 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-end translation of human neural activity to speech with a dual-dual generative adversarial network
Oct 13, 2021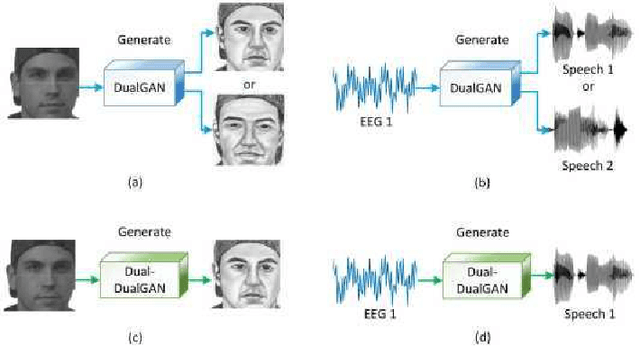
In a recent study of auditory evoked potential (AEP) based brain-computer interface (BCI), it was shown that, with an encoder-decoder framework, it is possible to translate human neural activity to speech (T-CAS). However, current encoder-decoder-based methods achieve T-CAS often with a two-step method where the information is passed between the encoder and decoder with a shared dimension reduction vector, which may result in a loss of information. A potential approach to this problem is to design an end-to-end method by using a dual generative adversarial network (DualGAN) without dimension reduction of passing information, but it cannot realize one-to-one signal-to-signal translation (see Fig.1 (a) and (b)). In this paper, we propose an end-to-end model to translate human neural activity to speech directly, create a new electroencephalogram (EEG) datasets for participants with good attention by design a device to detect participants' attention, and introduce a dual-dual generative adversarial network (Dual-DualGAN) (see Fig. 1 (c) and (d)) to address an end-to-end translation of human neural activity to speech (ET-CAS) problem by group labelling EEG signals and speech signals, inserting a transition domain to realize cross-domain mapping. In the transition domain, the transition signals are cascaded by the corresponding EEG and speech signals in a certain proportion, which can build bridges for EEG and speech signals without corresponding features, and realize one-to-one cross-domain EEG-to-speech translation. The proposed method can translate word-length and sentence-length sequences of neural activity to speech. Experimental evaluation has been conducted to show that the proposed method significantly outperforms state-of-the-art methods on both words and sentences of auditory stimulus.