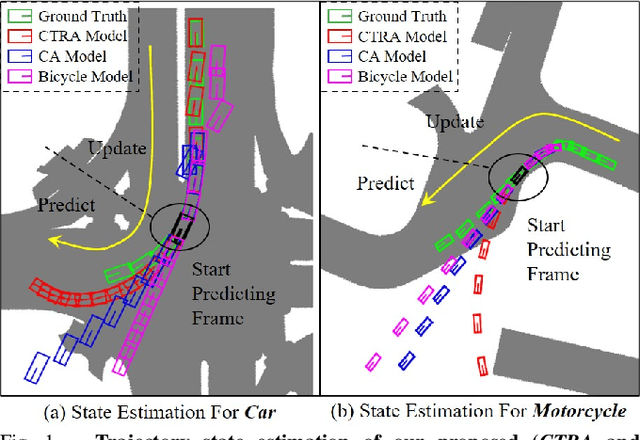
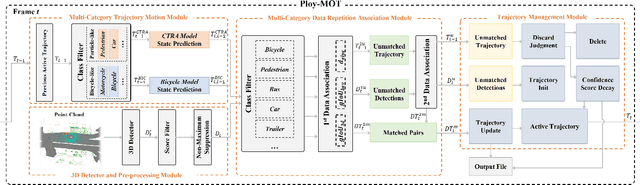
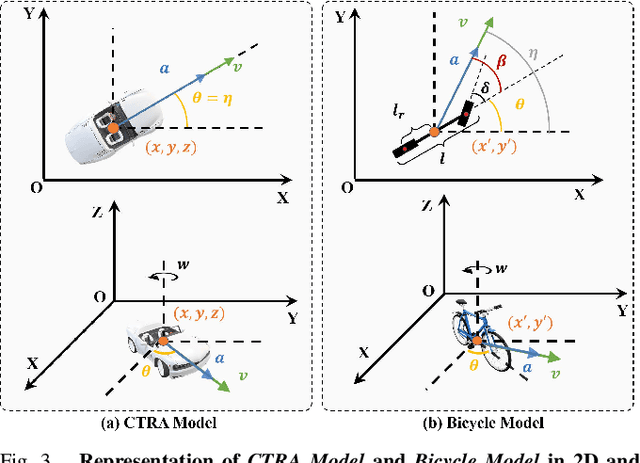

3D Multi-object tracking (MOT) empowers mobile robots to accomplish well-informed motion planning and navigation tasks by providing motion trajectories of surrounding objects. However, existing 3D MOT methods typically employ a single similarity metric and physical model to perform data association and state estimation for all objects. With large-scale modern datasets and real scenes, there are a variety of object categories that commonly exhibit distinctive geometric properties and motion patterns. In this way, such distinctions would enable various object categories to behave differently under the same standard, resulting in erroneous matches between trajectories and detections, and jeopardizing the reliability of downstream tasks (navigation, etc.). Towards this end, we propose Poly-MOT, an efficient 3D MOT method based on the Tracking-By-Detection framework that enables the tracker to choose the most appropriate tracking criteria for each object category. Specifically, Poly-MOT leverages different motion models for various object categories to characterize distinct types of motion accurately. We also introduce the constraint of the rigid structure of objects into a specific motion model to accurately describe the highly nonlinear motion of the object. Additionally, we introduce a two-stage data association strategy to ensure that objects can find the optimal similarity metric from three custom metrics for their categories and reduce missing matches. On the NuScenes dataset, our proposed method achieves state-of-the-art performance with 75.4\% AMOTA. The code is available at https://github.com/lixiaoyu2000/Poly-MOT
Omni-Training for Data-Efficient Deep Learning
Oct 14, 2021


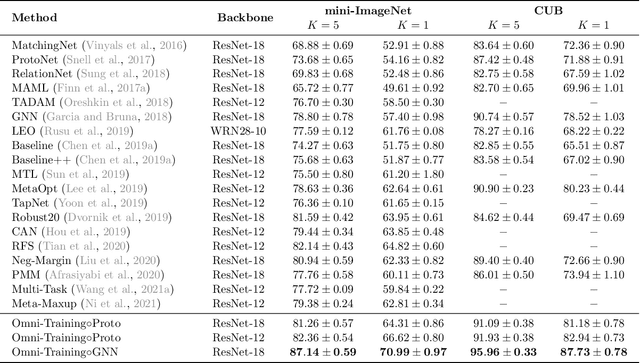
Learning a generalizable deep model from a few examples in a short time remains a major challenge of machine learning, which has impeded its wide deployment to many scenarios. Recent advances reveal that a properly pre-trained model endows an important property: transferability. A higher transferability of the learned representations indicates a better generalizability across domains of different distributions (domain transferability), or across tasks of different semantics (task transferability). Transferability has become the key to enable data-efficient deep learning, however, existing pre-training methods focus only on the domain transferability while meta-training methods only on the task transferability. This restricts their data-efficiency in downstream scenarios of diverging domains and tasks. A finding of this paper is that even a tight combination of pre-training and meta-training cannot achieve both kinds of transferability. This motivates the proposed Omni-Training framework towards data-efficient deep learning. Our first contribution is Omni-Net, a tri-flow architecture. Besides the joint representation flow, Omni-Net introduces two new parallel flows for pre-training and meta-training, respectively responsible for learning representations of domain transferability and task transferability. Omni-Net coordinates the parallel flows by routing them via the joint-flow, making each gain the other kind of transferability. Our second contribution is Omni-Loss, in which a mean-teacher regularization is imposed to learn generalizable and stabilized representations. Omni-Training is a general framework that accommodates many existing pre-training and meta-training algorithms. A thorough evaluation on cross-task and cross-domain datasets in classification, regression and reinforcement learning problems shows that Omni-Training consistently outperforms the state-of-the-art methods.
Self-Tuning for Data-Efficient Deep Learning
Feb 25, 2021



Deep learning has made revolutionary advances to diverse applications in the presence of large-scale labeled datasets. However, it is prohibitively time-costly and labor-expensive to collect sufficient labeled data in most realistic scenarios. To mitigate the requirement for labeled data, semi-supervised learning (SSL) focuses on simultaneously exploring both labeled and unlabeled data, while transfer learning (TL) popularizes a favorable practice of fine-tuning a pre-trained model to the target data. A dilemma is thus encountered: Without a decent pre-trained model to provide an implicit regularization, SSL through self-training from scratch will be easily misled by inaccurate pseudo-labels, especially in large-sized label space; Without exploring the intrinsic structure of unlabeled data, TL through fine-tuning from limited labeled data is at risk of under-transfer caused by model shift. To escape from this dilemma, we present Self-Tuning, a novel approach to enable data-efficient deep learning by unifying the exploration of labeled and unlabeled data and the transfer of a pre-trained model. Further, to address the challenge of confirmation bias in self-training, a Pseudo Group Contrast (PGC) mechanism is devised to mitigate the reliance on pseudo-labels and boost the tolerance to false-labels. Self-Tuning outperforms its SSL and TL counterparts on five tasks by sharp margins, e.g. it doubles the accuracy of fine-tuning on Cars with 15% labels.