 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixed-Resolution Image Representation and Compression with Convolutional Neural Networks
Paper and Code
Aug 01, 2018
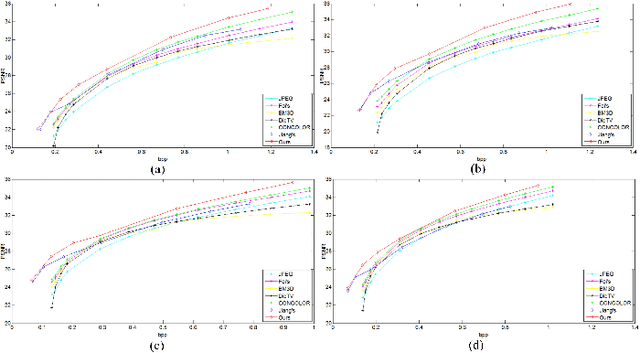
In this paper, we propose an end-to-end mixed-resolution image compression framework with convolutional neural networks. Firstly, given one input image, feature description neural network (FDNN) is used to generate a new representation of this image, so that this image representation can be more efficiently compressed by standard codec, as compared to the input image. Furthermore, we use post-processing neural network (PPNN) to remove the coding artifacts caused by quantization of codec. Secondly, low-resolution image representation is adopted for high efficiency compression in terms of most of bit spent by image's structures under low bit-rate. However, more bits should be assigned to image details in the high-resolution, when most of structures have been kept after compression at the high bit-rate. This comes from a fact that the low-resolution image representation can't burden more information than high-resolution representation beyond a certain bit-rate. Finally, to resolve the problem of error back-propagation from the PPNN network to the FDNN network, we introduce to learn a virtual codec neural network to imitate two continuous procedures of standard compression and post-processing. The objective experimental results have demonstrated the proposed method has a large margin improvement, when comparing with several state-of-the-art approaches.