 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConsistency Matters: Defining Demonstration Data Quality Metrics in Robot Learning from Demonstration
Dec 18, 2024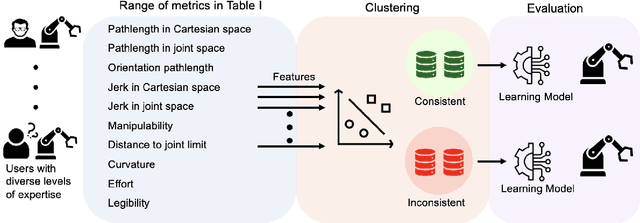
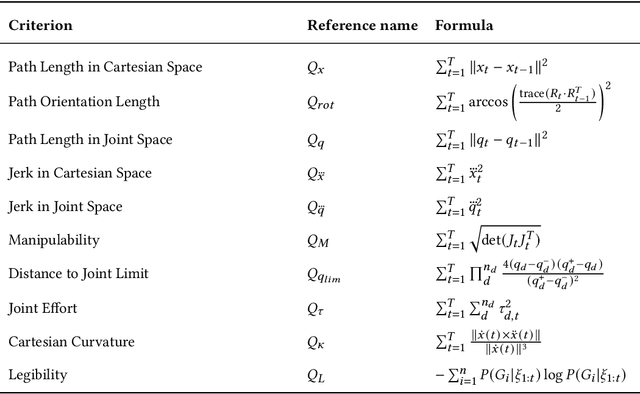

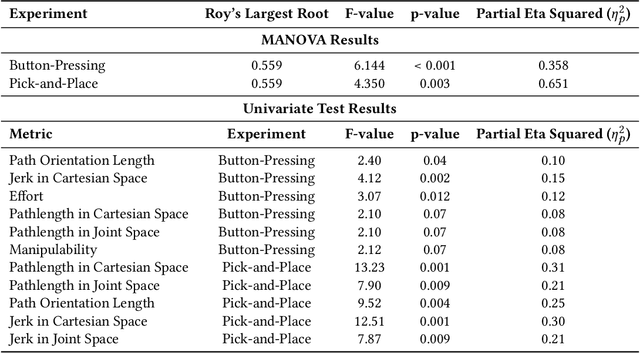
Learning from Demonstration (LfD) empowers robots to acquire new skills through human demonstrations, making it feasible for everyday users to teach robots. However, the success of learning and generalization heavily depends on the quality of these demonstrations. Consistency is often used to indicate quality in LfD, yet the factors that define this consistency remain underexplored. In this paper, we evaluate a comprehensive set of motion data characteristics to determine which consistency measures best predict learning performance. By ensuring demonstration consistency prior to training, we enhance models' predictive accuracy and generalization to novel scenarios. We validate our approach with two user studies involving participants with diverse levels of robotics expertise. In the first study (N = 24), users taught a PR2 robot to perform a button-pressing task in a constrained environment, while in the second study (N = 30), participants trained a UR5 robot on a pick-and-place task. Results show that demonstration consistency significantly impacts success rates in both learning and generalization, with 70% and 89% of task success rates in the two studies predicted using our consistency metrics. Moreover, our metrics estimate generalized performance success rates with 76% and 91% accuracy. These findings suggest that our proposed measures provide an intuitive, practical way to assess demonstration data quality before training, without requiring expert data or algorithm-specific modifications. Our approach offers a systematic way to evaluate demonstration quality, addressing a critical gap in LfD by formalizing consistency metrics that enhance the reliability of robot learning from human demonstrations.
FLAIR: Feeding via Long-horizon AcquIsition of Realistic dishes
Jul 10, 2024



Robot-assisted feeding has the potential to improve the quality of life for individuals with mobility limitations who are unable to feed themselves independently. However, there exists a large gap between the homogeneous, curated plates existing feeding systems can handle, and truly in-the-wild meals. Feeding realistic plates is immensely challenging due to the sheer range of food items that a robot may encounter, each requiring specialized manipulation strategies which must be sequenced over a long horizon to feed an entire meal. An assistive feeding system should not only be able to sequence different strategies efficiently in order to feed an entire meal, but also be mindful of user preferences given the personalized nature of the task. We address this with FLAIR, a system for long-horizon feeding which leverages the commonsense and few-shot reasoning capabilities of foundation models, along with a library of parameterized skills, to plan and execute user-preferred and efficient bite sequences. In real-world evaluations across 6 realistic plates, we find that FLAIR can effectively tap into a varied library of skills for efficient food pickup, while adhering to the diverse preferences of 42 participants without mobility limitations as evaluated in a user study. We demonstrate the seamless integration of FLAIR with existing bite transfer methods [19, 28], and deploy it across 2 institutions and 3 robots, illustrating its adaptability. Finally, we illustrate the real-world efficacy of our system by successfully feeding a care recipient with severe mobility limitations. Supplementary materials and videos can be found at: https://emprise.cs.cornell.edu/flair .
How Can Everyday Users Efficiently Teach Robots by Demonstrations?
Oct 19, 2023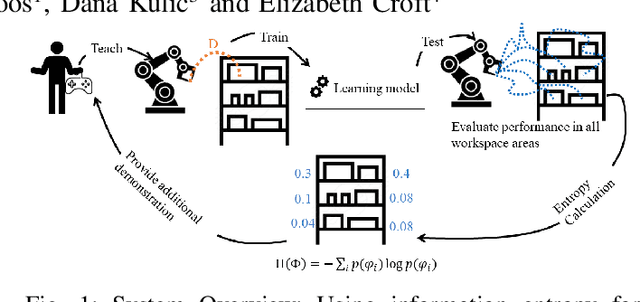
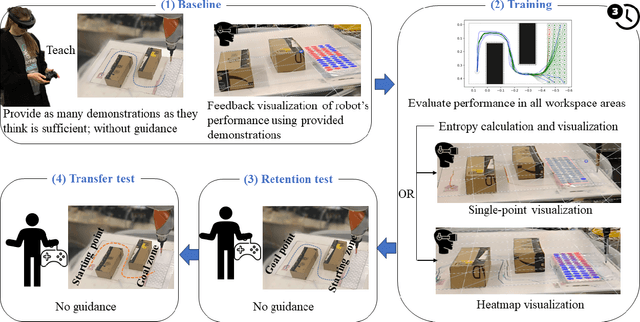

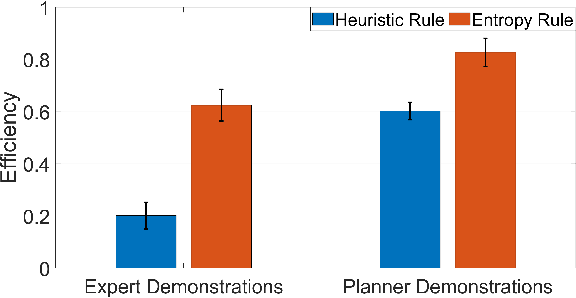
Learning from Demonstration (LfD) is a framework that allows lay users to easily program robots. However, the efficiency of robot learning and the robot's ability to generalize to task variations hinges upon the quality and quantity of the provided demonstrations. Our objective is to guide human teachers to furnish more effective demonstrations, thus facilitating efficient robot learning. To achieve this, we propose to use a measure of uncertainty, namely task-related information entropy, as a criterion for suggesting informative demonstration examples to human teachers to improve their teaching skills. In a conducted experiment (N=24), an augmented reality (AR)-based guidance system was employed to train novice users to produce additional demonstrations from areas with the highest entropy within the workspace. These novice users were trained for a few trials to teach the robot a generalizable task using a limited number of demonstrations. Subsequently, the users' performance after training was assessed first on the same task (retention) and then on a novel task (transfer) without guidance. The results indicated a substantial improvement in robot learning efficiency from the teacher's demonstrations, with an improvement of up to 198% observed on the novel task. Furthermore, the proposed approach was compared to a state-of-the-art heuristic rule and found to improve robot learning efficiency by 210% compared to the heuristic rule.
Quantifying Demonstration Quality for Robot Learning and Generalization
Mar 25, 2022
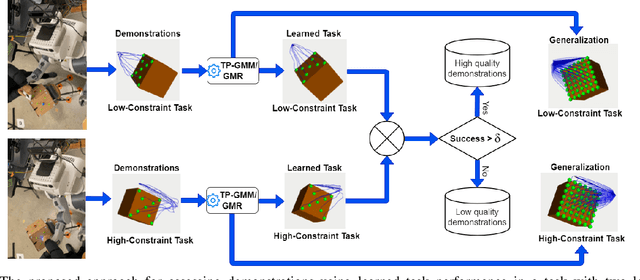
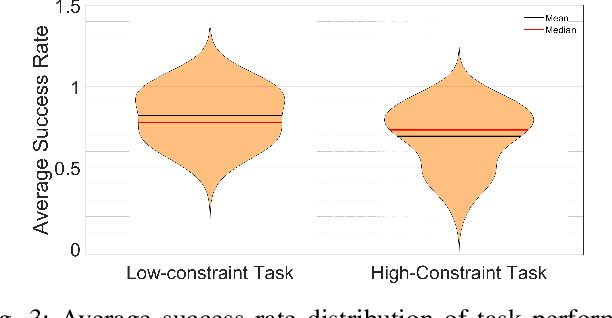
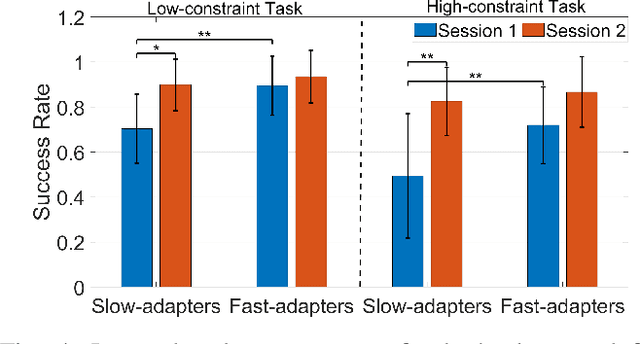
Learning from Demonstration (LfD) seeks to democratize robotics by enabling diverse end-users to teach robots to perform a task by providing demonstrations. However, most LfD techniques assume users provide optimal demonstrations. This is not always the case in real applications where users are likely to provide demonstrations of varying quality, that may change with expertise and other factors. Demonstration quality plays a crucial role in robot learning and generalization. Hence, it is important to quantify the quality of the provided demonstrations before using them for robot learning. In this paper, we propose quantifying the quality of the demonstrations based on how well they perform in the learned task. We hypothesize that task performance can give an indication of the generalization performance on similar tasks. The proposed approach is validated in a user study (N = 27). Users with different robotics expertise levels were recruited to teach a PR2 robot a generic task (pressing a button) under different task constraints. They taught the robot in two sessions on two different days to capture their teaching behaviour across sessions. The task performance was utilized to classify the provided demonstrations into high-quality and low-quality sets. The results show a significant Pearson correlation coefficient (R = 0.85, p < 0.0001) between the task performance and generalization performance across all participants. We also found that users clustered into two groups: Users who provided high-quality demonstrations from the first session, assigned to the fast-adapters group, and users who provided low-quality demonstrations in the first session and then improved with practice, assigned to the slow-adapters group. These results highlight the importance of quantifying demonstration quality, which can be indicative of the adaptation level of the user to the task.
Design and Evaluation of an Augmented Reality Head-Mounted Display Interface for Human Robot Teams Collaborating in Physically Shared Manufacturing Tasks
Mar 16, 2022
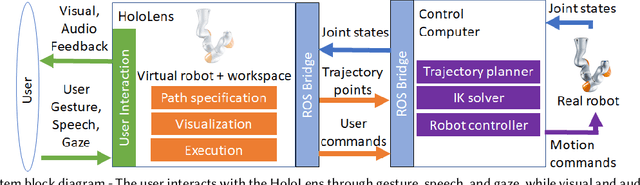
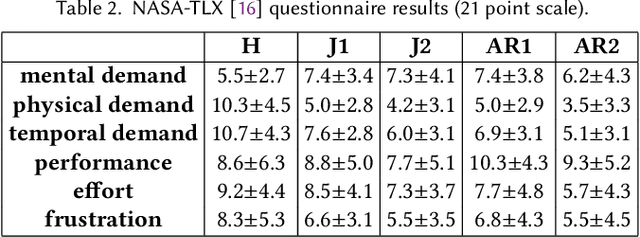

We provide an experimental evaluation of a wearable augmented reality (AR) system we have developed for human-robot teams working on tasks requiring collaboration in shared physical workspace. Recent advances in AR technology have facilitated the development of more intuitive user interfaces for many human-robot interaction applications. While it has been anticipated that AR can provided a more intuitive interface to robot assistants helping human workers in various manufacturing scenarios, existing studies in robotics have been largely limited to teleoperation and programming. Industry 5.0 envisions cooperation between human and robot working in teams. Indeed, there exist many industrial task that can benefit from human-robot collaboration. A prime example is high-value composite manufacturing. Working with our industry partner towards this example application, we evaluated our AR interface design for shared physical workspace collaboration in human-robot teams. We conducted a multi-dimensional analysis of our interface using establish metrics. Results from our user study (n=26) show that subjectively, the AR interface feels more novel and a standard joystick interface feels more dependable to users. However, the AR interface was found to reduce physical demand and task completion time, while increasing robot utilization. Furthermore, user's freedom of choice to collaborate with the robot may also affect the perceived usability of the system.
Orientation Matters: 6-DoF Autonomous Camera Movement for Minimally Invasive Surgery
Dec 04, 2020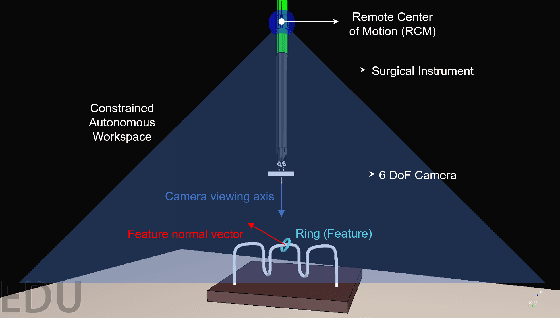
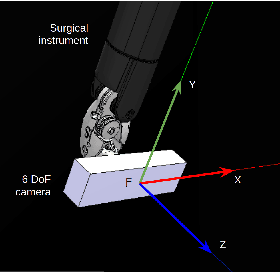
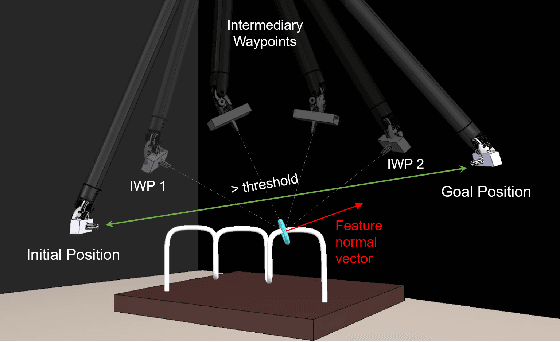
We propose a new method for six-degree-of-freedom (6-DoF) autonomous camera movement for minimally invasive surgery, which, unlike previous methods, takes into account both the position and orientation information from structures in the surgical scene. In addition to locating the camera for a good view of the manipulated object, our autonomous camera takes into account workspace constraints, including the horizon and safety constraints. We developed a simulation environment to test our method on the "wire chaser" surgical training task from validated training curricula in conventional laparoscopy and robot-assisted surgery. Furthermore, we propose, for the first time, the application of the proposed autonomous camera method in video-based surgical skill assessment, an area where videos are typically recorded using fixed cameras. In a study with N=30 human subjects, we show that video examination of the autonomous camera view as it tracks the ring motion over the wire leads to more accurate user error (ring touching the wire) detection than when using a fixed camera view, or camera movement with a fixed orientation. Our preliminary work suggests that there are potential benefits to autonomous camera positioning informed by scene orientation, and this can direct designers of automated endoscopes and surgical robotic systems, especially when using chip-on-tip cameras that can be wristed for 6-DoF motion.