 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel-free Legibility: Enhancing Human-Robot Interactions through Implicit Communication and Influence Modulation
Jun 18, 2024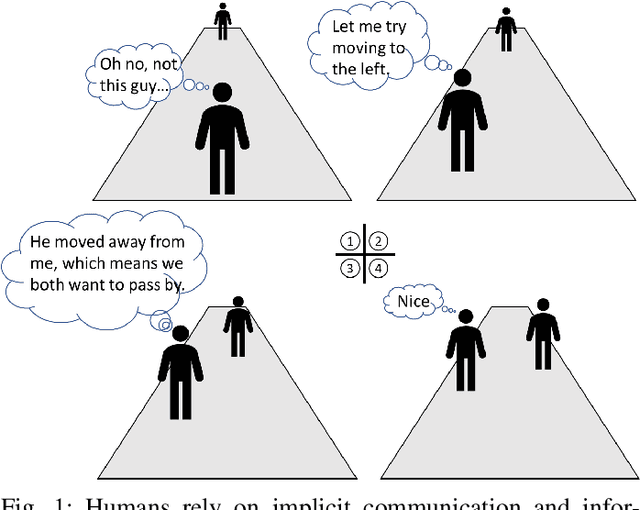
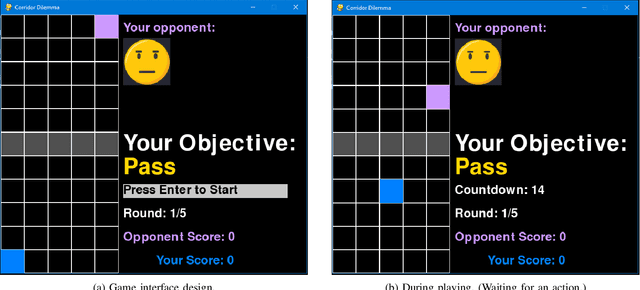
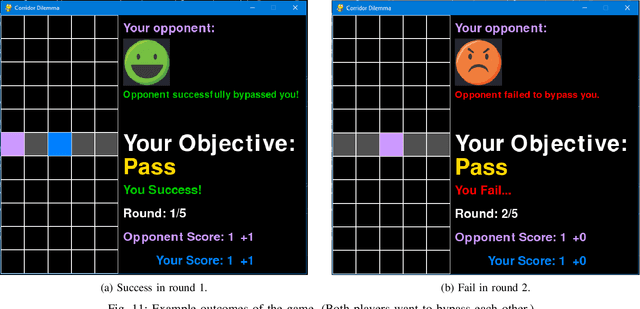
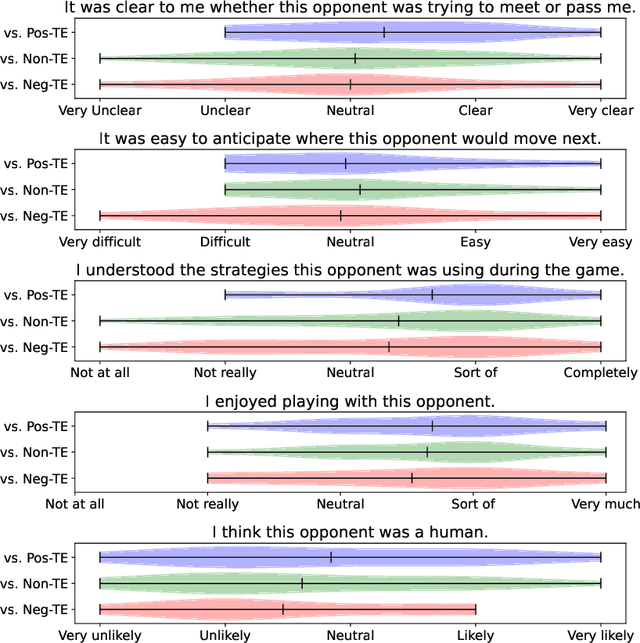
Communication is essential for successful interaction. In human-robot interaction, implicit communication enhances robots' understanding of human needs, emotions, and intentions. This paper introduces a method to foster implicit communication in HRI without explicitly modeling human intentions or relying on pre-existing knowledge. Leveraging Transfer Entropy, we modulate influence between agents in social interactions in scenarios involving either collaboration or competition. By integrating influence into agents' rewards within a partially observable Markov decision process, we demonstrate that boosting influence enhances collaboration or competition performance, while resisting influence diminishes performance. Our findings are validated through simulations and real-world experiments with human participants.
Robot Gaze During Autonomous Navigation and its Effect on Social Presence
May 10, 2023As robots have become increasingly common in human-rich environments, it is critical that they are able to exhibit social cues to be perceived as a cooperative and socially-conformant team member. We investigate the effect of robot gaze cues on people's subjective perceptions of a mobile robot as a socially present entity in three common hallway navigation scenarios. The tested robot gaze behaviors were path-oriented (looking at its own future path), or person-oriented (looking at the nearest person), with fixed-gaze as the control. We conduct a real-world study with 36 participants who walked through the hallway, and an online study with 233 participants who were shown simulated videos of the same scenarios. Our results suggest that the preferred gaze behavior is scenario-dependent. Person-oriented gaze behaviors which acknowledge the presence of the human are generally preferred when the robot and human cross paths. However, this benefit is diminished in scenarios that involve less implicit interaction between the robot and the human.
Social Cue Analysis using Transfer Entropy
Mar 06, 2023



Robots that work close to humans need to understand and use social cues to act in a socially acceptable manner. Social cues are a form of communication (i.e., information flow) between people. In this paper, a framework is introduced to detect and analyse social cues and information transfer directionality using an information-theoretic measure, namely, transfer entropy. We demonstrate the framework in three settings involving social interactions between humans: object-handover, group-joining and person-following. Results show that transfer entropy can identify information flows between agents, when and where they occur, and their relative strength. For instance, in a person-following scenario, we find that head orientation of a predictor is particularly informative, and the different times and locations that this is used to convey information to a leader influences their behaviour. Potential applications of the framework include information flow or social cue analysis for interactive robot design, or socially-aware robot planning.
Quantifying Demonstration Quality for Robot Learning and Generalization
Mar 25, 2022
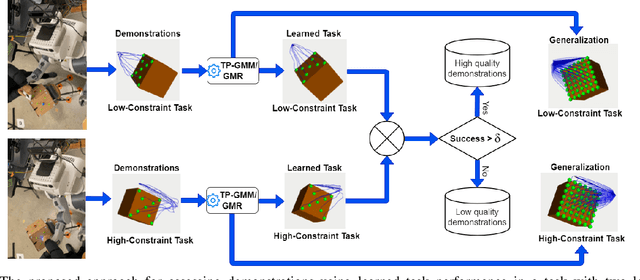
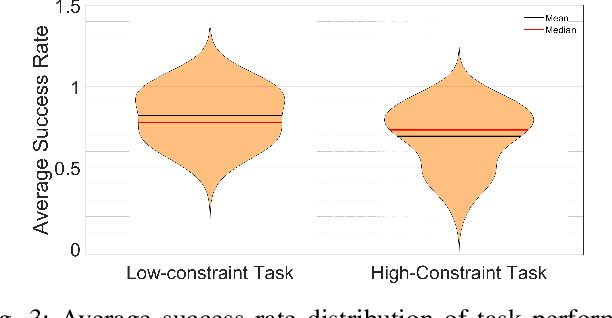
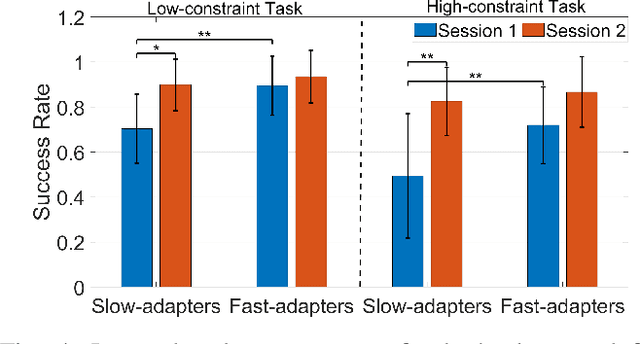
Learning from Demonstration (LfD) seeks to democratize robotics by enabling diverse end-users to teach robots to perform a task by providing demonstrations. However, most LfD techniques assume users provide optimal demonstrations. This is not always the case in real applications where users are likely to provide demonstrations of varying quality, that may change with expertise and other factors. Demonstration quality plays a crucial role in robot learning and generalization. Hence, it is important to quantify the quality of the provided demonstrations before using them for robot learning. In this paper, we propose quantifying the quality of the demonstrations based on how well they perform in the learned task. We hypothesize that task performance can give an indication of the generalization performance on similar tasks. The proposed approach is validated in a user study (N = 27). Users with different robotics expertise levels were recruited to teach a PR2 robot a generic task (pressing a button) under different task constraints. They taught the robot in two sessions on two different days to capture their teaching behaviour across sessions. The task performance was utilized to classify the provided demonstrations into high-quality and low-quality sets. The results show a significant Pearson correlation coefficient (R = 0.85, p < 0.0001) between the task performance and generalization performance across all participants. We also found that users clustered into two groups: Users who provided high-quality demonstrations from the first session, assigned to the fast-adapters group, and users who provided low-quality demonstrations in the first session and then improved with practice, assigned to the slow-adapters group. These results highlight the importance of quantifying demonstration quality, which can be indicative of the adaptation level of the user to the task.
ARviz -- An Augmented Reality-enabled Visualization Platform for ROS Applications
Oct 29, 2021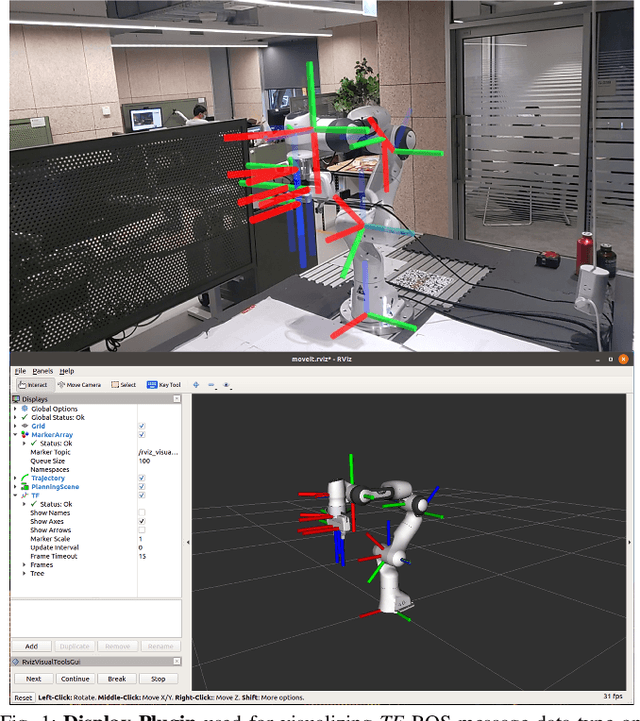
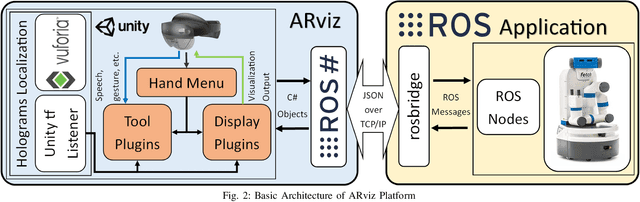


Current robot interfaces such as teach pendants and 2D screen displays used for task visualization and interaction often seem unintuitive and limited in terms of information flow. This compromises task efficiency as interacting with the interface can distract the user from the task at hand. Augmented Reality (AR) technology offers the capability to create visually rich displays and intuitive interaction elements in situ. In recent years, AR has shown promising potential to enable effective human-robot interaction. We introduce ARviz - a versatile, extendable AR visualization platform built for robot applications developed with the widely used Robot Operating System (ROS) framework. ARviz aims to provide both a universal visualization platform with the capability of displaying any ROS message data type in AR, as well as a multimodal user interface for interacting with robots over ROS. ARviz is built as a platform incorporating a collection of plugins that provide visualization and/or interaction components. Users can also extend the platform by implementing new plugins to suit their needs. We present three use cases as well as two potential use cases to showcase the capabilities and benefits of the ARviz platform for human-robot interaction applications. The open access source code for our ARviz platform is available at: https://github.com/hri-group/arviz.
A Proposed Set of Communicative Gestures for Human Robot Interaction and an RGB Image-based Gesture Recognizer Implemented in ROS
Sep 21, 2021

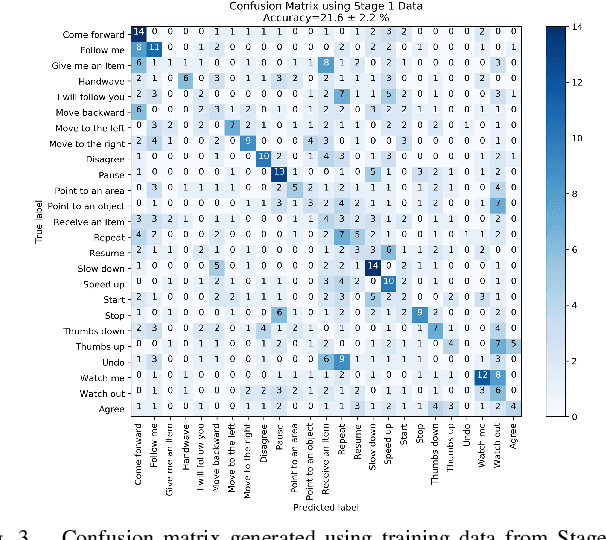
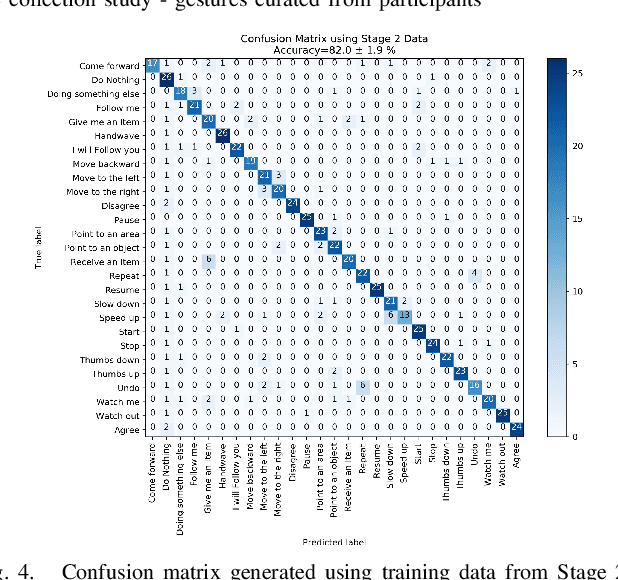
We propose a set of communicative gestures and develop a gesture recognition system with the aim of facilitating more intuitive Human-Robot Interaction (HRI) through gestures. First, we propose a set of commands commonly used for human-robot interaction. Next, an online user study with 190 participants was performed to investigate if there was an agreed set of gestures that people intuitively use to communicate the given commands to robots when no guidance or training were given. As we found large variations among the gestures exist between participants, we then proposed a set of gestures for the proposed commands to be used as a common foundation for robot interaction. We collected ~7500 video demonstrations of the proposed gestures and trained a gesture recognition model, adapting 3D Convolutional Neural Networks (CNN) as the classifier, with a final accuracy of 84.1% (sigma=2.4). The resulting model was capable of training successfully with a relatively small amount of training data. We integrated the gesture recognition model into the ROS framework and report details for a demonstrated use case, where a person commands a robot to perform a pick and place task using the proposed set. This integrated ROS gesture recognition system is made available for use, and built with the intention to allow for new adaptations depending on robot model and use case scenarios, for novel user applications.
Mobile Robot Yielding Cues for Human-Robot Spatial Interaction
Apr 06, 2021

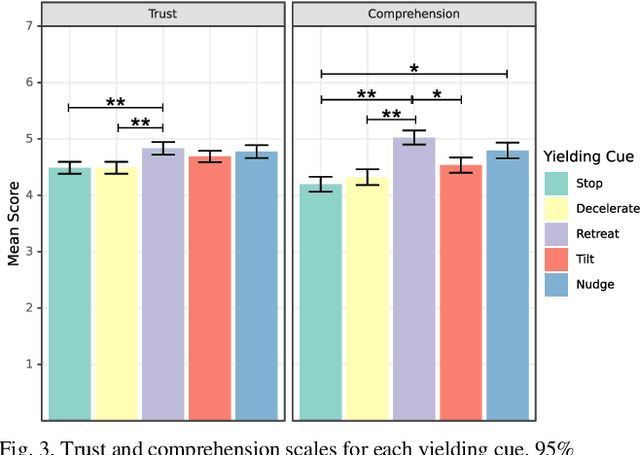
Mobile robots are increasingly being deployed in public spaces such as shopping malls, airports, and urban sidewalks. Most of these robots are designed with human-aware motion planning capabilities but are not designed to communicate with pedestrians. Pedestrians encounter these robots without prior understanding of the robots' behaviour, which can cause discomfort, confusion, and delayed social acceptance. In this research, we explore the common human-robot interaction at a doorway or bottleneck in a structured environment. We designed and evaluated communication cues used by a robot when yielding to a pedestrian in this scenario. We conducted an online user study with 102 participants using videos of a set of robot-to-human yielding cues. Results show that a Robot Retreating cue was the most socially acceptable cue. The results of this work help guide the development of mobile robots for public spaces.
Hey Robot, Which Way Are You Going? Nonverbal Motion Legibility Cues for Human-Robot Spatial Interaction
Apr 06, 2021
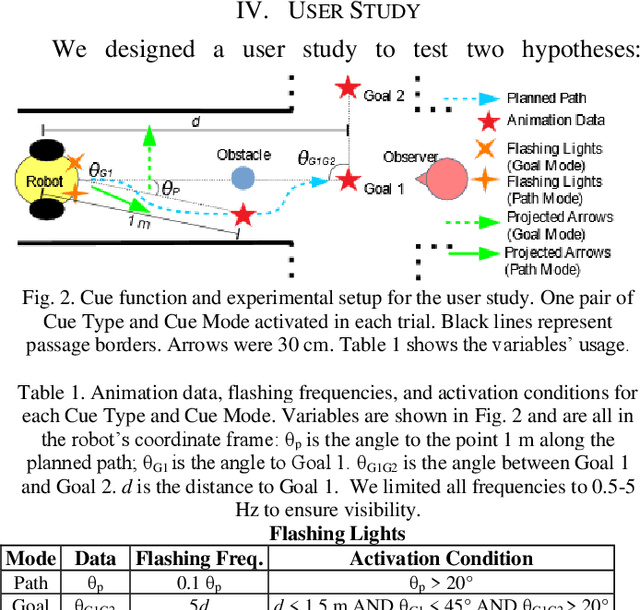
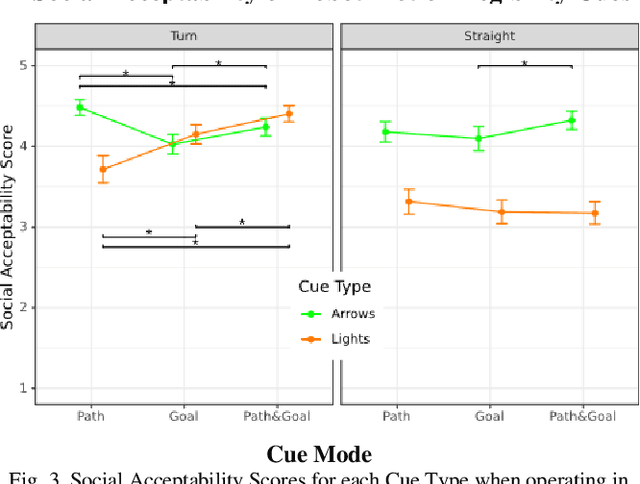
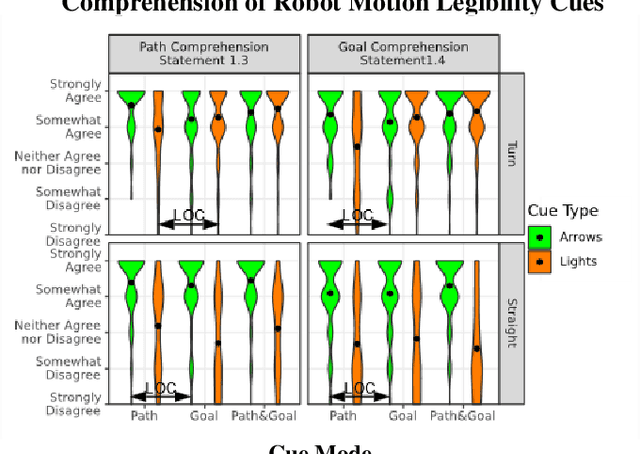
Mobile robots have recently been deployed in public spaces such as shopping malls, airports, and urban sidewalks. Most of these robots are designed with human-aware motion planning capabilities but are not designed to communicate with pedestrians. Pedestrians that encounter these robots without prior understanding of the robots' behaviour can experience discomfort, confusion, and delayed social acceptance. In this work we designed and evaluated nonverbal robot motion legibility cues, which communicate a mobile robot's motion intention to pedestrians. We compared a motion legibility cue using Projected Arrows to one using Flashing Lights. We designed the cues to communicate path information, goal information, or both, and explored different Robot Movement Scenarios. We conducted an online user study with 229 participants using videos of the motion legibility cues. Our results show that the absence of cues was not socially acceptable, and that Projected Arrows were the more socially acceptable cue in most experimental conditions. We conclude that the presence and choice of motion legibility cues can positively influence robots' acceptance and successful deployment in public spaces.