 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHumanoid-GPT: Scaling Data and Structure for Zero-Shot Motion Tracking
Jun 02, 2026We introduce Humanoid-GPT, a GPT-style Transformer with causal attention trained on a billion-scale motion corpus for whole-body control. Unlike prior shallow MLP trackers constrained by scarce data and an agility-generalization trade-off, Humanoid-GPT is pre-trained on a 2B-frame retargeted corpus that unifies all major mocap datasets with large-scale in-house recordings. Scaling both data and model capacity yields a single generative Transformer that tracks highly dynamic behaviors while achieving unprecedented zero-shot generalization to unseen motions and control tasks. Extensive experiments and scaling analyses show that our model establishes a new performance frontier, demonstrating robust zero-shot generalization to unseen tasks while simultaneously tracking highly dynamic and complex motions.
Learning Athletic Humanoid Tennis Skills from Imperfect Human Motion Data
Mar 13, 2026Human athletes demonstrate versatile and highly-dynamic tennis skills to successfully conduct competitive rallies with a high-speed tennis ball. However, reproducing such behaviors on humanoid robots is difficult, partially due to the lack of perfect humanoid action data or human kinematic motion data in tennis scenarios as reference. In this work, we propose LATENT, a system that Learns Athletic humanoid TEnnis skills from imperfect human motioN daTa. The imperfect human motion data consist only of motion fragments that capture the primitive skills used when playing tennis rather than precise and complete human-tennis motion sequences from real-world tennis matches, thereby significantly reducing the difficulty of data collection. Our key insight is that, despite being imperfect, such quasi-realistic data still provide priors about human primitive skills in tennis scenarios. With further correction and composition, we learn a humanoid policy that can consistently strike incoming balls under a wide range of conditions and return them to target locations, while preserving natural motion styles. We also propose a series of designs for robust sim-to-real transfer and deploy our policy on the Unitree G1 humanoid robot. Our method achieves surprising results in the real world and can stably sustain multi-shot rallies with human players. Project page: https://zzk273.github.io/LATENT/
Collision-Free Humanoid Traversal in Cluttered Indoor Scenes
Jan 23, 2026We study the problem of collision-free humanoid traversal in cluttered indoor scenes, such as hurdling over objects scattered on the floor, crouching under low-hanging obstacles, or squeezing through narrow passages. To achieve this goal, the humanoid needs to map its perception of surrounding obstacles with diverse spatial layouts and geometries to the corresponding traversal skills. However, the lack of an effective representation that captures humanoid-obstacle relationships during collision avoidance makes directly learning such mappings difficult. We therefore propose Humanoid Potential Field (HumanoidPF), which encodes these relationships as collision-free motion directions, significantly facilitating RL-based traversal skill learning. We also find that HumanoidPF exhibits a surprisingly negligible sim-to-real gap as a perceptual representation. To further enable generalizable traversal skills through diverse and challenging cluttered indoor scenes, we further propose a hybrid scene generation method, incorporating crops of realistic 3D indoor scenes and procedurally synthesized obstacles. We successfully transfer our policy to the real world and develop a teleoperation system where users could command the humanoid to traverse in cluttered indoor scenes with just a single click. Extensive experiments are conducted in both simulation and the real world to validate the effectiveness of our method. Demos and code can be found in our website: https://axian12138.github.io/CAT/.
Track Any Motions under Any Disturbances
Sep 17, 2025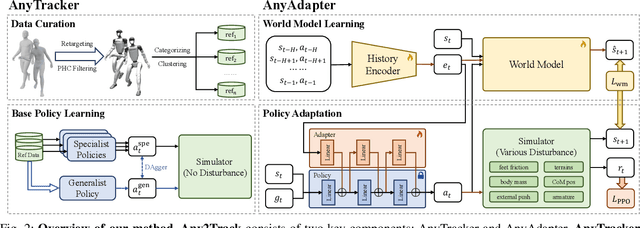

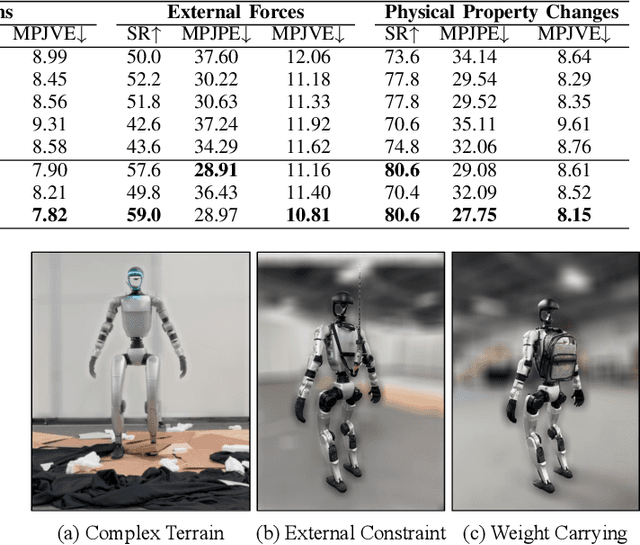

A foundational humanoid motion tracker is expected to be able to track diverse, highly dynamic, and contact-rich motions. More importantly, it needs to operate stably in real-world scenarios against various dynamics disturbances, including terrains, external forces, and physical property changes for general practical use. To achieve this goal, we propose Any2Track (Track Any motions under Any disturbances), a two-stage RL framework to track various motions under multiple disturbances in the real world. Any2Track reformulates dynamics adaptability as an additional capability on top of basic action execution and consists of two key components: AnyTracker and AnyAdapter. AnyTracker is a general motion tracker with a series of careful designs to track various motions within a single policy. AnyAdapter is a history-informed adaptation module that endows the tracker with online dynamics adaptability to overcome the sim2real gap and multiple real-world disturbances. We deploy Any2Track on Unitree G1 hardware and achieve a successful sim2real transfer in a zero-shot manner. Any2Track performs exceptionally well in tracking various motions under multiple real-world disturbances.
Unleashing Humanoid Reaching Potential via Real-world-Ready Skill Space
May 16, 2025Humans possess a large reachable space in the 3D world, enabling interaction with objects at varying heights and distances. However, realizing such large-space reaching on humanoids is a complex whole-body control problem and requires the robot to master diverse skills simultaneously-including base positioning and reorientation, height and body posture adjustments, and end-effector pose control. Learning from scratch often leads to optimization difficulty and poor sim2real transferability. To address this challenge, we propose Real-world-Ready Skill Space (R2S2). Our approach begins with a carefully designed skill library consisting of real-world-ready primitive skills. We ensure optimal performance and robust sim2real transfer through individual skill tuning and sim2real evaluation. These skills are then ensembled into a unified latent space, serving as a structured prior that helps task execution in an efficient and sim2real transferable manner. A high-level planner, trained to sample skills from this space, enables the robot to accomplish real-world goal-reaching tasks. We demonstrate zero-shot sim2real transfer and validate R2S2 in multiple challenging goal-reaching scenarios.
FreeMotion: MoCap-Free Human Motion Synthesis with Multimodal Large Language Models
Jun 15, 2024Human motion synthesis is a fundamental task in computer animation. Despite recent progress in this field utilizing deep learning and motion capture data, existing methods are always limited to specific motion categories, environments, and styles. This poor generalizability can be partially attributed to the difficulty and expense of collecting large-scale and high-quality motion data. At the same time, foundation models trained with internet-scale image and text data have demonstrated surprising world knowledge and reasoning ability for various downstream tasks. Utilizing these foundation models may help with human motion synthesis, which some recent works have superficially explored. However, these methods didn't fully unveil the foundation models' potential for this task and only support several simple actions and environments. In this paper, we for the first time, without any motion data, explore open-set human motion synthesis using natural language instructions as user control signals based on MLLMs across any motion task and environment. Our framework can be split into two stages: 1) sequential keyframe generation by utilizing MLLMs as a keyframe designer and animator; 2) motion filling between keyframes through interpolation and motion tracking. Our method can achieve general human motion synthesis for many downstream tasks. The promising results demonstrate the worth of mocap-free human motion synthesis aided by MLLMs and pave the way for future research.
How Can Everyday Users Efficiently Teach Robots by Demonstrations?
Oct 19, 2023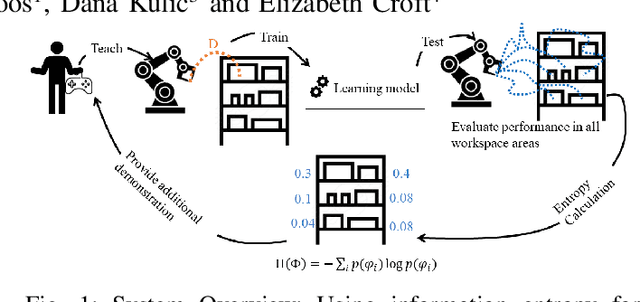
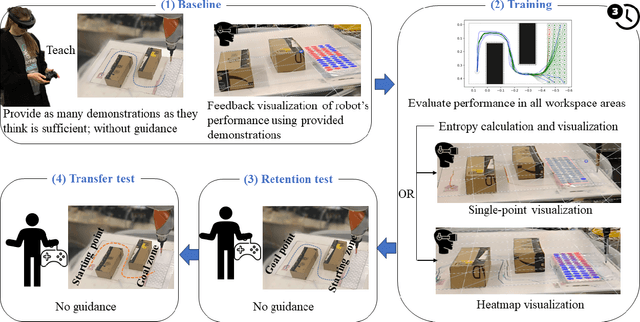

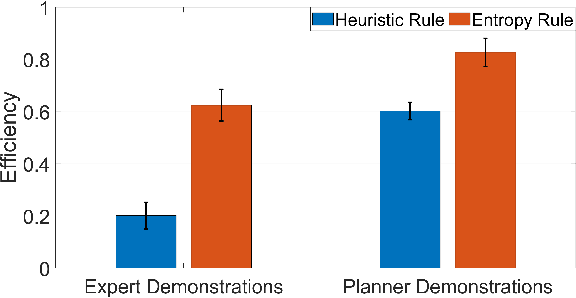
Learning from Demonstration (LfD) is a framework that allows lay users to easily program robots. However, the efficiency of robot learning and the robot's ability to generalize to task variations hinges upon the quality and quantity of the provided demonstrations. Our objective is to guide human teachers to furnish more effective demonstrations, thus facilitating efficient robot learning. To achieve this, we propose to use a measure of uncertainty, namely task-related information entropy, as a criterion for suggesting informative demonstration examples to human teachers to improve their teaching skills. In a conducted experiment (N=24), an augmented reality (AR)-based guidance system was employed to train novice users to produce additional demonstrations from areas with the highest entropy within the workspace. These novice users were trained for a few trials to teach the robot a generalizable task using a limited number of demonstrations. Subsequently, the users' performance after training was assessed first on the same task (retention) and then on a novel task (transfer) without guidance. The results indicated a substantial improvement in robot learning efficiency from the teacher's demonstrations, with an improvement of up to 198% observed on the novel task. Furthermore, the proposed approach was compared to a state-of-the-art heuristic rule and found to improve robot learning efficiency by 210% compared to the heuristic rule.
FreePoint: Unsupervised Point Cloud Instance Segmentation
May 11, 2023



Instance segmentation of point clouds is a crucial task in 3D field with numerous applications that involve localizing and segmenting objects in a scene. However, achieving satisfactory results requires a large number of manual annotations, which is a time-consuming and expensive process. To alleviate dependency on annotations, we propose a method, called FreePoint, for underexplored unsupervised class-agnostic instance segmentation on point clouds. In detail, we represent the point features by combining coordinates, colors, normals, and self-supervised deep features. Based on the point features, we perform a multicut algorithm to segment point clouds into coarse instance masks as pseudo labels, which are used to train a point cloud instance segmentation model. To alleviate the inaccuracy of coarse masks during training, we propose a weakly-supervised training strategy and corresponding loss. Our work can also serve as an unsupervised pre-training pretext for supervised semantic instance segmentation with limited annotations. For class-agnostic instance segmentation on point clouds, FreePoint largely fills the gap with its fully-supervised counterpart based on the state-of-the-art instance segmentation model Mask3D and even surpasses some previous fully-supervised methods. When serving as a pretext task and fine-tuning on S3DIS, FreePoint outperforms training from scratch by 5.8% AP with only 10% mask annotations.