 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
RESTRAIN: From Spurious Votes to Signals -- Self-Driven RL with Self-Penalization
Oct 02, 2025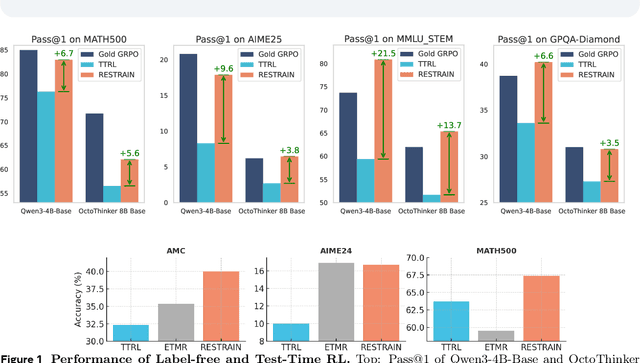
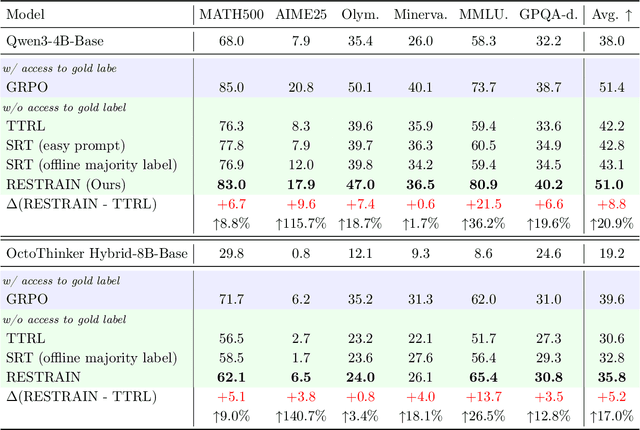
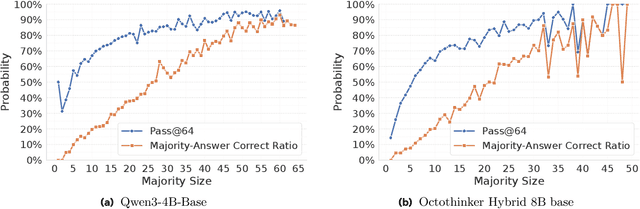
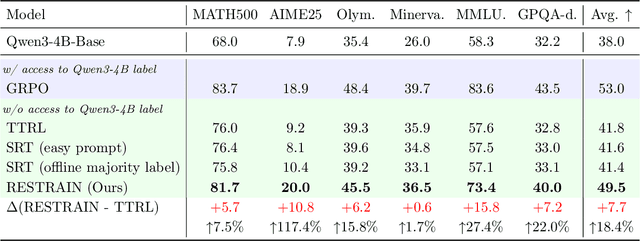
Reinforcement learning with human-annotated data has boosted chain-of-thought reasoning in large reasoning models, but these gains come at high costs in labeled data while faltering on harder tasks. A natural next step is experience-driven learning, where models improve without curated labels by adapting to unlabeled data. We introduce RESTRAIN (REinforcement learning with Self-restraint), a self-penalizing RL framework that converts the absence of gold labels into a useful learning signal. Instead of overcommitting to spurious majority votes, RESTRAIN exploits signals from the model's entire answer distribution: penalizing overconfident rollouts and low-consistency examples while preserving promising reasoning chains. The self-penalization mechanism integrates seamlessly into policy optimization methods such as GRPO, enabling continual self-improvement without supervision. On challenging reasoning benchmarks, RESTRAIN delivers large gains using only unlabeled data. With Qwen3-4B-Base and OctoThinker Hybrid-8B-Base, it improves Pass@1 by up to +140.7 percent on AIME25, +36.2 percent on MMLU_STEM, and +19.6 percent on GPQA-Diamond, nearly matching gold-label training while using no gold labels. These results demonstrate that RESTRAIN establishes a scalable path toward stronger reasoning without gold labels.
Collaborative LLM Numerical Reasoning with Local Data Protection
Apr 01, 2025Numerical reasoning over documents, which demands both contextual understanding and logical inference, is challenging for low-capacity local models deployed on computation-constrained devices. Although such complex reasoning queries could be routed to powerful remote models like GPT-4, exposing local data raises significant data leakage concerns. Existing mitigation methods generate problem descriptions or examples for remote assistance. However, the inherent complexity of numerical reasoning hinders the local model from generating logically equivalent queries and accurately inferring answers with remote guidance. In this paper, we present a model collaboration framework with two key innovations: (1) a context-aware synthesis strategy that shifts the query domains while preserving logical consistency; and (2) a tool-based answer reconstruction approach that reuses the remote-generated problem-solving pattern with code snippets. Experimental results demonstrate that our method achieves better reasoning accuracy than solely using local models while providing stronger data protection than fully relying on remote models. Furthermore, our method improves accuracy by 16.2% - 43.6% while reducing data leakage by 2.3% - 44.6% compared to existing data protection approaches.
A Systematic Survey of Automatic Prompt Optimization Techniques
Feb 24, 2025Since the advent of large language models (LLMs), prompt engineering has been a crucial step for eliciting desired responses for various Natural Language Processing (NLP) tasks. However, prompt engineering remains an impediment for end users due to rapid advances in models, tasks, and associated best practices. To mitigate this, Automatic Prompt Optimization (APO) techniques have recently emerged that use various automated techniques to help improve the performance of LLMs on various tasks. In this paper, we present a comprehensive survey summarizing the current progress and remaining challenges in this field. We provide a formal definition of APO, a 5-part unifying framework, and then proceed to rigorously categorize all relevant works based on their salient features therein. We hope to spur further research guided by our framework.
Hierarchical Prompt Decision Transformer: Improving Few-Shot Policy Generalization with Global and Adaptive
Dec 01, 2024



Decision transformers recast reinforcement learning as a conditional sequence generation problem, offering a simple but effective alternative to traditional value or policy-based methods. A recent key development in this area is the integration of prompting in decision transformers to facilitate few-shot policy generalization. However, current methods mainly use static prompt segments to guide rollouts, limiting their ability to provide context-specific guidance. Addressing this, we introduce a hierarchical prompting approach enabled by retrieval augmentation. Our method learns two layers of soft tokens as guiding prompts: (1) global tokens encapsulating task-level information about trajectories, and (2) adaptive tokens that deliver focused, timestep-specific instructions. The adaptive tokens are dynamically retrieved from a curated set of demonstration segments, ensuring context-aware guidance. Experiments across seven benchmark tasks in the MuJoCo and MetaWorld environments demonstrate the proposed approach consistently outperforms all baseline methods, suggesting that hierarchical prompting for decision transformers is an effective strategy to enable few-shot policy generalization.
Latent Skill Discovery for Chain-of-Thought Reasoning
Dec 07, 2023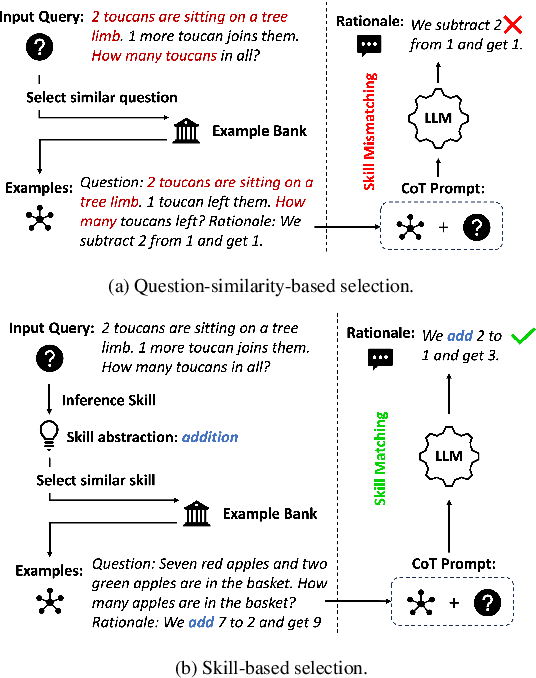
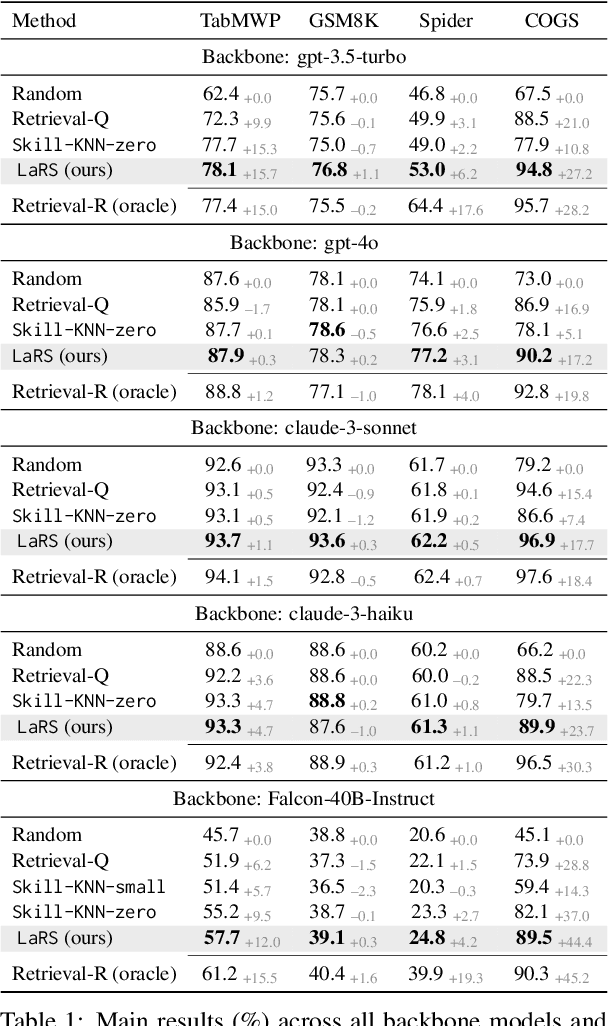
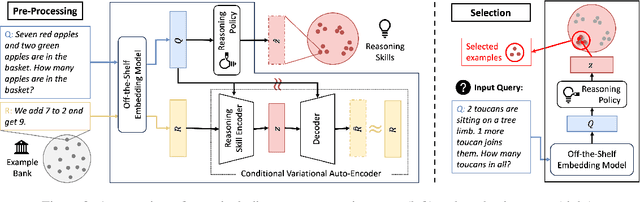
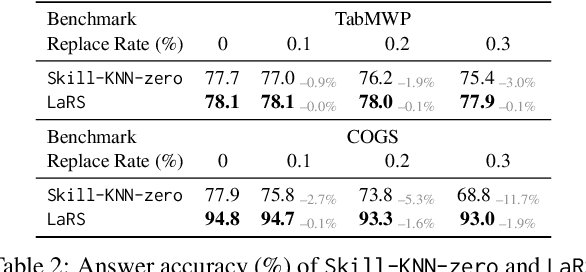
Recent advances in Large Language Models (LLMs) have led to an emergent ability of chain-of-thought (CoT) prompting, a prompt reasoning strategy that adds intermediate rationale steps between questions and answers to construct prompts. Conditioned on these prompts, LLMs can effectively learn in context to generate rationales that lead to more accurate answers than when answering the same question directly. To design LLM prompts, one important setting, called demonstration selection, considers selecting demonstrations from an example bank. Existing methods use various heuristics for this selection, but for CoT prompting, which involves unique rationales, it is essential to base the selection upon the intrinsic skills that CoT rationales need, for instance, the skills of addition or subtraction for math word problems. To address this requirement, we introduce a novel approach named Reasoning Skill Discovery (RSD) that use unsupervised learning to create a latent space representation of rationales, called a reasoning skill. Simultaneously, RSD learns a reasoning policy to determine the required reasoning skill for a given question. This can then guide the selection of examples that demonstrate the required reasoning skills. Our approach offers several desirable properties: it is (1) theoretically grounded, (2) sample-efficient, requiring no LLM inference or manual prompt design, and (3) LLM-agnostic. Empirically, RSD outperforms existing methods by up to 6% in terms of the answer accuracy across multiple reasoning tasks.
A Review of Reinforcement Learning for Natural Language Processing, and Applications in Healthcare
Oct 23, 2023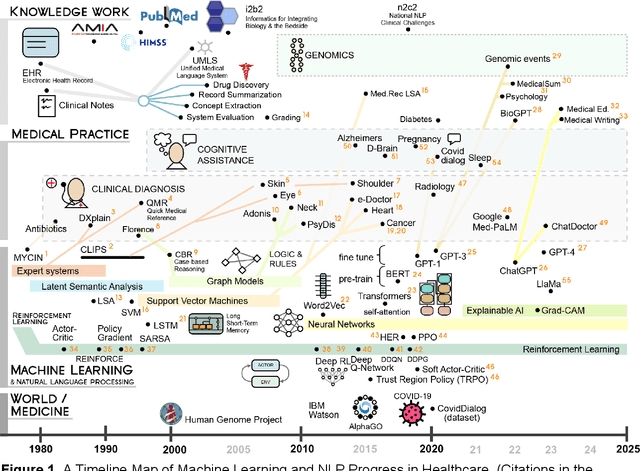

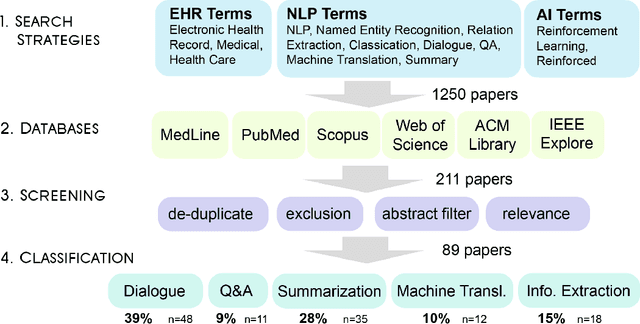
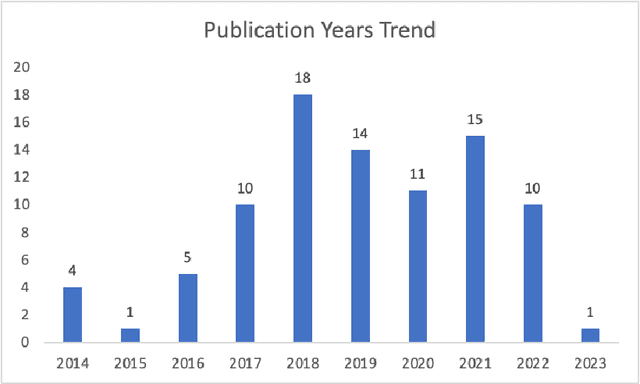
Reinforcement learning (RL) has emerged as a powerful approach for tackling complex medical decision-making problems such as treatment planning, personalized medicine, and optimizing the scheduling of surgeries and appointments. It has gained significant attention in the field of Natural Language Processing (NLP) due to its ability to learn optimal strategies for tasks such as dialogue systems, machine translation, and question-answering. This paper presents a review of the RL techniques in NLP, highlighting key advancements, challenges, and applications in healthcare. The review begins by visualizing a roadmap of machine learning and its applications in healthcare. And then it explores the integration of RL with NLP tasks. We examined dialogue systems where RL enables the learning of conversational strategies, RL-based machine translation models, question-answering systems, text summarization, and information extraction. Additionally, ethical considerations and biases in RL-NLP systems are addressed.
Graph Neural Prompting with Large Language Models
Sep 27, 2023
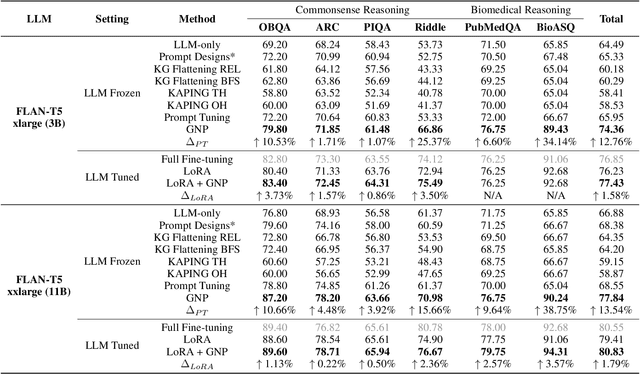
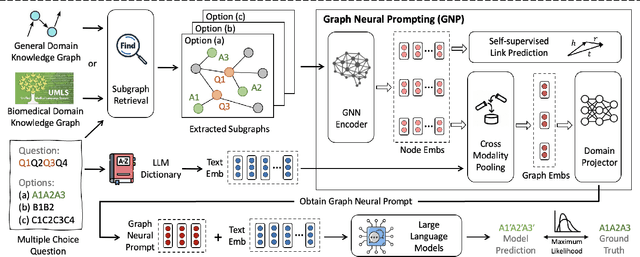
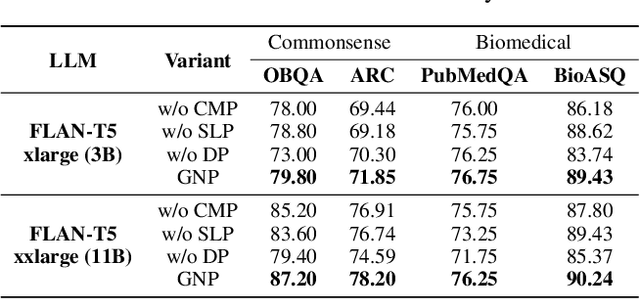
Large Language Models (LLMs) have shown remarkable generalization capability with exceptional performance in various language modeling tasks. However, they still exhibit inherent limitations in precisely capturing and returning grounded knowledge. While existing work has explored utilizing knowledge graphs to enhance language modeling via joint training and customized model architectures, applying this to LLMs is problematic owing to their large number of parameters and high computational cost. In addition, how to leverage the pre-trained LLMs and avoid training a customized model from scratch remains an open question. In this work, we propose Graph Neural Prompting (GNP), a novel plug-and-play method to assist pre-trained LLMs in learning beneficial knowledge from KGs. GNP encompasses various designs, including a standard graph neural network encoder, a cross-modality pooling module, a domain projector, and a self-supervised link prediction objective. Extensive experiments on multiple datasets demonstrate the superiority of GNP on both commonsense and biomedical reasoning tasks across different LLM sizes and settings.
OL-Transformer: A Fast and Universal Surrogate Simulator for Optical Multilayer Thin Film Structures
May 19, 2023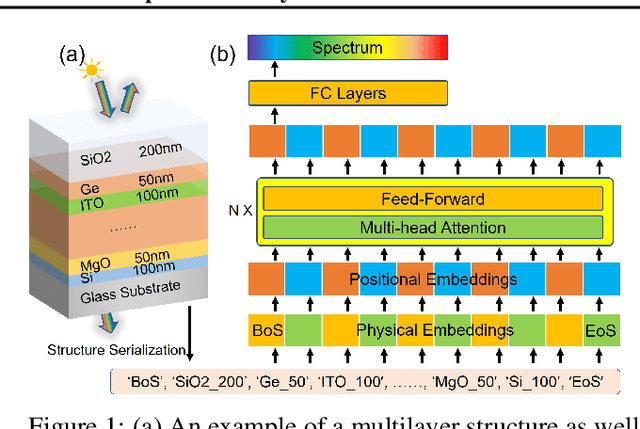

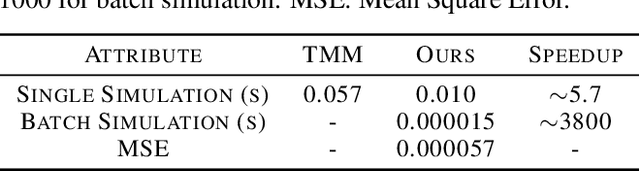
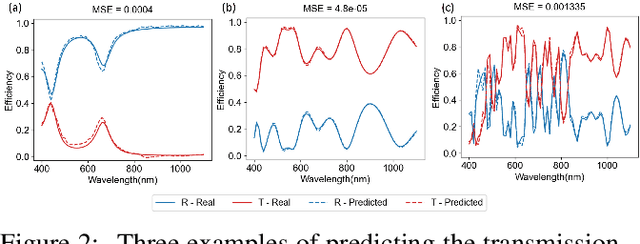
Deep learning-based methods have recently been established as fast and accurate surrogate simulators for optical multilayer thin film structures. However, existing methods only work for limited types of structures with different material arrangements, preventing their applications towards diverse and universal structures. Here, we propose the Opto-Layer (OL) Transformer to act as a universal surrogate simulator for enormous types of structures. Combined with the technique of structure serialization, our model can predict accurate reflection and transmission spectra for up to $10^{25}$ different multilayer structures, while still achieving a six-fold time speedup compared to physical solvers. Further investigation reveals that the general learning ability comes from the fact that our model first learns the physical embeddings and then uses the self-attention mechanism to capture the hidden relationship of light-matter interaction between each layer.
OptoGPT: A Foundation Model for Inverse Design in Optical Multilayer Thin Film Structures
Apr 20, 2023Foundation models are large machine learning models that can tackle various downstream tasks once trained on diverse and large-scale data, leading research trends in natural language processing, computer vision, and reinforcement learning. However, no foundation model exists for optical multilayer thin film structure inverse design. Current inverse design algorithms either fail to explore the global design space or suffer from low computational efficiency. To bridge this gap, we propose the Opto Generative Pretrained Transformer (OptoGPT). OptoGPT is a decoder-only transformer that auto-regressively generates designs based on specific spectrum targets. Trained on a large dataset of 10 million designs, our model demonstrates remarkable capabilities: 1) autonomous global design exploration by determining the number of layers (up to 20) while selecting the material (up to 18 distinct types) and thickness at each layer, 2) efficient designs for structural color, absorbers, filters, distributed brag reflectors, and Fabry-Perot resonators within 0.1 seconds (comparable to simulation speeds), 3) the ability to output diverse designs, and 4) seamless integration of user-defined constraints. By overcoming design barriers regarding optical targets, material selections, and design constraints, OptoGPT can serve as a foundation model for optical multilayer thin film structure inverse design.