 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRelevance Feedback in Text-to-Image Diffusion: A Training-Free And Model-Agnostic Interactive Framework
Mar 16, 2026Text-to-image generation using diffusion models has achieved remarkable success. However, users often possess clear visual intents but struggle to express them precisely in language, resulting in ambiguous prompts and misaligned images. Existing methods struggle to bridge this gap, typically relying on high-load textual dialogues, opaque black-box inferences, or expensive fine-tuning. They fail to simultaneously achieve low cognitive load, interpretable preference inference, and remain training-free and model-agnostic. To address this, we propose RFD, an interactive framework that adapts the relevance feedback mechanism from information retrieval to diffusion models. In RFD, users replace explicit textual dialogue with implicit, multi-select visual feedback to minimize cognitive load, easily expressing complex, multi-dimensional preferences. To translate feedback into precise generative guidance, we construct an expert-curated feature repository and introduce an information-theoretic weighted cumulative preference analysis. This white-box method calculates preferences from current-round feedback and incrementally accumulates them, avoiding the concatenation of historical interactions and preventing inference degradation caused by lengthy contexts. Furthermore, RFD employs a probabilistic sampling mechanism for prompt reconstruction to balance exploitation and exploration, preventing output homogenization. Crucially, RFD operates entirely within the external text space, making it strictly training-free and model-agnostic as a universal plug-and-play solution. Extensive experiments demonstrate that RFD effectively captures the user's true visual intent, significantly outperforming baselines in preference alignment.
UniMatch: Universal Matching from Atom to Task for Few-Shot Drug Discovery
Feb 18, 2025Drug discovery is crucial for identifying candidate drugs for various diseases.However, its low success rate often results in a scarcity of annotations, posing a few-shot learning problem. Existing methods primarily focus on single-scale features, overlooking the hierarchical molecular structures that determine different molecular properties. To address these issues, we introduce Universal Matching Networks (UniMatch), a dual matching framework that integrates explicit hierarchical molecular matching with implicit task-level matching via meta-learning, bridging multi-level molecular representations and task-level generalization. Specifically, our approach explicitly captures structural features across multiple levels, such as atoms, substructures, and molecules, via hierarchical pooling and matching, facilitating precise molecular representation and comparison. Additionally, we employ a meta-learning strategy for implicit task-level matching, allowing the model to capture shared patterns across tasks and quickly adapt to new ones. This unified matching framework ensures effective molecular alignment while leveraging shared meta-knowledge for fast adaptation. Our experimental results demonstrate that UniMatch outperforms state-of-the-art methods on the MoleculeNet and FS-Mol benchmarks, achieving improvements of 2.87% in AUROC and 6.52% in delta AUPRC. UniMatch also shows excellent generalization ability on the Meta-MolNet benchmark.
Contextual Representation Anchor Network to Alleviate Selection Bias in Few-Shot Drug Discovery
Oct 29, 2024In the drug discovery process, the low success rate of drug candidate screening often leads to insufficient labeled data, causing the few-shot learning problem in molecular property prediction. Existing methods for few-shot molecular property prediction overlook the sample selection bias, which arises from non-random sample selection in chemical experiments. This bias in data representativeness leads to suboptimal performance. To overcome this challenge, we present a novel method named contextual representation anchor Network (CRA), where an anchor refers to a cluster center of the representations of molecules and serves as a bridge to transfer enriched contextual knowledge into molecular representations and enhance their expressiveness. CRA introduces a dual-augmentation mechanism that includes context augmentation, which dynamically retrieves analogous unlabeled molecules and captures their task-specific contextual knowledge to enhance the anchors, and anchor augmentation, which leverages the anchors to augment the molecular representations. We evaluate our approach on the MoleculeNet and FS-Mol benchmarks, as well as in domain transfer experiments. The results demonstrate that CRA outperforms the state-of-the-art by 2.60% and 3.28% in AUC and $\Delta$AUC-PR metrics, respectively, and exhibits superior generalization capabilities.
Dual-Label Learning With Irregularly Present Labels
Oct 21, 2024In multi-task learning, we often encounter the case when the presence of labels across samples exhibits irregular patterns: samples can be fully labeled, partially labeled or unlabeled. Taking drug analysis as an example, multiple toxicity properties of a drug molecule may not be concurrently available due to experimental limitations. It triggers a demand for a new training and inference mechanism that could accommodate irregularly present labels and maximize the utility of any available label information. In this work, we focus on the two-label learning task, and propose a novel training and inference framework, Dual-Label Learning (DLL). The DLL framework formulates the problem into a dual-function system, in which the two functions should simultaneously satisfy standard supervision, structural duality and probabilistic duality. DLL features a dual-tower model architecture that explicitly captures the information exchange between labels, aimed at maximizing the utility of partially available labels in understanding label correlation. During training, label imputation for missing labels is conducted as part of the forward propagation process, while during inference, labels are regarded as unknowns of a bivariate system of equations and are solved jointly. Theoretical analysis guarantees the feasibility of DLL, and extensive experiments are conducted to verify that by explicitly modeling label correlation and maximizing the utility of available labels, our method makes consistently better predictions than baseline approaches by up to a 10% gain in F1-score or MAPE. Remarkably, our method provided with data at a label missing rate as high as 60% can achieve similar or even better results than baseline approaches at a label missing rate of only 10%.
STS MICCAI 2023 Challenge: Grand challenge on 2D and 3D semi-supervised tooth segmentation
Jul 18, 2024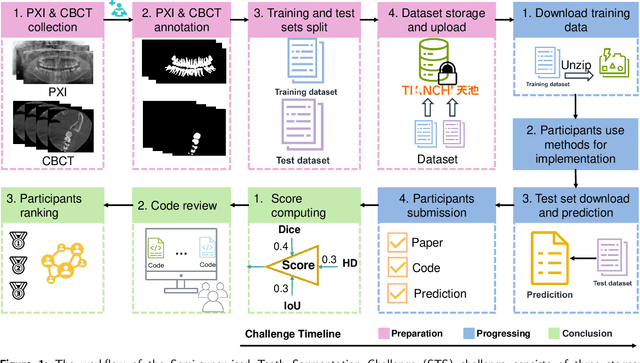
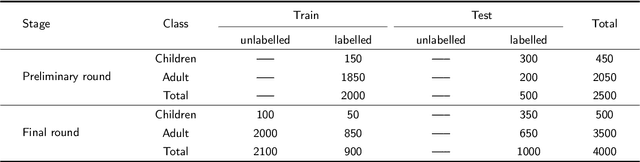

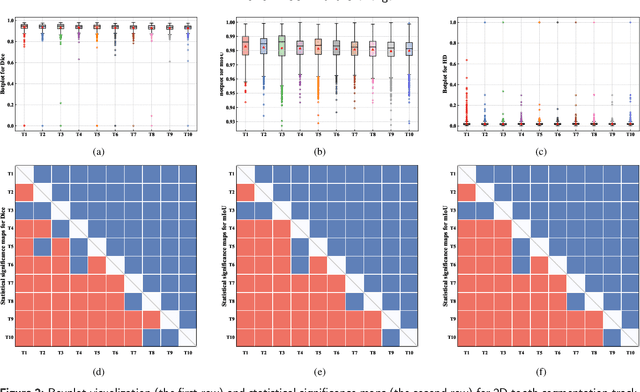
Computer-aided design (CAD) tools are increasingly popular in modern dental practice, particularly for treatment planning or comprehensive prognosis evaluation. In particular, the 2D panoramic X-ray image efficiently detects invisible caries, impacted teeth and supernumerary teeth in children, while the 3D dental cone beam computed tomography (CBCT) is widely used in orthodontics and endodontics due to its low radiation dose. However, there is no open-access 2D public dataset for children's teeth and no open 3D dental CBCT dataset, which limits the development of automatic algorithms for segmenting teeth and analyzing diseases. The Semi-supervised Teeth Segmentation (STS) Challenge, a pioneering event in tooth segmentation, was held as a part of the MICCAI 2023 ToothFairy Workshop on the Alibaba Tianchi platform. This challenge aims to investigate effective semi-supervised tooth segmentation algorithms to advance the field of dentistry. In this challenge, we provide two modalities including the 2D panoramic X-ray images and the 3D CBCT tooth volumes. In Task 1, the goal was to segment tooth regions in panoramic X-ray images of both adult and pediatric teeth. Task 2 involved segmenting tooth sections using CBCT volumes. Limited labelled images with mostly unlabelled ones were provided in this challenge prompt using semi-supervised algorithms for training. In the preliminary round, the challenge received registration and result submission by 434 teams, with 64 advancing to the final round. This paper summarizes the diverse methods employed by the top-ranking teams in the STS MICCAI 2023 Challenge.
Physical formula enhanced multi-task learning for pharmacokinetics prediction
Apr 16, 2024



Artificial intelligence (AI) technology has demonstrated remarkable potential in drug dis-covery, where pharmacokinetics plays a crucial role in determining the dosage, safety, and efficacy of new drugs. A major challenge for AI-driven drug discovery (AIDD) is the scarcity of high-quality data, which often requires extensive wet-lab work. A typical example of this is pharmacokinetic experiments. In this work, we develop a physical formula enhanced mul-ti-task learning (PEMAL) method that predicts four key parameters of pharmacokinetics simultaneously. By incorporating physical formulas into the multi-task framework, PEMAL facilitates effective knowledge sharing and target alignment among the pharmacokinetic parameters, thereby enhancing the accuracy of prediction. Our experiments reveal that PEMAL significantly lowers the data demand, compared to typical Graph Neural Networks. Moreover, we demonstrate that PEMAL enhances the robustness to noise, an advantage that conventional Neural Networks do not possess. Another advantage of PEMAL is its high flexibility, which can be potentially applied to other multi-task machine learning scenarios. Overall, our work illustrates the benefits and potential of using PEMAL in AIDD and other scenarios with data scarcity and noise.
BlockEcho: Retaining Long-Range Dependencies for Imputing Block-Wise Missing Data
Feb 29, 2024Block-wise missing data poses significant challenges in real-world data imputation tasks. Compared to scattered missing data, block-wise gaps exacerbate adverse effects on subsequent analytic and machine learning tasks, as the lack of local neighboring elements significantly reduces the interpolation capability and predictive power. However, this issue has not received adequate attention. Most SOTA matrix completion methods appeared less effective, primarily due to overreliance on neighboring elements for predictions. We systematically analyze the issue and propose a novel matrix completion method ``BlockEcho" for a more comprehensive solution. This method creatively integrates Matrix Factorization (MF) within Generative Adversarial Networks (GAN) to explicitly retain long-distance inter-element relationships in the original matrix. Besides, we incorporate an additional discriminator for GAN, comparing the generator's intermediate progress with pre-trained MF results to constrain high-order feature distributions. Subsequently, we evaluate BlockEcho on public datasets across three domains. Results demonstrate superior performance over both traditional and SOTA methods when imputing block-wise missing data, especially at higher missing rates. The advantage also holds for scattered missing data at high missing rates. We also contribute on the analyses in providing theoretical justification on the optimality and convergence of fusing MF and GAN for missing block data.