 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiple Description Convolutional Neural Networks for Image Compression
Paper and Code
Jan 20, 2018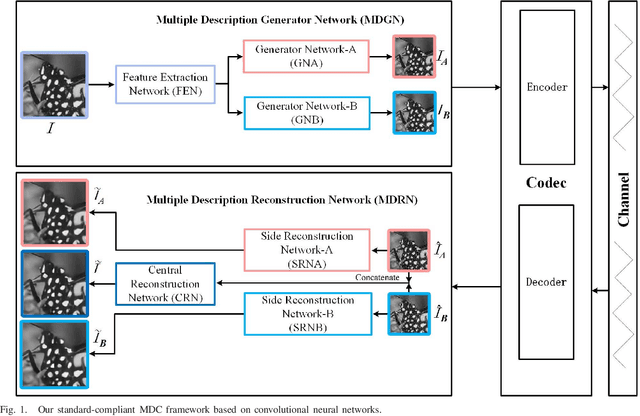



Multiple description coding (MDC) is able to stably transmit the signal in the un-reliable and non-prioritized networks, which has been broadly studied for several decades. However, the traditional MDC doesn't well leverage image's context features to generate multiple descriptions. In this paper, we propose a novel standard-compliant convolutional neural network-based MDC framework in term of image's context features. Firstly, multiple description generator network (MDGN) is designed to produce appearance-similar yet feature-different multiple descriptions automatically according to image's content, which are compressed by standard codec. Secondly, we present multiple description reconstruction network (MDRN) including side reconstruction network (SRN) and central reconstruction network (CRN). When any one of two lossy descriptions is received at the decoder, SRN network is used to improve the quality of this decoded lossy description by removing the compression artifact and up-sampling simultaneously. Meanwhile, we utilize CRN network with two decoded descriptions as inputs for better reconstruction, if both of lossy descriptions are available. Thirdly, multiple description virtual codec network (MDVCN) is proposed to bridge the gap between MDGN network and MDRN network in order to train an end-to-end MDC framework. Here, two learning algorithms are provided to train our whole framework. In addition to structural similarity loss function, the produced descriptions are used as opposing labels with multiple description distance loss function to regularize the training of MDGN network. These losses guarantee that the generated description images are structurally similar yet finely diverse. Experimental results show a great deal of objective and subjective quality measurements to validate the efficiency of the proposed method.