 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReflectance Prediction-based Knowledge Distillation for Robust 3D Object Detection in Compressed Point Clouds
May 23, 2025Regarding intelligent transportation systems for vehicle networking, low-bitrate transmission via lossy point cloud compression is vital for facilitating real-time collaborative perception among vehicles with restricted bandwidth. In existing compression transmission systems, the sender lossily compresses point coordinates and reflectance to generate a transmission code stream, which faces transmission burdens from reflectance encoding and limited detection robustness due to information loss. To address these issues, this paper proposes a 3D object detection framework with reflectance prediction-based knowledge distillation (RPKD). We compress point coordinates while discarding reflectance during low-bitrate transmission, and feed the decoded non-reflectance compressed point clouds into a student detector. The discarded reflectance is then reconstructed by a geometry-based reflectance prediction (RP) module within the student detector for precise detection. A teacher detector with the same structure as student detector is designed for performing reflectance knowledge distillation (RKD) and detection knowledge distillation (DKD) from raw to compressed point clouds. Our RPKD framework jointly trains detectors on both raw and compressed point clouds to improve the student detector's robustness. Experimental results on the KITTI dataset and Waymo Open Dataset demonstrate that our method can boost detection accuracy for compressed point clouds across multiple code rates. Notably, at a low code rate of 2.146 Bpp on the KITTI dataset, our RPKD-PV achieves the highest mAP of 73.6, outperforming existing detection methods with the PV-RCNN baseline.
Boosting 3D Object Detection with Semantic-Aware Multi-Branch Framework
Jul 08, 2024



In autonomous driving, LiDAR sensors are vital for acquiring 3D point clouds, providing reliable geometric information. However, traditional sampling methods of preprocessing often ignore semantic features, leading to detail loss and ground point interference in 3D object detection. To address this, we propose a multi-branch two-stage 3D object detection framework using a Semantic-aware Multi-branch Sampling (SMS) module and multi-view consistency constraints. The SMS module includes random sampling, Density Equalization Sampling (DES) for enhancing distant objects, and Ground Abandonment Sampling (GAS) to focus on non-ground points. The sampled multi-view points are processed through a Consistent KeyPoint Selection (CKPS) module to generate consistent keypoint masks for efficient proposal sampling. The first-stage detector uses multi-branch parallel learning with multi-view consistency loss for feature aggregation, while the second-stage detector fuses multi-view data through a Multi-View Fusion Pooling (MVFP) module to precisely predict 3D objects. The experimental results on KITTI 3D object detection benchmark dataset show that our method achieves excellent detection performance improvement for a variety of backbones, especially for low-performance backbones with the simple network structures.
End-to-end translation of human neural activity to speech with a dual-dual generative adversarial network
Oct 13, 2021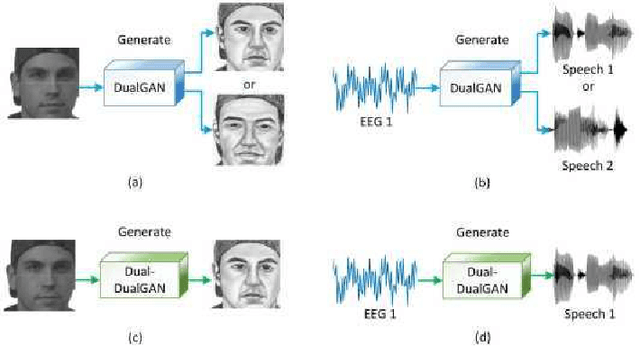
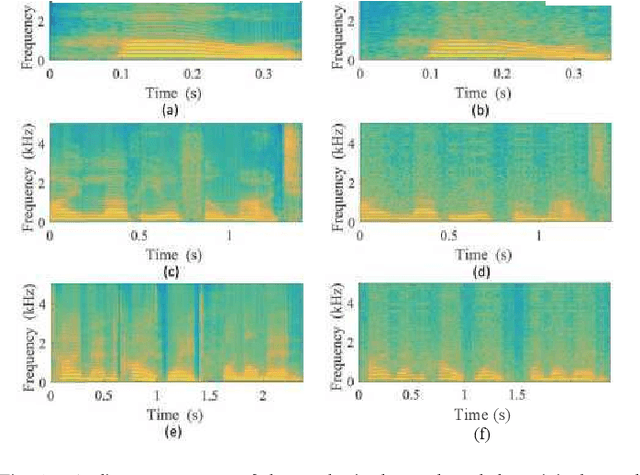
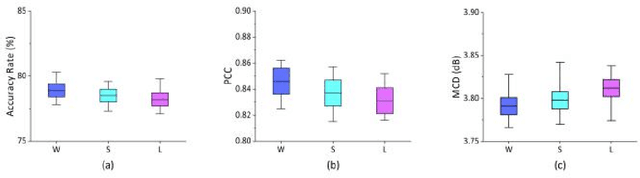
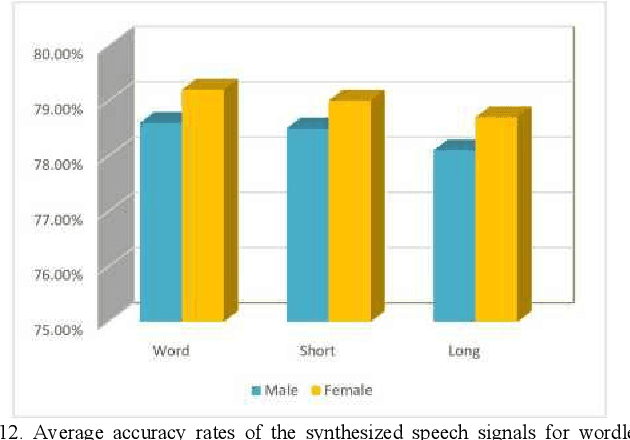
In a recent study of auditory evoked potential (AEP) based brain-computer interface (BCI), it was shown that, with an encoder-decoder framework, it is possible to translate human neural activity to speech (T-CAS). However, current encoder-decoder-based methods achieve T-CAS often with a two-step method where the information is passed between the encoder and decoder with a shared dimension reduction vector, which may result in a loss of information. A potential approach to this problem is to design an end-to-end method by using a dual generative adversarial network (DualGAN) without dimension reduction of passing information, but it cannot realize one-to-one signal-to-signal translation (see Fig.1 (a) and (b)). In this paper, we propose an end-to-end model to translate human neural activity to speech directly, create a new electroencephalogram (EEG) datasets for participants with good attention by design a device to detect participants' attention, and introduce a dual-dual generative adversarial network (Dual-DualGAN) (see Fig. 1 (c) and (d)) to address an end-to-end translation of human neural activity to speech (ET-CAS) problem by group labelling EEG signals and speech signals, inserting a transition domain to realize cross-domain mapping. In the transition domain, the transition signals are cascaded by the corresponding EEG and speech signals in a certain proportion, which can build bridges for EEG and speech signals without corresponding features, and realize one-to-one cross-domain EEG-to-speech translation. The proposed method can translate word-length and sentence-length sequences of neural activity to speech. Experimental evaluation has been conducted to show that the proposed method significantly outperforms state-of-the-art methods on both words and sentences of auditory stimulus.
Deep Optimized Multiple Description Image Coding via Scalar Quantization Learning
Jan 12, 2020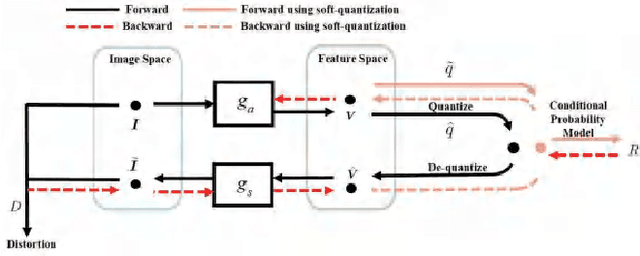

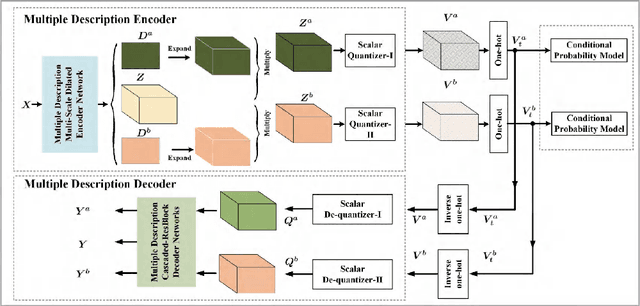
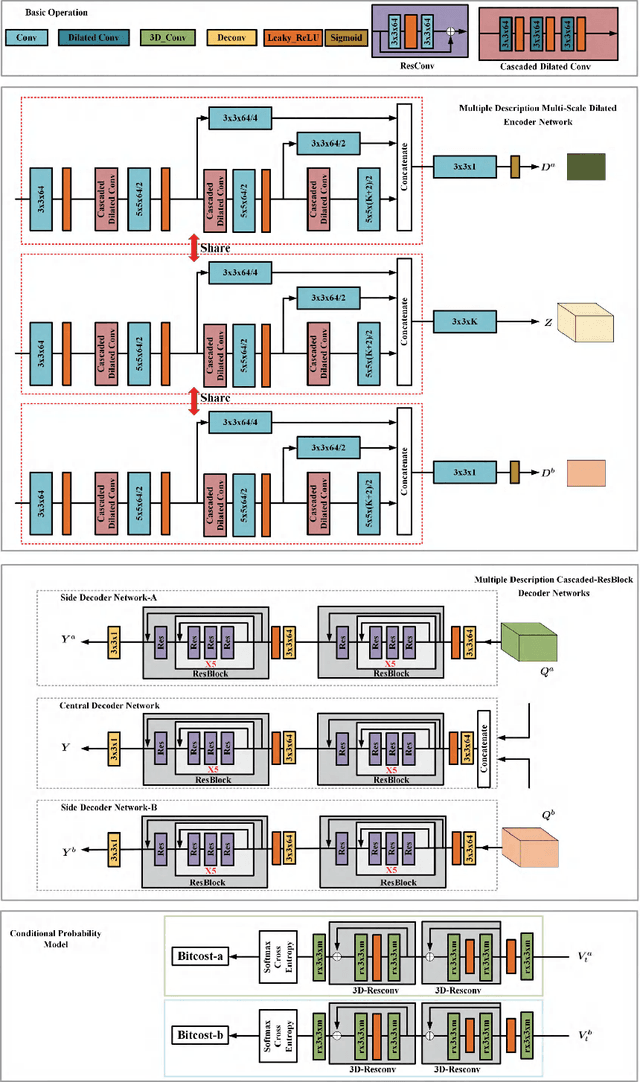
In this paper, we introduce a deep multiple description coding (MDC) framework optimized by minimizing multiple description (MD) compressive loss. First, MD multi-scale-dilated encoder network generates multiple description tensors, which are discretized by scalar quantizers, while these quantized tensors are decompressed by MD cascaded-ResBlock decoder networks. To greatly reduce the total amount of artificial neural network parameters, an auto-encoder network composed of these two types of network is designed as a symmetrical parameter sharing structure. Second, this autoencoder network and a pair of scalar quantizers are simultaneously learned in an end-to-end self-supervised way. Third, considering the variation in the image spatial distribution, each scalar quantizer is accompanied by an importance-indicator map to generate MD tensors, rather than using direct quantization. Fourth, we introduce the multiple description structural similarity distance loss, which implicitly regularizes the diversified multiple description generations, to explicitly supervise multiple description diversified decoding in addition to MD reconstruction loss. Finally, we demonstrate that our MDC framework performs better than several state-of-the-art MDC approaches regarding image coding efficiency when tested on several commonly available datasets.
Concurrently Extrapolating and Interpolating Networks for Continuous Model Generation
Jan 12, 2020


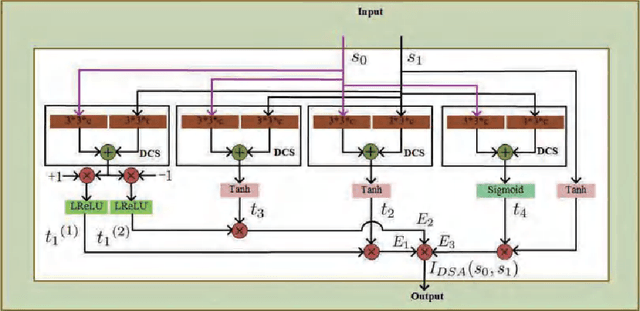
Most deep image smoothing operators are always trained repetitively when different explicit structure-texture pairs are employed as label images for each algorithm configured with different parameters. This kind of training strategy often takes a long time and spends equipment resources in a costly manner. To address this challenging issue, we generalize continuous network interpolation as a more powerful model generation tool, and then propose a simple yet effective model generation strategy to form a sequence of models that only requires a set of specific-effect label images. To precisely learn image smoothing operators, we present a double-state aggregation (DSA) module, which can be easily inserted into most of current network architecture. Based on this module, we design a double-state aggregation neural network structure with a local feature aggregation block and a nonlocal feature aggregation block to obtain operators with large expression capacity. Through the evaluation of many objective and visual experimental results, we show that the proposed method is capable of producing a series of continuous models and achieves better performance than that of several state-of-the-art methods for image smoothing.
Deep Multiple Description Coding by Learning Scalar Quantization
Nov 05, 2018



In this paper, we propose a deep multiple description coding framework, whose quantizers are adaptively learned via the minimization of multiple description compressive loss. Firstly, our framework is built upon auto-encoder networks, which have multiple description multi-scale dilated encoder network and multiple description decoder networks. Secondly, two entropy estimation networks are learned to estimate the informative amounts of the quantized tensors, which can further supervise the learning of multiple description encoder network to represent the input image delicately. Thirdly, a pair of scalar quantizers accompanied by two importance-indicator maps is automatically learned in an end-to-end self-supervised way. Finally, multiple description structural dis-similarity distance loss is imposed on multiple description decoded images in pixel domain for diversified multiple description generations rather than on feature tensors in feature domain, in addition to multiple description reconstruction loss. Through testing on two commonly used datasets, it is verified that our method is beyond several state-of-the-art multiple description coding approaches in terms of coding efficiency.
Mixed-Resolution Image Representation and Compression with Convolutional Neural Networks
Aug 01, 2018
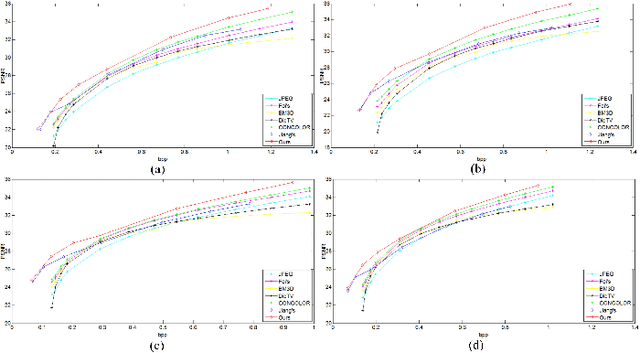
In this paper, we propose an end-to-end mixed-resolution image compression framework with convolutional neural networks. Firstly, given one input image, feature description neural network (FDNN) is used to generate a new representation of this image, so that this image representation can be more efficiently compressed by standard codec, as compared to the input image. Furthermore, we use post-processing neural network (PPNN) to remove the coding artifacts caused by quantization of codec. Secondly, low-resolution image representation is adopted for high efficiency compression in terms of most of bit spent by image's structures under low bit-rate. However, more bits should be assigned to image details in the high-resolution, when most of structures have been kept after compression at the high bit-rate. This comes from a fact that the low-resolution image representation can't burden more information than high-resolution representation beyond a certain bit-rate. Finally, to resolve the problem of error back-propagation from the PPNN network to the FDNN network, we introduce to learn a virtual codec neural network to imitate two continuous procedures of standard compression and post-processing. The objective experimental results have demonstrated the proposed method has a large margin improvement, when comparing with several state-of-the-art approaches.
Virtual Codec Supervised Re-Sampling Network for Image Compression
Jul 10, 2018
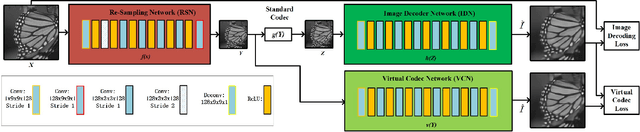
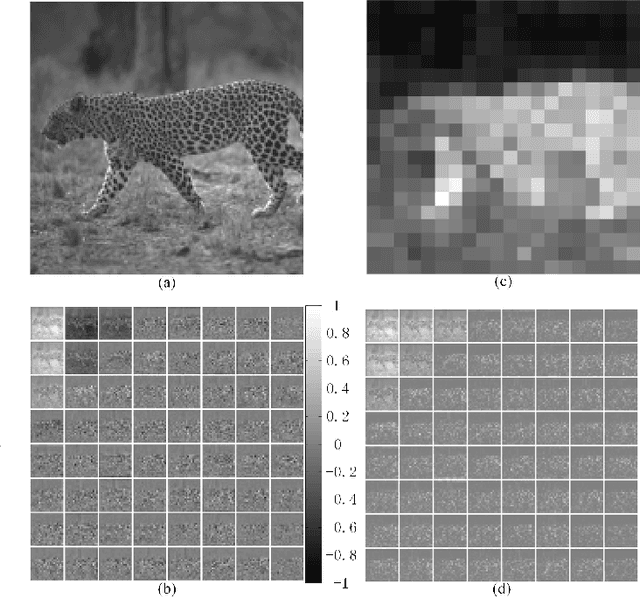
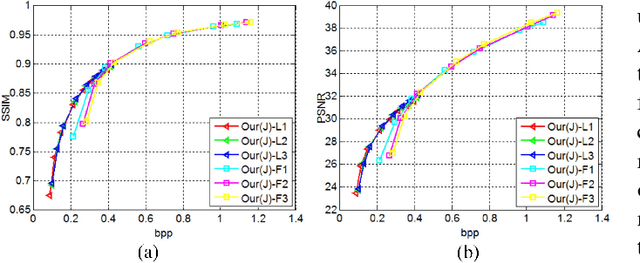
In this paper, we propose an image re-sampling compression method by learning virtual codec network (VCN) to resolve the non-differentiable problem of quantization function for image compression. Here, the image re-sampling not only refers to image full-resolution re-sampling but also low-resolution re-sampling. We generalize this method for standard-compliant image compression (SCIC) framework and deep neural networks based compression (DNNC) framework. Specifically, an input image is measured by re-sampling network (RSN) network to get re-sampled vectors. Then, these vectors are directly quantized in the feature space in SCIC, or discrete cosine transform coefficients of these vectors are quantized to further improve coding efficiency in DNNC. At the encoder, the quantized vectors or coefficients are losslessly compressed by arithmetic coding. At the receiver, the decoded vectors are utilized to restore input image by image decoder network (IDN). In order to train RSN network and IDN network together in an end-to-end fashion, our VCN network intimates projection from the re-sampled vectors to the IDN-decoded image. As a result, gradients from IDN network to RSN network can be approximated by VCN network's gradient. Because dimension reduction can be further achieved by quantization in some dimensional space after image re-sampling within auto-encoder architecture, we can well initialize our networks from pre-trained auto-encoder networks. Through extensive experiments and analysis, it is verified that the proposed method has more effectiveness and versatility than many state-of-the-art approaches.
Multiple Description Convolutional Neural Networks for Image Compression
Jan 20, 2018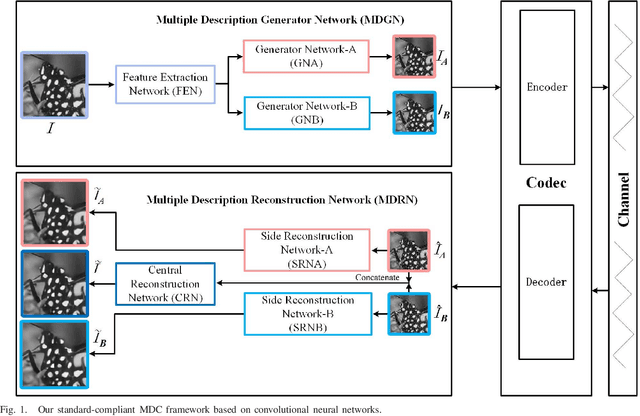



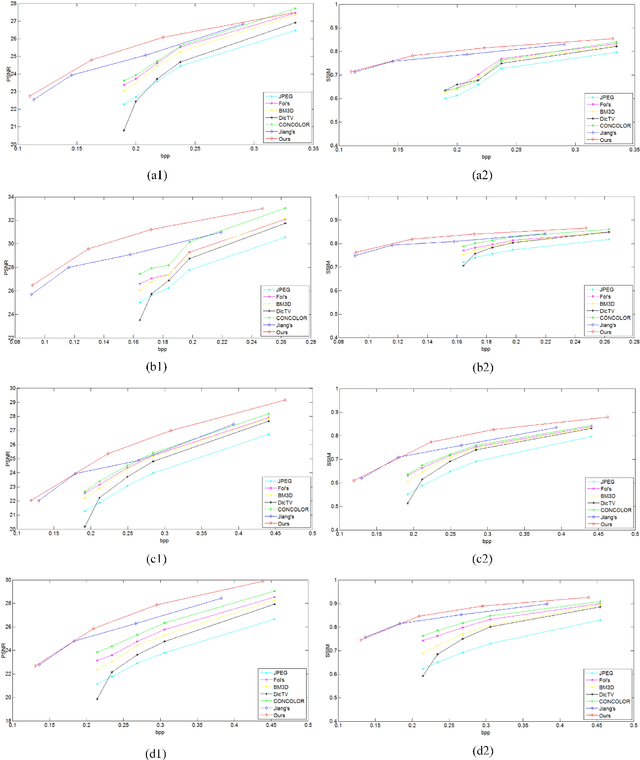
Multiple description coding (MDC) is able to stably transmit the signal in the un-reliable and non-prioritized networks, which has been broadly studied for several decades. However, the traditional MDC doesn't well leverage image's context features to generate multiple descriptions. In this paper, we propose a novel standard-compliant convolutional neural network-based MDC framework in term of image's context features. Firstly, multiple description generator network (MDGN) is designed to produce appearance-similar yet feature-different multiple descriptions automatically according to image's content, which are compressed by standard codec. Secondly, we present multiple description reconstruction network (MDRN) including side reconstruction network (SRN) and central reconstruction network (CRN). When any one of two lossy descriptions is received at the decoder, SRN network is used to improve the quality of this decoded lossy description by removing the compression artifact and up-sampling simultaneously. Meanwhile, we utilize CRN network with two decoded descriptions as inputs for better reconstruction, if both of lossy descriptions are available. Thirdly, multiple description virtual codec network (MDVCN) is proposed to bridge the gap between MDGN network and MDRN network in order to train an end-to-end MDC framework. Here, two learning algorithms are provided to train our whole framework. In addition to structural similarity loss function, the produced descriptions are used as opposing labels with multiple description distance loss function to regularize the training of MDGN network. These losses guarantee that the generated description images are structurally similar yet finely diverse. Experimental results show a great deal of objective and subjective quality measurements to validate the efficiency of the proposed method.
Learning a Virtual Codec Based on Deep Convolutional Neural Network to Compress Image
Jan 16, 2018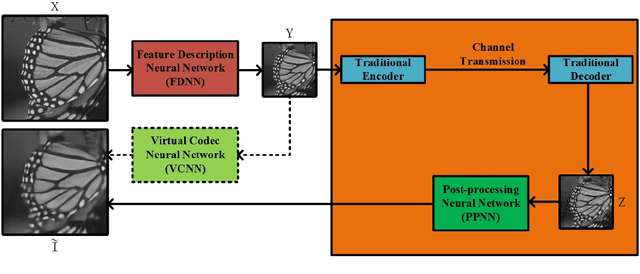
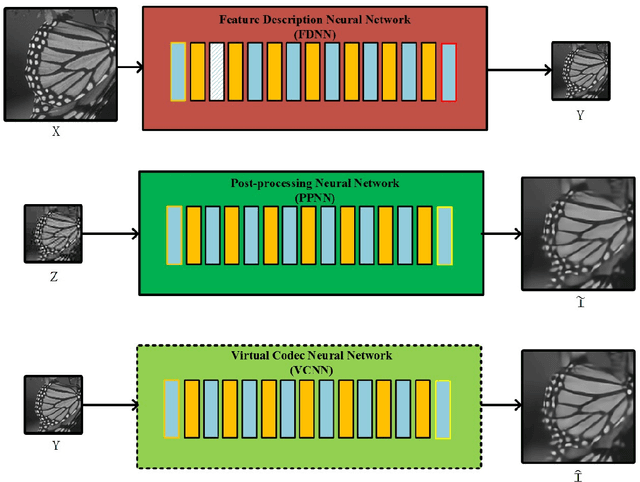

Although deep convolutional neural network has been proved to efficiently eliminate coding artifacts caused by the coarse quantization of traditional codec, it's difficult to train any neural network in front of the encoder for gradient's back-propagation. In this paper, we propose an end-to-end image compression framework based on convolutional neural network to resolve the problem of non-differentiability of the quantization function in the standard codec. First, the feature description neural network is used to get a valid description in the low-dimension space with respect to the ground-truth image so that the amount of image data is greatly reduced for storage or transmission. After image's valid description, standard image codec such as JPEG is leveraged to further compress image, which leads to image's great distortion and compression artifacts, especially blocking artifacts, detail missing, blurring, and ringing artifacts. Then, we use a post-processing neural network to remove these artifacts. Due to the challenge of directly learning a non-linear function for a standard codec based on convolutional neural network, we propose to learn a virtual codec neural network to approximate the projection from the valid description image to the post-processed compressed image, so that the gradient could be efficiently back-propagated from the post-processing neural network to the feature description neural network during training. Meanwhile, an advanced learning algorithm is proposed to train our deep neural networks for compression. Obviously, the priority of the proposed method is compatible with standard existing codecs and our learning strategy can be easily extended into these codecs based on convolutional neural network. Experimental results have demonstrated the advances of the proposed method as compared to several state-of-the-art approaches, especially at very low bit-rate.