 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptively Coordinating with Novel Partners via Learned Latent Strategies
Nov 16, 2025Adaptation is the cornerstone of effective collaboration among heterogeneous team members. In human-agent teams, artificial agents need to adapt to their human partners in real time, as individuals often have unique preferences and policies that may change dynamically throughout interactions. This becomes particularly challenging in tasks with time pressure and complex strategic spaces, where identifying partner behaviors and selecting suitable responses is difficult. In this work, we introduce a strategy-conditioned cooperator framework that learns to represent, categorize, and adapt to a broad range of potential partner strategies in real-time. Our approach encodes strategies with a variational autoencoder to learn a latent strategy space from agent trajectory data, identifies distinct strategy types through clustering, and trains a cooperator agent conditioned on these clusters by generating partners of each strategy type. For online adaptation to novel partners, we leverage a fixed-share regret minimization algorithm that dynamically infers and adjusts the partner's strategy estimation during interaction. We evaluate our method in a modified version of the Overcooked domain, a complex collaborative cooking environment that requires effective coordination among two players with a diverse potential strategy space. Through these experiments and an online user study, we demonstrate that our proposed agent achieves state of the art performance compared to existing baselines when paired with novel human, and agent teammates.
How Can Everyday Users Efficiently Teach Robots by Demonstrations?
Oct 19, 2023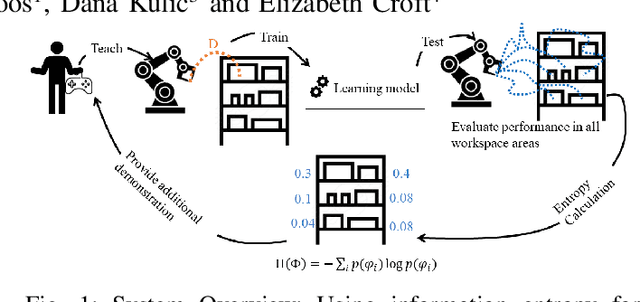
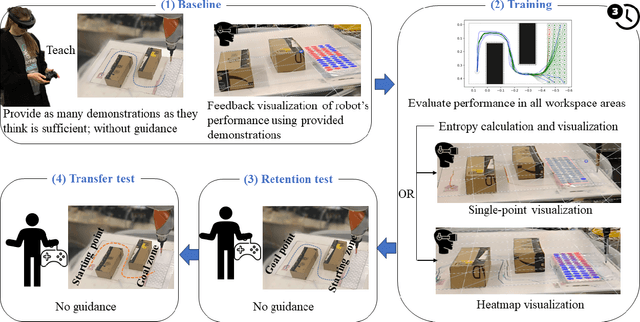

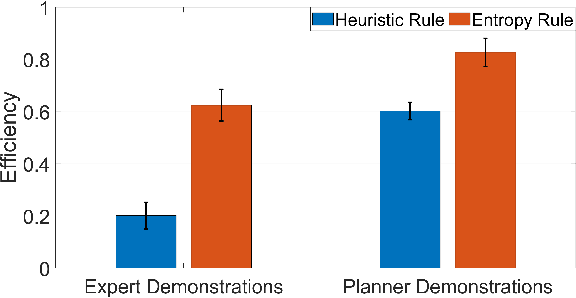
Learning from Demonstration (LfD) is a framework that allows lay users to easily program robots. However, the efficiency of robot learning and the robot's ability to generalize to task variations hinges upon the quality and quantity of the provided demonstrations. Our objective is to guide human teachers to furnish more effective demonstrations, thus facilitating efficient robot learning. To achieve this, we propose to use a measure of uncertainty, namely task-related information entropy, as a criterion for suggesting informative demonstration examples to human teachers to improve their teaching skills. In a conducted experiment (N=24), an augmented reality (AR)-based guidance system was employed to train novice users to produce additional demonstrations from areas with the highest entropy within the workspace. These novice users were trained for a few trials to teach the robot a generalizable task using a limited number of demonstrations. Subsequently, the users' performance after training was assessed first on the same task (retention) and then on a novel task (transfer) without guidance. The results indicated a substantial improvement in robot learning efficiency from the teacher's demonstrations, with an improvement of up to 198% observed on the novel task. Furthermore, the proposed approach was compared to a state-of-the-art heuristic rule and found to improve robot learning efficiency by 210% compared to the heuristic rule.
Mind the Performance Gap: Examining Dataset Shift During Prospective Validation
Jul 23, 2021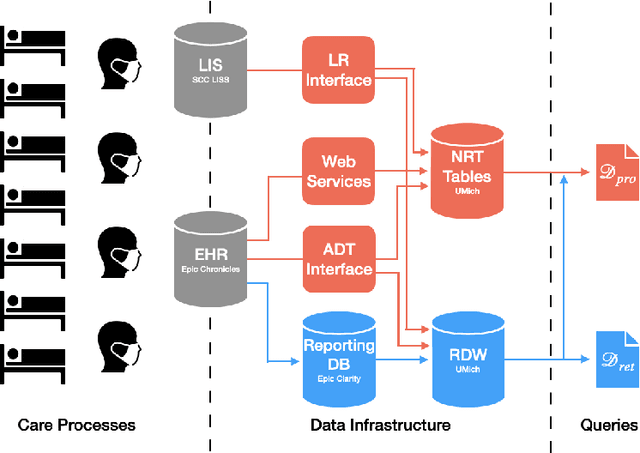
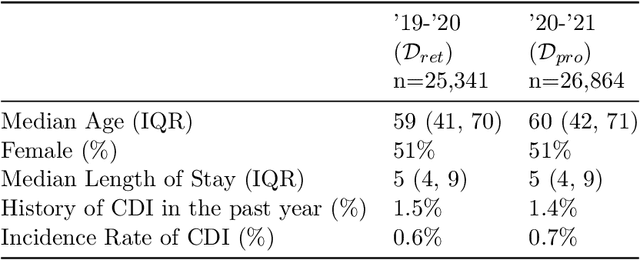
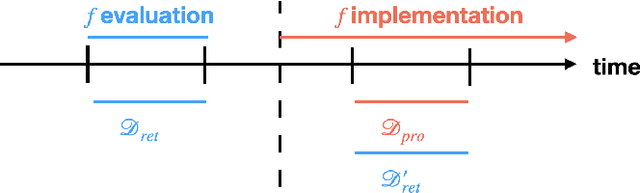

Once integrated into clinical care, patient risk stratification models may perform worse compared to their retrospective performance. To date, it is widely accepted that performance will degrade over time due to changes in care processes and patient populations. However, the extent to which this occurs is poorly understood, in part because few researchers report prospective validation performance. In this study, we compare the 2020-2021 ('20-'21) prospective performance of a patient risk stratification model for predicting healthcare-associated infections to a 2019-2020 ('19-'20) retrospective validation of the same model. We define the difference in retrospective and prospective performance as the performance gap. We estimate how i) "temporal shift", i.e., changes in clinical workflows and patient populations, and ii) "infrastructure shift", i.e., changes in access, extraction and transformation of data, both contribute to the performance gap. Applied prospectively to 26,864 hospital encounters during a twelve-month period from July 2020 to June 2021, the model achieved an area under the receiver operating characteristic curve (AUROC) of 0.767 (95% confidence interval (CI): 0.737, 0.801) and a Brier score of 0.189 (95% CI: 0.186, 0.191). Prospective performance decreased slightly compared to '19-'20 retrospective performance, in which the model achieved an AUROC of 0.778 (95% CI: 0.744, 0.815) and a Brier score of 0.163 (95% CI: 0.161, 0.165). The resulting performance gap was primarily due to infrastructure shift and not temporal shift. So long as we continue to develop and validate models using data stored in large research data warehouses, we must consider differences in how and when data are accessed, measure how these differences may affect prospective performance, and work to mitigate those differences.