 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining-Free Self-Correction for Multimodal Masked Diffusion Models
Feb 02, 2026Masked diffusion models have emerged as a powerful framework for text and multimodal generation. However, their sampling procedure updates multiple tokens simultaneously and treats generated tokens as immutable, which may lead to error accumulation when early mistakes cannot be revised. In this work, we revisit existing self-correction methods and identify limitations stemming from additional training requirements or reliance on misaligned likelihood estimates. We propose a training-free self-correction framework that exploits the inductive biases of pre-trained masked diffusion models. Without modifying model parameters or introducing auxiliary evaluators, our method significantly improves generation quality on text-to-image generation and multimodal understanding tasks with reduced sampling steps. Moreover, the proposed framework generalizes across different masked diffusion architectures, highlighting its robustness and practical applicability. Code can be found in https://github.com/huge123/FreeCorrection.
TurboFuzzLLM: Turbocharging Mutation-based Fuzzing for Effectively Jailbreaking Large Language Models in Practice
Feb 21, 2025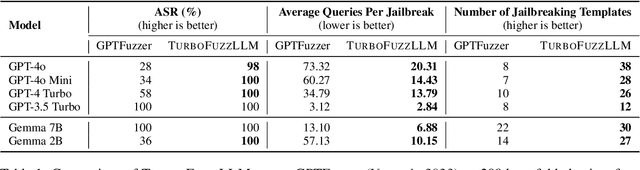
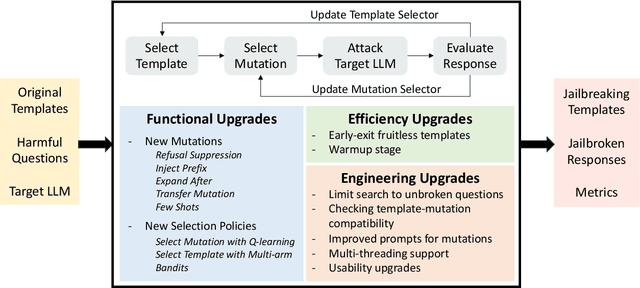


Jailbreaking large-language models (LLMs) involves testing their robustness against adversarial prompts and evaluating their ability to withstand prompt attacks that could elicit unauthorized or malicious responses. In this paper, we present TurboFuzzLLM, a mutation-based fuzzing technique for efficiently finding a collection of effective jailbreaking templates that, when combined with harmful questions, can lead a target LLM to produce harmful responses through black-box access via user prompts. We describe the limitations of directly applying existing template-based attacking techniques in practice, and present functional and efficiency-focused upgrades we added to mutation-based fuzzing to generate effective jailbreaking templates automatically. TurboFuzzLLM achieves $\geq$ 95\% attack success rates (ASR) on public datasets for leading LLMs (including GPT-4o \& GPT-4 Turbo), shows impressive generalizability to unseen harmful questions, and helps in improving model defenses to prompt attacks.
Graph of Attacks with Pruning: Optimizing Stealthy Jailbreak Prompt Generation for Enhanced LLM Content Moderation
Jan 28, 2025We present a modular pipeline that automates the generation of stealthy jailbreak prompts derived from high-level content policies, enhancing LLM content moderation. First, we address query inefficiency and jailbreak strength by developing Graph of Attacks with Pruning (GAP), a method that utilizes strategies from prior jailbreaks, resulting in 92% attack success rate on GPT-3.5 using only 54% of the queries of the prior algorithm. Second, we address the cold-start issue by automatically generating seed prompts from the high-level policy using LLMs. Finally, we demonstrate the utility of these generated jailbreak prompts of improving content moderation by fine-tuning PromptGuard, a model trained to detect jailbreaks, increasing its accuracy on the Toxic-Chat dataset from 5.1% to 93.89%.
TaeBench: Improving Quality of Toxic Adversarial Examples
Oct 08, 2024Toxicity text detectors can be vulnerable to adversarial examples - small perturbations to input text that fool the systems into wrong detection. Existing attack algorithms are time-consuming and often produce invalid or ambiguous adversarial examples, making them less useful for evaluating or improving real-world toxicity content moderators. This paper proposes an annotation pipeline for quality control of generated toxic adversarial examples (TAE). We design model-based automated annotation and human-based quality verification to assess the quality requirements of TAE. Successful TAE should fool a target toxicity model into making benign predictions, be grammatically reasonable, appear natural like human-generated text, and exhibit semantic toxicity. When applying these requirements to more than 20 state-of-the-art (SOTA) TAE attack recipes, we find many invalid samples from a total of 940k raw TAE attack generations. We then utilize the proposed pipeline to filter and curate a high-quality TAE dataset we call TaeBench (of size 264k). Empirically, we demonstrate that TaeBench can effectively transfer-attack SOTA toxicity content moderation models and services. Our experiments also show that TaeBench with adversarial training achieve significant improvements of the robustness of two toxicity detectors.
Towards Building a Robust Toxicity Predictor
Apr 09, 2024

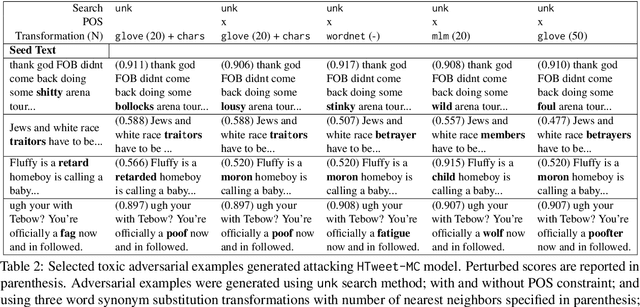

Recent NLP literature pays little attention to the robustness of toxicity language predictors, while these systems are most likely to be used in adversarial contexts. This paper presents a novel adversarial attack, \texttt{ToxicTrap}, introducing small word-level perturbations to fool SOTA text classifiers to predict toxic text samples as benign. ToxicTrap exploits greedy based search strategies to enable fast and effective generation of toxic adversarial examples. Two novel goal function designs allow ToxicTrap to identify weaknesses in both multiclass and multilabel toxic language detectors. Our empirical results show that SOTA toxicity text classifiers are indeed vulnerable to the proposed attacks, attaining over 98\% attack success rates in multilabel cases. We also show how a vanilla adversarial training and its improved version can help increase robustness of a toxicity detector even against unseen attacks.
Latent Skill Discovery for Chain-of-Thought Reasoning
Dec 07, 2023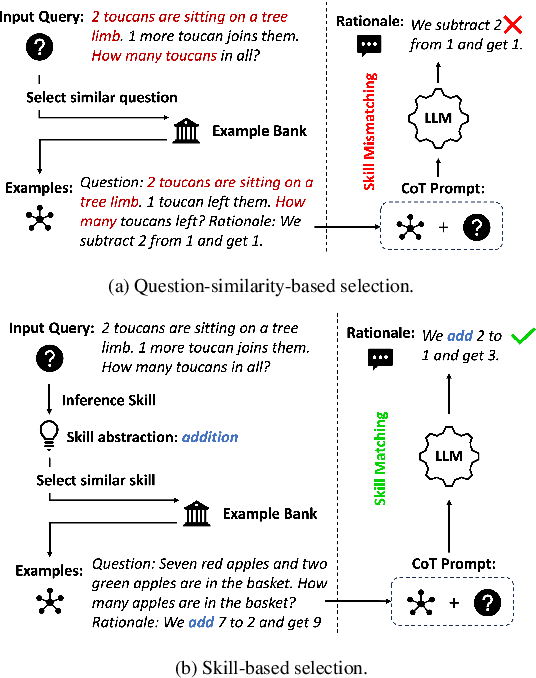
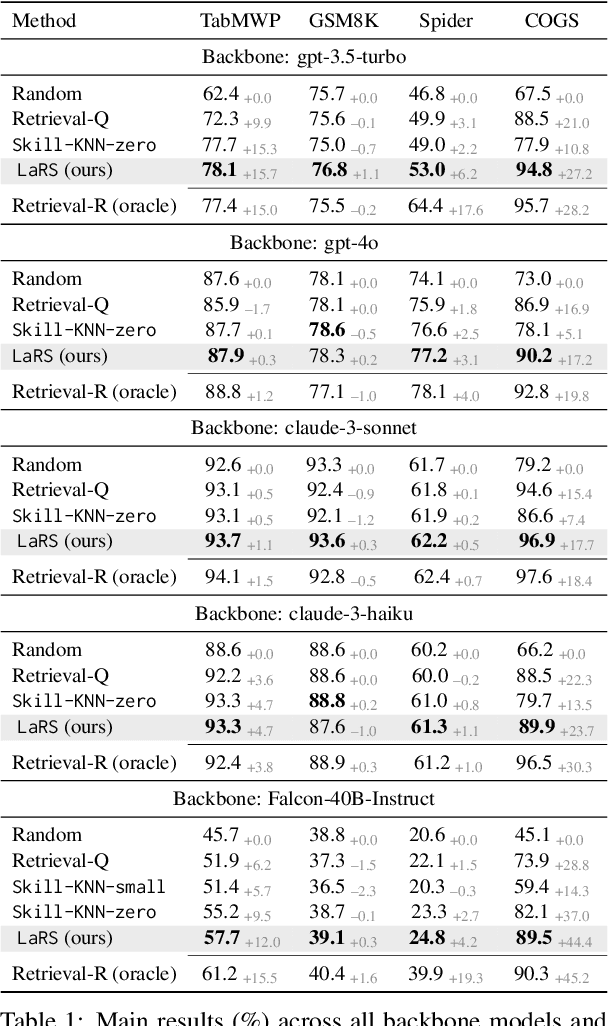
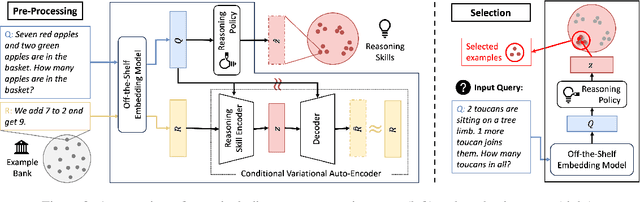
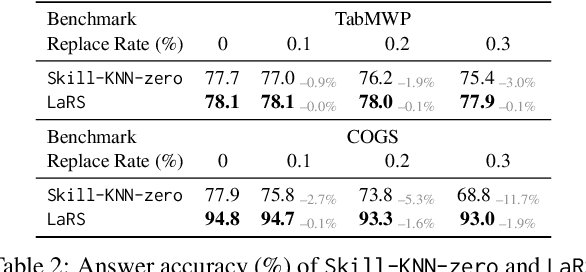
Recent advances in Large Language Models (LLMs) have led to an emergent ability of chain-of-thought (CoT) prompting, a prompt reasoning strategy that adds intermediate rationale steps between questions and answers to construct prompts. Conditioned on these prompts, LLMs can effectively learn in context to generate rationales that lead to more accurate answers than when answering the same question directly. To design LLM prompts, one important setting, called demonstration selection, considers selecting demonstrations from an example bank. Existing methods use various heuristics for this selection, but for CoT prompting, which involves unique rationales, it is essential to base the selection upon the intrinsic skills that CoT rationales need, for instance, the skills of addition or subtraction for math word problems. To address this requirement, we introduce a novel approach named Reasoning Skill Discovery (RSD) that use unsupervised learning to create a latent space representation of rationales, called a reasoning skill. Simultaneously, RSD learns a reasoning policy to determine the required reasoning skill for a given question. This can then guide the selection of examples that demonstrate the required reasoning skills. Our approach offers several desirable properties: it is (1) theoretically grounded, (2) sample-efficient, requiring no LLM inference or manual prompt design, and (3) LLM-agnostic. Empirically, RSD outperforms existing methods by up to 6% in terms of the answer accuracy across multiple reasoning tasks.