 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual-Label Learning With Irregularly Present Labels
Oct 21, 2024In multi-task learning, we often encounter the case when the presence of labels across samples exhibits irregular patterns: samples can be fully labeled, partially labeled or unlabeled. Taking drug analysis as an example, multiple toxicity properties of a drug molecule may not be concurrently available due to experimental limitations. It triggers a demand for a new training and inference mechanism that could accommodate irregularly present labels and maximize the utility of any available label information. In this work, we focus on the two-label learning task, and propose a novel training and inference framework, Dual-Label Learning (DLL). The DLL framework formulates the problem into a dual-function system, in which the two functions should simultaneously satisfy standard supervision, structural duality and probabilistic duality. DLL features a dual-tower model architecture that explicitly captures the information exchange between labels, aimed at maximizing the utility of partially available labels in understanding label correlation. During training, label imputation for missing labels is conducted as part of the forward propagation process, while during inference, labels are regarded as unknowns of a bivariate system of equations and are solved jointly. Theoretical analysis guarantees the feasibility of DLL, and extensive experiments are conducted to verify that by explicitly modeling label correlation and maximizing the utility of available labels, our method makes consistently better predictions than baseline approaches by up to a 10% gain in F1-score or MAPE. Remarkably, our method provided with data at a label missing rate as high as 60% can achieve similar or even better results than baseline approaches at a label missing rate of only 10%.
BlockEcho: Retaining Long-Range Dependencies for Imputing Block-Wise Missing Data
Feb 29, 2024Block-wise missing data poses significant challenges in real-world data imputation tasks. Compared to scattered missing data, block-wise gaps exacerbate adverse effects on subsequent analytic and machine learning tasks, as the lack of local neighboring elements significantly reduces the interpolation capability and predictive power. However, this issue has not received adequate attention. Most SOTA matrix completion methods appeared less effective, primarily due to overreliance on neighboring elements for predictions. We systematically analyze the issue and propose a novel matrix completion method ``BlockEcho" for a more comprehensive solution. This method creatively integrates Matrix Factorization (MF) within Generative Adversarial Networks (GAN) to explicitly retain long-distance inter-element relationships in the original matrix. Besides, we incorporate an additional discriminator for GAN, comparing the generator's intermediate progress with pre-trained MF results to constrain high-order feature distributions. Subsequently, we evaluate BlockEcho on public datasets across three domains. Results demonstrate superior performance over both traditional and SOTA methods when imputing block-wise missing data, especially at higher missing rates. The advantage also holds for scattered missing data at high missing rates. We also contribute on the analyses in providing theoretical justification on the optimality and convergence of fusing MF and GAN for missing block data.
Enhancing the "Immunity" of Mixture-of-Experts Networks for Adversarial Defense
Feb 29, 2024



Recent studies have revealed the vulnerability of Deep Neural Networks (DNNs) to adversarial examples, which can easily fool DNNs into making incorrect predictions. To mitigate this deficiency, we propose a novel adversarial defense method called "Immunity" (Innovative MoE with MUtual information \& positioN stabilITY) based on a modified Mixture-of-Experts (MoE) architecture in this work. The key enhancements to the standard MoE are two-fold: 1) integrating of Random Switch Gates (RSGs) to obtain diverse network structures via random permutation of RSG parameters at evaluation time, despite of RSGs being determined after one-time training; 2) devising innovative Mutual Information (MI)-based and Position Stability-based loss functions by capitalizing on Grad-CAM's explanatory power to increase the diversity and the causality of expert networks. Notably, our MI-based loss operates directly on the heatmaps, thereby inducing subtler negative impacts on the classification performance when compared to other losses of the same type, theoretically. Extensive evaluation validates the efficacy of the proposed approach in improving adversarial robustness against a wide range of attacks.
Discovering Support and Affiliated Features from Very High Dimensions
Jun 27, 2012
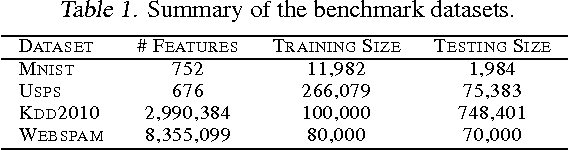
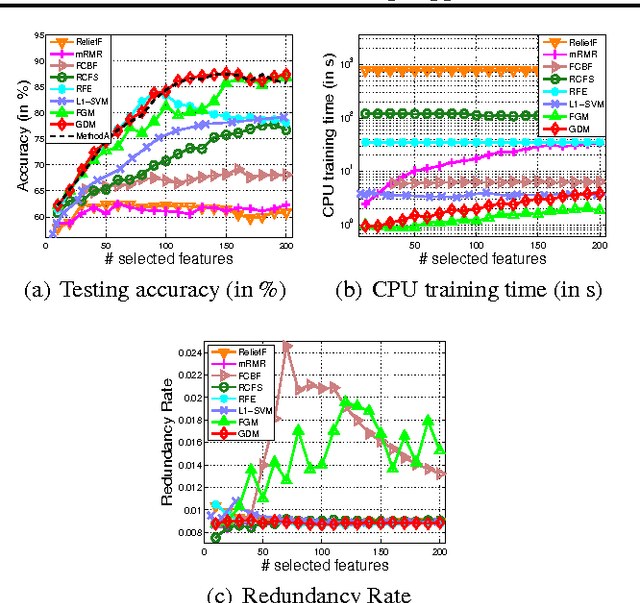
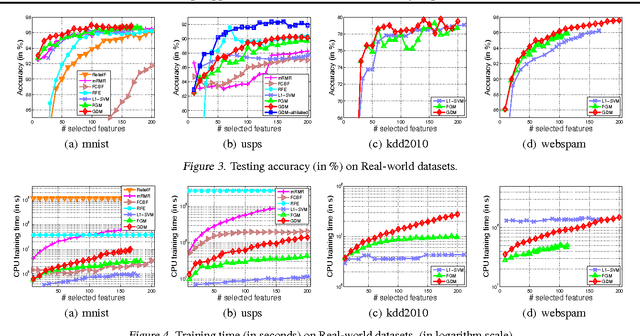
In this paper, a novel learning paradigm is presented to automatically identify groups of informative and correlated features from very high dimensions. Specifically, we explicitly incorporate correlation measures as constraints and then propose an efficient embedded feature selection method using recently developed cutting plane strategy. The benefits of the proposed algorithm are two-folds. First, it can identify the optimal discriminative and uncorrelated feature subset to the output labels, denoted here as Support Features, which brings about significant improvements in prediction performance over other state of the art feature selection methods considered in the paper. Second, during the learning process, the underlying group structures of correlated features associated with each support feature, denoted as Affiliated Features, can also be discovered without any additional cost. These affiliated features serve to improve the interpretations on the learning tasks. Extensive empirical studies on both synthetic and very high dimensional real-world datasets verify the validity and efficiency of the proposed method.