 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking the Spatio-Temporal Alignment of End-to-End 3D Perception
Dec 29, 2025Spatio-temporal alignment is crucial for temporal modeling of end-to-end (E2E) perception in autonomous driving (AD), providing valuable structural and textural prior information. Existing methods typically rely on the attention mechanism to align objects across frames, simplifying the motion model with a unified explicit physical model (constant velocity, etc.). These approaches prefer semantic features for implicit alignment, challenging the importance of explicit motion modeling in the traditional perception paradigm. However, variations in motion states and object features across categories and frames render this alignment suboptimal. To address this, we propose HAT, a spatio-temporal alignment module that allows each object to adaptively decode the optimal alignment proposal from multiple hypotheses without direct supervision. Specifically, HAT first utilizes multiple explicit motion models to generate spatial anchors and motion-aware feature proposals for historical instances. It then performs multi-hypothesis decoding by incorporating semantic and motion cues embedded in cached object queries, ultimately providing the optimal alignment proposal for the target frame. On nuScenes, HAT consistently improves 3D temporal detectors and trackers across diverse baselines. It achieves state-of-the-art tracking results with 46.0% AMOTA on the test set when paired with the DETR3D detector. In an object-centric E2E AD method, HAT enhances perception accuracy (+1.3% mAP, +3.1% AMOTA) and reduces the collision rate by 32%. When semantics are corrupted (nuScenes-C), the enhancement of motion modeling by HAT enables more robust perception and planning in the E2E AD.
Does End-to-End Autonomous Driving Really Need Perception Tasks?
Sep 26, 2024End-to-End Autonomous Driving (E2EAD) methods typically rely on supervised perception tasks to extract explicit scene information (e.g., objects, maps). This reliance necessitates expensive annotations and constrains deployment and data scalability in real-time applications. In this paper, we introduce SSR, a novel framework that utilizes only 16 navigation-guided tokens as Sparse Scene Representation, efficiently extracting crucial scene information for E2EAD. Our method eliminates the need for supervised sub-tasks, allowing computational resources to concentrate on essential elements directly related to navigation intent. We further introduce a temporal enhancement module that employs a Bird's-Eye View (BEV) world model, aligning predicted future scenes with actual future scenes through self-supervision. SSR achieves state-of-the-art planning performance on the nuScenes dataset, demonstrating a 27.2\% relative reduction in L2 error and a 51.6\% decrease in collision rate to the leading E2EAD method, UniAD. Moreover, SSR offers a 10.9$\times$ faster inference speed and 13$\times$ faster training time. This framework represents a significant leap in real-time autonomous driving systems and paves the way for future scalable deployment. Code will be released at \url{https://github.com/PeidongLi/SSR}.
RockTrack: A 3D Robust Multi-Camera-Ken Multi-Object Tracking Framework
Sep 18, 2024
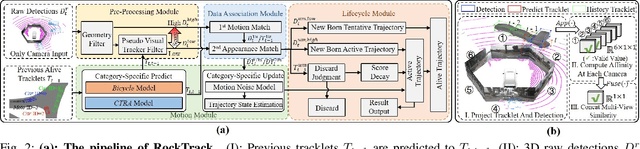

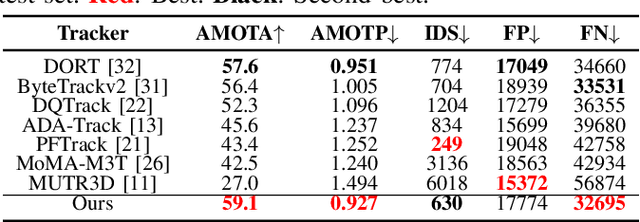
3D Multi-Object Tracking (MOT) obtains significant performance improvements with the rapid advancements in 3D object detection, particularly in cost-effective multi-camera setups. However, the prevalent end-to-end training approach for multi-camera trackers results in detector-specific models, limiting their versatility. Moreover, current generic trackers overlook the unique features of multi-camera detectors, i.e., the unreliability of motion observations and the feasibility of visual information. To address these challenges, we propose RockTrack, a 3D MOT method for multi-camera detectors. Following the Tracking-By-Detection framework, RockTrack is compatible with various off-the-shelf detectors. RockTrack incorporates a confidence-guided preprocessing module to extract reliable motion and image observations from distinct representation spaces from a single detector. These observations are then fused in an association module that leverages geometric and appearance cues to minimize mismatches. The resulting matches are propagated through a staged estimation process, forming the basis for heuristic noise modeling. Additionally, we introduce a novel appearance similarity metric for explicitly characterizing object affinities in multi-camera settings. RockTrack achieves state-of-the-art performance on the nuScenes vision-only tracking leaderboard with 59.1% AMOTA while demonstrating impressive computational efficiency.
DualBEV: CNN is All You Need in View Transformation
Mar 08, 2024Camera-based Bird's-Eye-View (BEV) perception often struggles between adopting 3D-to-2D or 2D-to-3D view transformation (VT). The 3D-to-2D VT typically employs resource intensive Transformer to establish robust correspondences between 3D and 2D feature, while the 2D-to-3D VT utilizes the Lift-Splat-Shoot (LSS) pipeline for real-time application, potentially missing distant information. To address these limitations, we propose DualBEV, a unified framework that utilizes a shared CNN-based feature transformation incorporating three probabilistic measurements for both strategies. By considering dual-view correspondences in one-stage, DualBEV effectively bridges the gap between these strategies, harnessing their individual strengths. Our method achieves state-of-the-art performance without Transformer, delivering comparable efficiency to the LSS approach, with 55.2% mAP and 63.4% NDS on the nuScenes test set. Code will be released at https://github.com/PeidongLi/DualBEV.