 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFusion-Poly: A Polyhedral Framework Based on Spatial-Temporal Fusion for 3D Multi-Object Tracking
Mar 09, 2026LiDAR-camera 3D multi-object tracking (MOT) combines rich visual semantics with accurate depth cues to improve trajectory consistency and tracking reliability. In practice, however, LiDAR and cameras operate at different sampling rates. To maintain temporal alignment, existing data pipelines usually synchronize heterogeneous sensor streams and annotate them at a reduced shared frequency, forcing most prior methods to perform spatial fusion only at synchronized timestamps through projection-based or learnable cross-sensor association. As a result, abundant asynchronous observations remain underexploited, despite their potential to support more frequent association and more robust trajectory estimation over short temporal intervals. To address this limitation, we propose Fusion-Poly, a spatial-temporal fusion framework for 3D MOT that integrates asynchronous LiDAR and camera data. Fusion-Poly associates trajectories with multi-modal observations at synchronized timestamps and with single-modal observations at asynchronous timestamps, enabling higher-frequency updates of motion and existence states. The framework contains three key components: a frequency-aware cascade matching module that adapts to synchronized and asynchronous frames according to available detection modalities; a frequency-aware trajectory estimation module that maintains trajectories through high-frequency motion prediction, differential updates, and confidence-calibrated lifecycle management; and a full-state observation alignment module that improves cross-modal consistency at synchronized timestamps by optimizing image-projection errors. On the nuScenes test set, Fusion-Poly achieves 76.5% AMOTA, establishing a new state of the art among tracking-by-detection 3D MOT methods. Extensive ablation studies further validate the effectiveness of each component. Code will be released.
LiDAR Prompted Spatio-Temporal Multi-View Stereo for Autonomous Driving
Mar 04, 2026Accurate metric depth is critical for autonomous driving perception and simulation, yet current approaches struggle to achieve high metric accuracy, multi-view and temporal consistency, and cross-domain generalization. To address these challenges, we present DriveMVS, a novel multi-view stereo framework that reconciles these competing objectives through two key insights: (1) Sparse but metrically accurate LiDAR observations can serve as geometric prompts to anchor depth estimation in absolute scale, and (2) deep fusion of diverse cues is essential for resolving ambiguities and enhancing robustness, while a spatio-temporal decoder ensures consistency across frames. Built upon these principles, DriveMVS embeds the LiDAR prompt in two ways: as a hard geometric prior that anchors the cost volume, and as soft feature-wise guidance fused by a triple-cue combiner. Regarding temporal consistency, DriveMVS employs a spatio-temporal decoder that jointly leverages geometric cues from the MVS cost volume and temporal context from neighboring frames. Experiments show that DriveMVS achieves state-of-the-art performance on multiple benchmarks, excelling in metric accuracy, temporal stability, and zero-shot cross-domain transfer, demonstrating its practical value for scalable, reliable autonomous driving systems.
Offline-Poly: A Polyhedral Framework For Offline 3D Multi-Object Tracking
Feb 14, 2026Offline 3D multi-object tracking (MOT) is a critical component of the 4D auto-labeling (4DAL) process. It enhances pseudo-labels generated by high-performance detectors through the incorporation of temporal context. However, existing offline 3D MOT approaches are direct extensions of online frameworks and fail to fully exploit the advantages of offline setting. Moreover, these methods often depend on fixed upstream and customized architectures, limiting their adaptability. To address these limitations, we propose Offline-Poly, a general offline 3D MOT method based on a tracking-centric design. We introduce a standardized paradigm termed Tracking-by-Tracking (TBT), which operates exclusively on arbitrary off-the-shelf tracking outputs and produces offline-refined tracklets. This formulation decouples offline tracker from specific upstream detectors or trackers. Under the TBT paradigm, Offline-Poly accepts one or multiple coarse tracking results and processes them through a structured pipeline comprising pre-processing, hierarchical matching and fusion, and tracklet refinement. Each module is designed to capitalize on the two fundamental properties of offline tracking: resource unconstrainedness, which permits global optimization beyond real-time limits, and future observability, which enables tracklet reasoning over the full temporal horizon. Offline-Poly first eliminates short-term ghost tracklets and re-identifies fragmented segments using global scene context. It then constructs scene-level similarity to associate tracklets across multiple input sources. Finally, Offline-Poly refines tracklets by jointly leveraging local and global motion patterns. On nuScenes, we achieve SOTA performance with 77.6% AMOTA. On KITTI, it achieves leading results with 83.00% HOTA. Comprehensive experiments further validate the flexibility, generalizability, and modular effectiveness of Offline-Poly.
Rethinking the Spatio-Temporal Alignment of End-to-End 3D Perception
Dec 29, 2025Spatio-temporal alignment is crucial for temporal modeling of end-to-end (E2E) perception in autonomous driving (AD), providing valuable structural and textural prior information. Existing methods typically rely on the attention mechanism to align objects across frames, simplifying the motion model with a unified explicit physical model (constant velocity, etc.). These approaches prefer semantic features for implicit alignment, challenging the importance of explicit motion modeling in the traditional perception paradigm. However, variations in motion states and object features across categories and frames render this alignment suboptimal. To address this, we propose HAT, a spatio-temporal alignment module that allows each object to adaptively decode the optimal alignment proposal from multiple hypotheses without direct supervision. Specifically, HAT first utilizes multiple explicit motion models to generate spatial anchors and motion-aware feature proposals for historical instances. It then performs multi-hypothesis decoding by incorporating semantic and motion cues embedded in cached object queries, ultimately providing the optimal alignment proposal for the target frame. On nuScenes, HAT consistently improves 3D temporal detectors and trackers across diverse baselines. It achieves state-of-the-art tracking results with 46.0% AMOTA on the test set when paired with the DETR3D detector. In an object-centric E2E AD method, HAT enhances perception accuracy (+1.3% mAP, +3.1% AMOTA) and reduces the collision rate by 32%. When semantics are corrupted (nuScenes-C), the enhancement of motion modeling by HAT enables more robust perception and planning in the E2E AD.
Adaptive-LIO: Enhancing Robustness and Precision through Environmental Adaptation in LiDAR Inertial Odometry
Mar 07, 2025The emerging Internet of Things (IoT) applications, such as driverless cars, have a growing demand for high-precision positioning and navigation. Nowadays, LiDAR inertial odometry becomes increasingly prevalent in robotics and autonomous driving. However, many current SLAM systems lack sufficient adaptability to various scenarios. Challenges include decreased point cloud accuracy with longer frame intervals under the constant velocity assumption, coupling of erroneous IMU information when IMU saturation occurs, and decreased localization accuracy due to the use of fixed-resolution maps during indoor-outdoor scene transitions. To address these issues, we propose a loosely coupled adaptive LiDAR-Inertial-Odometry named \textbf{Adaptive-LIO}, which incorporates adaptive segmentation to enhance mapping accuracy, adapts motion modality through IMU saturation and fault detection, and adjusts map resolution adaptively using multi-resolution voxel maps based on the distance from the LiDAR center. Our proposed method has been tested in various challenging scenarios, demonstrating the effectiveness of the improvements we introduce. The code is open-source on GitHub: \href{https://github.com/chengwei0427/adaptive_lio}{Adaptive-LIO}.
Selective Kalman Filter: When and How to Fuse Multi-Sensor Information to Overcome Degeneracy in SLAM
Dec 23, 2024



Research trends in SLAM systems are now focusing more on multi-sensor fusion to handle challenging and degenerative environments. However, most existing multi-sensor fusion SLAM methods mainly use all of the data from a range of sensors, a strategy we refer to as the all-in method. This method, while merging the benefits of different sensors, also brings in their weaknesses, lowering the robustness and accuracy and leading to high computational demands. To address this, we propose a new fusion approach -- Selective Kalman Filter -- to carefully choose and fuse information from multiple sensors (using LiDAR and visual observations as examples in this paper). For deciding when to fuse data, we implement degeneracy detection in LiDAR SLAM, incorporating visual measurements only when LiDAR SLAM exhibits degeneracy. Regarding degeneracy detection, we propose an elegant yet straightforward approach to determine the degeneracy of LiDAR SLAM and to identify the specific degenerative direction. This method fully considers the coupled relationship between rotational and translational constraints. In terms of how to fuse data, we use visual measurements only to update the specific degenerative states. As a result, our proposed method improves upon the all-in method by greatly enhancing real-time performance due to less processing visual data, and it introduces fewer errors from visual measurements. Experiments demonstrate that our method for degeneracy detection and fusion, in addressing degeneracy issues, exhibits higher precision and robustness compared to other state-of-the-art methods, and offers enhanced real-time performance relative to the all-in method. The code is openly available.
RockTrack: A 3D Robust Multi-Camera-Ken Multi-Object Tracking Framework
Sep 18, 2024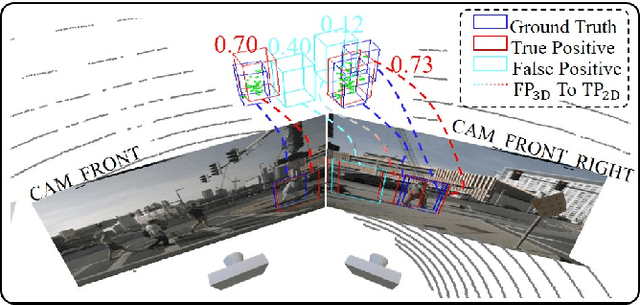
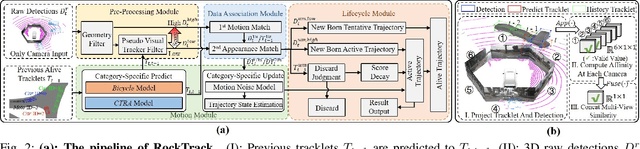

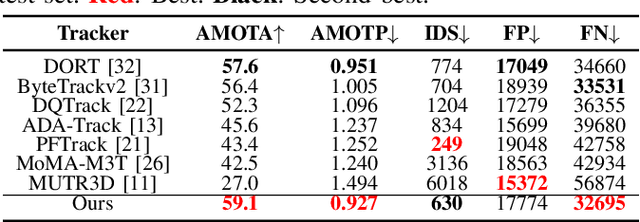
3D Multi-Object Tracking (MOT) obtains significant performance improvements with the rapid advancements in 3D object detection, particularly in cost-effective multi-camera setups. However, the prevalent end-to-end training approach for multi-camera trackers results in detector-specific models, limiting their versatility. Moreover, current generic trackers overlook the unique features of multi-camera detectors, i.e., the unreliability of motion observations and the feasibility of visual information. To address these challenges, we propose RockTrack, a 3D MOT method for multi-camera detectors. Following the Tracking-By-Detection framework, RockTrack is compatible with various off-the-shelf detectors. RockTrack incorporates a confidence-guided preprocessing module to extract reliable motion and image observations from distinct representation spaces from a single detector. These observations are then fused in an association module that leverages geometric and appearance cues to minimize mismatches. The resulting matches are propagated through a staged estimation process, forming the basis for heuristic noise modeling. Additionally, we introduce a novel appearance similarity metric for explicitly characterizing object affinities in multi-camera settings. RockTrack achieves state-of-the-art performance on the nuScenes vision-only tracking leaderboard with 59.1% AMOTA while demonstrating impressive computational efficiency.
Boosting 3D Object Detection with Semantic-Aware Multi-Branch Framework
Jul 08, 2024



In autonomous driving, LiDAR sensors are vital for acquiring 3D point clouds, providing reliable geometric information. However, traditional sampling methods of preprocessing often ignore semantic features, leading to detail loss and ground point interference in 3D object detection. To address this, we propose a multi-branch two-stage 3D object detection framework using a Semantic-aware Multi-branch Sampling (SMS) module and multi-view consistency constraints. The SMS module includes random sampling, Density Equalization Sampling (DES) for enhancing distant objects, and Ground Abandonment Sampling (GAS) to focus on non-ground points. The sampled multi-view points are processed through a Consistent KeyPoint Selection (CKPS) module to generate consistent keypoint masks for efficient proposal sampling. The first-stage detector uses multi-branch parallel learning with multi-view consistency loss for feature aggregation, while the second-stage detector fuses multi-view data through a Multi-View Fusion Pooling (MVFP) module to precisely predict 3D objects. The experimental results on KITTI 3D object detection benchmark dataset show that our method achieves excellent detection performance improvement for a variety of backbones, especially for low-performance backbones with the simple network structures.
I2EKF-LO: A Dual-Iteration Extended Kalman Filter Based LiDAR Odometry
Jul 02, 2024



LiDAR odometry is a pivotal technology in the fields of autonomous driving and autonomous mobile robotics. However, most of the current works focus on nonlinear optimization methods, and still existing many challenges in using the traditional Iterative Extended Kalman Filter (IEKF) framework to tackle the problem: IEKF only iterates over the observation equation, relying on a rough estimate of the initial state, which is insufficient to fully eliminate motion distortion in the input point cloud; the system process noise is difficult to be determined during state estimation of the complex motions; and the varying motion models across different sensor carriers. To address these issues, we propose the Dual-Iteration Extended Kalman Filter (I2EKF) and the LiDAR odometry based on I2EKF (I2EKF-LO). This approach not only iterates over the observation equation but also leverages state updates to iteratively mitigate motion distortion in LiDAR point clouds. Moreover, it dynamically adjusts process noise based on the confidence level of prior predictions during state estimation and establishes motion models for different sensor carriers to achieve accurate and efficient state estimation. Comprehensive experiments demonstrate that I2EKF-LO achieves outstanding levels of accuracy and computational efficiency in the realm of LiDAR odometry. Additionally, to foster community development, our code is open-sourced.https://github.com/YWL0720/I2EKF-LO.
Fast-Poly: A Fast Polyhedral Framework For 3D Multi-Object Tracking
Mar 20, 2024



3D Multi-Object Tracking (MOT) captures stable and comprehensive motion states of surrounding obstacles, essential for robotic perception. However, current 3D trackers face issues with accuracy and latency consistency. In this paper, we propose Fast-Poly, a fast and effective filter-based method for 3D MOT. Building upon our previous work Poly-MOT, Fast-Poly addresses object rotational anisotropy in 3D space, enhances local computation densification, and leverages parallelization technique, improving inference speed and precision. Fast-Poly is extensively tested on two large-scale tracking benchmarks with Python implementation. On the nuScenes dataset, Fast-Poly achieves new state-of-the-art performance with 75.8% AMOTA among all methods and can run at 34.2 FPS on a personal CPU. On the Waymo dataset, Fast-Poly exhibits competitive accuracy with 63.6% MOTA and impressive inference speed (35.5 FPS). The source code is publicly available at https://github.com/lixiaoyu2000/FastPoly.