 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Do People Quantify Naturally: Evidence from Mandarin Picture Description
Feb 10, 2026Quantification is a fundamental component of everyday language use, yet little is known about how speakers decide whether and how to quantify in naturalistic production. We investigate quantification in Mandarin Chinese using a picture-based elicited description task in which speakers freely described scenes containing multiple objects, without explicit instructions to count or quantify. Across both spoken and written modalities, we examine three aspects of quantification: whether speakers choose to quantify at all, how precise their quantification is, and which quantificational strategies they adopt. Results show that object numerosity, animacy, and production modality systematically shape quantificational behaviour. In particular, increasing numerosity reduces both the likelihood and the precision of quantification, while animate referents and modality selectively modulate strategy choice. This study demonstrates how quantification can be examined under unconstrained production conditions and provides a naturalistic dataset for further analyses of quantity expression in language production.
Intrinsic Task-based Evaluation for Referring Expression Generation
Feb 12, 2024



Recently, a human evaluation study of Referring Expression Generation (REG) models had an unexpected conclusion: on \textsc{webnlg}, Referring Expressions (REs) generated by the state-of-the-art neural models were not only indistinguishable from the REs in \textsc{webnlg} but also from the REs generated by a simple rule-based system. Here, we argue that this limitation could stem from the use of a purely ratings-based human evaluation (which is a common practice in Natural Language Generation). To investigate these issues, we propose an intrinsic task-based evaluation for REG models, in which, in addition to rating the quality of REs, participants were asked to accomplish two meta-level tasks. One of these tasks concerns the referential success of each RE; the other task asks participants to suggest a better alternative for each RE. The outcomes suggest that, in comparison to previous evaluations, the new evaluation protocol assesses the performance of each REG model more comprehensively and makes the participants' ratings more reliable and discriminable.
Models of reference production: How do they withstand the test of time?
Jul 27, 2023



In recent years, many NLP studies have focused solely on performance improvement. In this work, we focus on the linguistic and scientific aspects of NLP. We use the task of generating referring expressions in context (REG-in-context) as a case study and start our analysis from GREC, a comprehensive set of shared tasks in English that addressed this topic over a decade ago. We ask what the performance of models would be if we assessed them (1) on more realistic datasets, and (2) using more advanced methods. We test the models using different evaluation metrics and feature selection experiments. We conclude that GREC can no longer be regarded as offering a reliable assessment of models' ability to mimic human reference production, because the results are highly impacted by the choice of corpus and evaluation metrics. Our results also suggest that pre-trained language models are less dependent on the choice of corpus than classic Machine Learning models, and therefore make more robust class predictions.
Assessing Neural Referential Form Selectors on a Realistic Multilingual Dataset
Oct 11, 2022
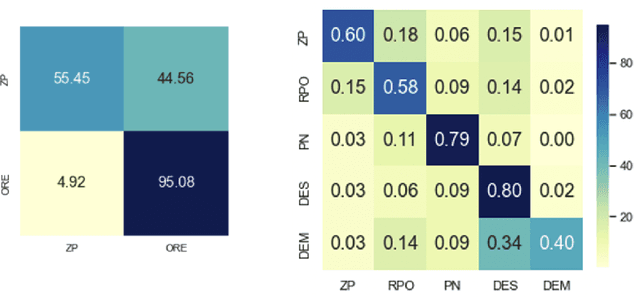
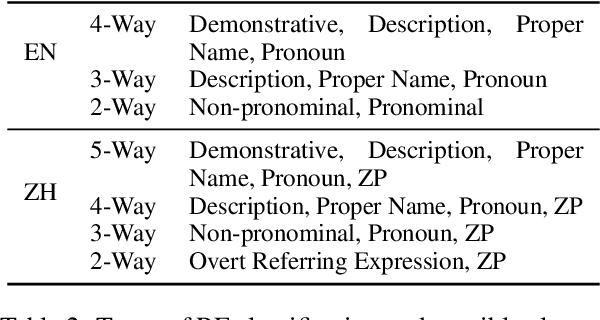
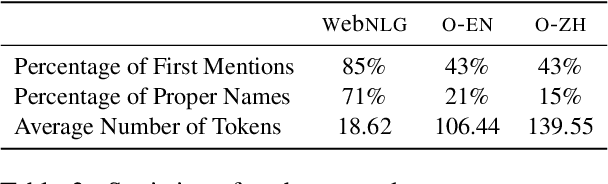
Previous work on Neural Referring Expression Generation (REG) all uses WebNLG, an English dataset that has been shown to reflect a very limited range of referring expression (RE) use. To tackle this issue, we build a dataset based on the OntoNotes corpus that contains a broader range of RE use in both English and Chinese (a language that uses zero pronouns). We build neural Referential Form Selection (RFS) models accordingly, assess them on the dataset and conduct probing experiments. The experiments suggest that, compared to WebNLG, OntoNotes is better for assessing REG/RFS models. We compare English and Chinese RFS and confirm that, in line with linguistic theories, Chinese RFS depends more on discourse context than English.
Non-neural Models Matter: A Re-evaluation of Neural Referring Expression Generation Systems
Mar 15, 2022
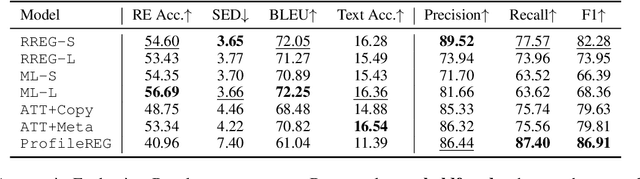
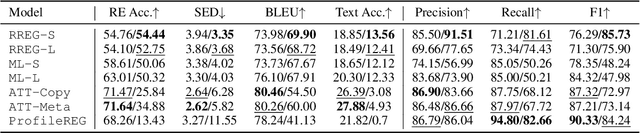
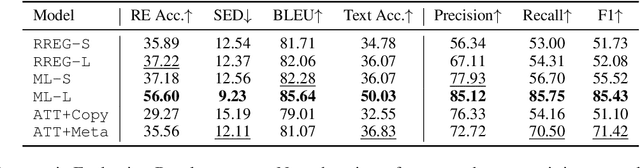
In recent years, neural models have often outperformed rule-based and classic Machine Learning approaches in NLG. These classic approaches are now often disregarded, for example when new neural models are evaluated. We argue that they should not be overlooked, since, for some tasks, well-designed non-neural approaches achieve better performance than neural ones. In this paper, the task of generating referring expressions in linguistic context is used as an example. We examined two very different English datasets (WEBNLG and WSJ), and evaluated each algorithm using both automatic and human evaluations. Overall, the results of these evaluations suggest that rule-based systems with simple rule sets achieve on-par or better performance on both datasets compared to state-of-the-art neural REG systems. In the case of the more realistic dataset, WSJ, a machine learning-based system with well-designed linguistic features performed best. We hope that our work can encourage researchers to consider non-neural models in future.
What can Neural Referential Form Selectors Learn?
Aug 15, 2021
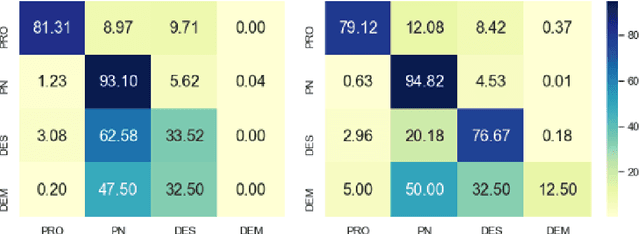

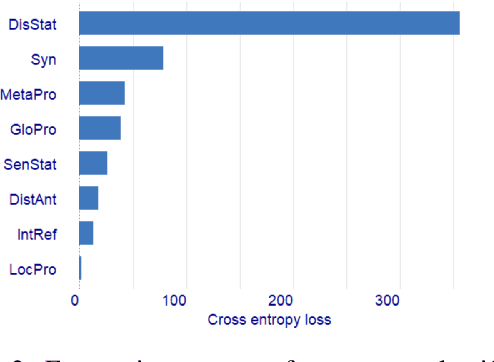
Despite achieving encouraging results, neural Referring Expression Generation models are often thought to lack transparency. We probed neural Referential Form Selection (RFS) models to find out to what extent the linguistic features influencing the RE form are learnt and captured by state-of-the-art RFS models. The results of 8 probing tasks show that all the defined features were learnt to some extent. The probing tasks pertaining to referential status and syntactic position exhibited the highest performance. The lowest performance was achieved by the probing models designed to predict discourse structure properties beyond the sentence level.