 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMind the Performance Gap: Examining Dataset Shift During Prospective Validation
Jul 23, 2021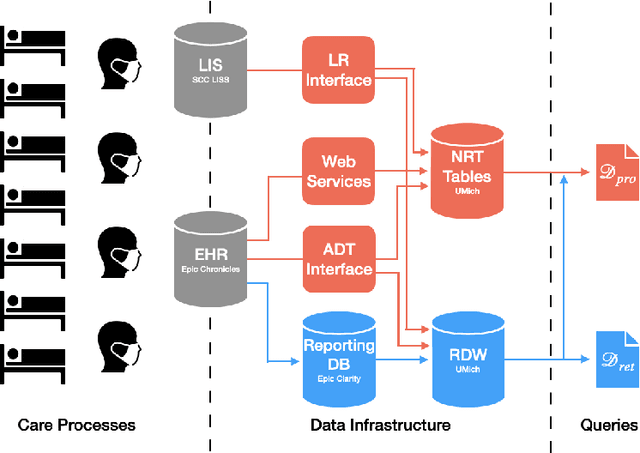
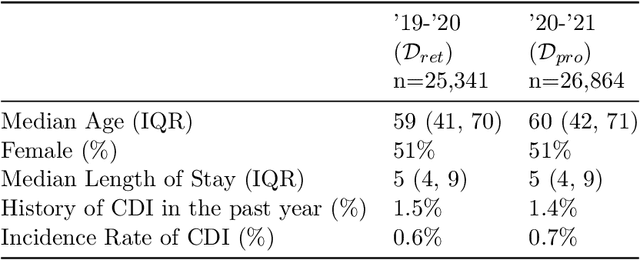
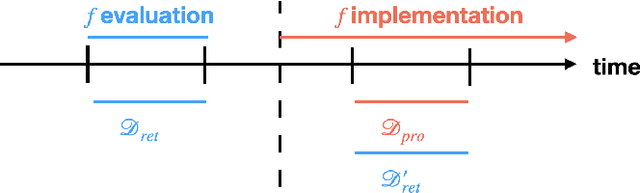

Once integrated into clinical care, patient risk stratification models may perform worse compared to their retrospective performance. To date, it is widely accepted that performance will degrade over time due to changes in care processes and patient populations. However, the extent to which this occurs is poorly understood, in part because few researchers report prospective validation performance. In this study, we compare the 2020-2021 ('20-'21) prospective performance of a patient risk stratification model for predicting healthcare-associated infections to a 2019-2020 ('19-'20) retrospective validation of the same model. We define the difference in retrospective and prospective performance as the performance gap. We estimate how i) "temporal shift", i.e., changes in clinical workflows and patient populations, and ii) "infrastructure shift", i.e., changes in access, extraction and transformation of data, both contribute to the performance gap. Applied prospectively to 26,864 hospital encounters during a twelve-month period from July 2020 to June 2021, the model achieved an area under the receiver operating characteristic curve (AUROC) of 0.767 (95% confidence interval (CI): 0.737, 0.801) and a Brier score of 0.189 (95% CI: 0.186, 0.191). Prospective performance decreased slightly compared to '19-'20 retrospective performance, in which the model achieved an AUROC of 0.778 (95% CI: 0.744, 0.815) and a Brier score of 0.163 (95% CI: 0.161, 0.165). The resulting performance gap was primarily due to infrastructure shift and not temporal shift. So long as we continue to develop and validate models using data stored in large research data warehouses, we must consider differences in how and when data are accessed, measure how these differences may affect prospective performance, and work to mitigate those differences.
Relaxed Weight Sharing: Effectively Modeling Time-Varying Relationships in Clinical Time-Series
Jun 07, 2019
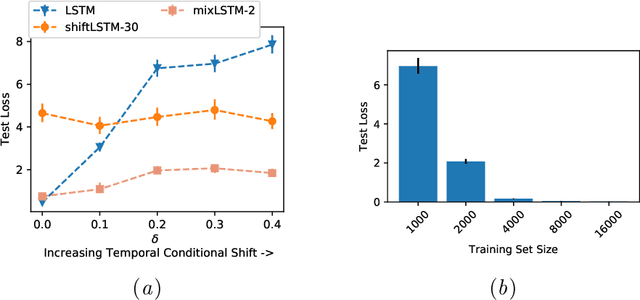
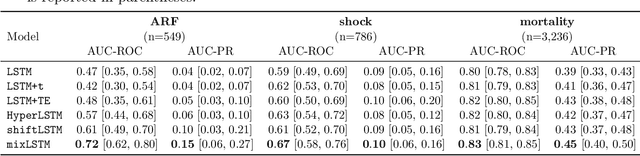
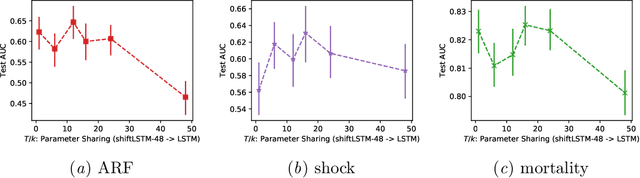
Recurrent neural networks (RNNs) are commonly applied to clinical time-series data with the goal of learning patient risk stratification models. Their effectiveness is due, in part, to their use of parameter sharing over time (i.e., cells are repeated hence the name recurrent). We hypothesize, however, that this trait also contributes to the increased difficulty such models have with learning relationships that change over time. Conditional shift, i.e., changes in the relationship between the input X and the output y, arises if the risk factors for the event of interest change over the course of a patient admission. While in theory, RNNs and gated RNNs (e.g., LSTMs) in particular should be capable of learning time-varying relationships, when training data are limited, such models often fail to accurately capture these dynamics. We illustrate the advantages and disadvantages of complete weight sharing (RNNs) by comparing an LSTM with shared parameters to a sequential architecture with time-varying parameters on three clinically-relevant prediction tasks: acute respiratory failure (ARF), shock, and in-hospital mortality. In experiments using synthetic data, we demonstrate how weight sharing in LSTMs leads to worse performance in the presence of conditional shift. To improve upon the dichotomy between complete weight sharing vs. no weight sharing, we propose a novel RNN formulation based on a mixture model in which we relax weight sharing over time. The proposed method outperforms standard LSTMs and other state-of-the-art baselines across all tasks. In settings with limited data, relaxed weight sharing can lead to improved patient risk stratification performance.
Learning to Exploit Invariances in Clinical Time-Series Data using Sequence Transformer Networks
Aug 21, 2018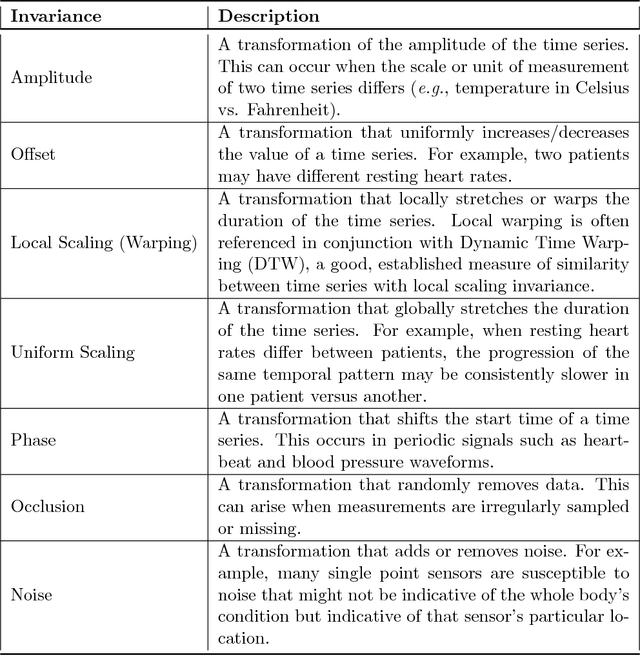
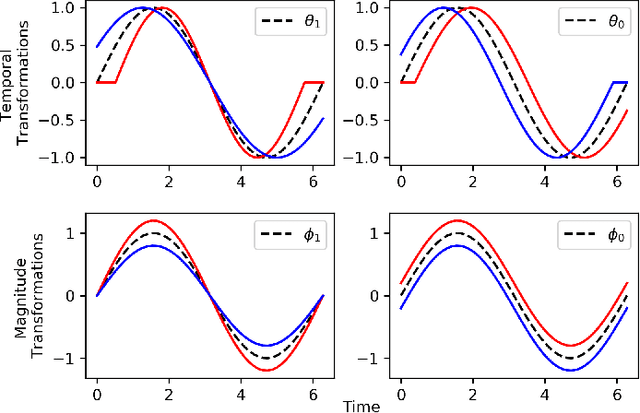
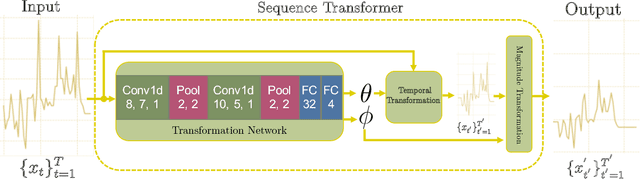
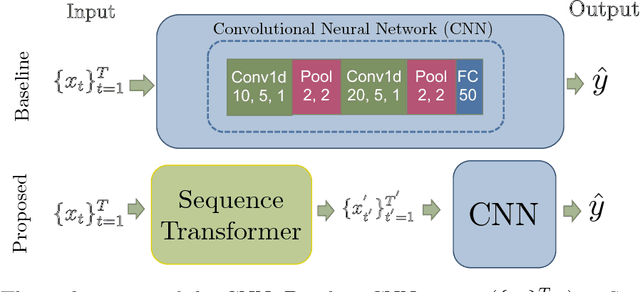
Recently, researchers have started applying convolutional neural networks (CNNs) with one-dimensional convolutions to clinical tasks involving time-series data. This is due, in part, to their computational efficiency, relative to recurrent neural networks and their ability to efficiently exploit certain temporal invariances, (e.g., phase invariance). However, it is well-established that clinical data may exhibit many other types of invariances (e.g., scaling). While preprocessing techniques, (e.g., dynamic time warping) may successfully transform and align inputs, their use often requires one to identify the types of invariances in advance. In contrast, we propose the use of Sequence Transformer Networks, an end-to-end trainable architecture that learns to identify and account for invariances in clinical time-series data. Applied to the task of predicting in-hospital mortality, our proposed approach achieves an improvement in the area under the receiver operating characteristic curve (AUROC) relative to a baseline CNN (AUROC=0.851 vs. AUROC=0.838). Our results suggest that a variety of valuable invariances can be learned directly from the data.
Learning Credible Models
Jun 07, 2018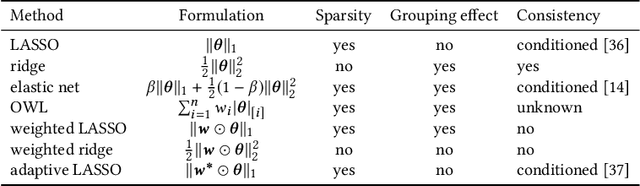
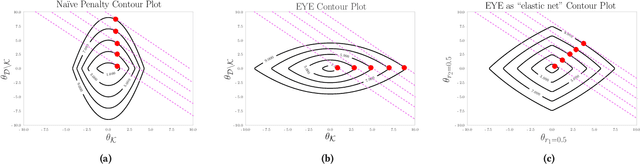
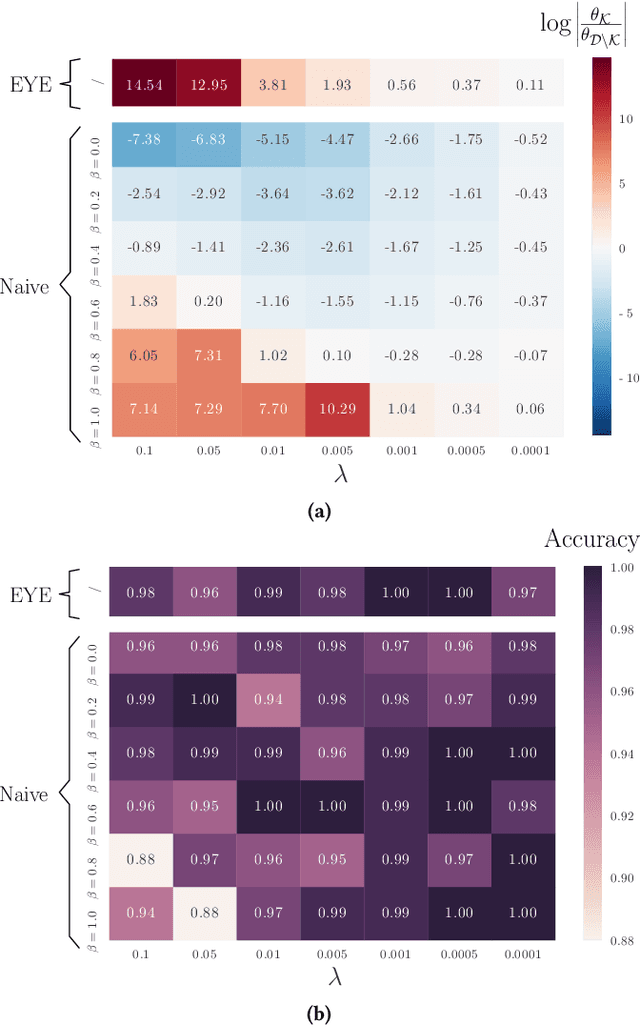
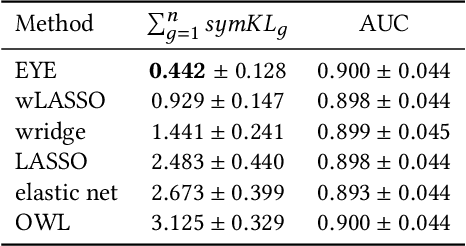
In many settings, it is important that a model be capable of providing reasons for its predictions (i.e., the model must be interpretable). However, the model's reasoning may not conform with well-established knowledge. In such cases, while interpretable, the model lacks \textit{credibility}. In this work, we formally define credibility in the linear setting and focus on techniques for learning models that are both accurate and credible. In particular, we propose a regularization penalty, expert yielded estimates (EYE), that incorporates expert knowledge about well-known relationships among covariates and the outcome of interest. We give both theoretical and empirical results comparing our proposed method to several other regularization techniques. Across a range of settings, experiments on both synthetic and real data show that models learned using the EYE penalty are significantly more credible than those learned using other penalties. Applied to a large-scale patient risk stratification task, our proposed technique results in a model whose top features overlap significantly with known clinical risk factors, while still achieving good predictive performance.