 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobot Gaze During Autonomous Navigation and its Effect on Social Presence
May 10, 2023As robots have become increasingly common in human-rich environments, it is critical that they are able to exhibit social cues to be perceived as a cooperative and socially-conformant team member. We investigate the effect of robot gaze cues on people's subjective perceptions of a mobile robot as a socially present entity in three common hallway navigation scenarios. The tested robot gaze behaviors were path-oriented (looking at its own future path), or person-oriented (looking at the nearest person), with fixed-gaze as the control. We conduct a real-world study with 36 participants who walked through the hallway, and an online study with 233 participants who were shown simulated videos of the same scenarios. Our results suggest that the preferred gaze behavior is scenario-dependent. Person-oriented gaze behaviors which acknowledge the presence of the human are generally preferred when the robot and human cross paths. However, this benefit is diminished in scenarios that involve less implicit interaction between the robot and the human.
Autonomous social robot navigation in unknown urban environments using semantic segmentation
Aug 25, 2022


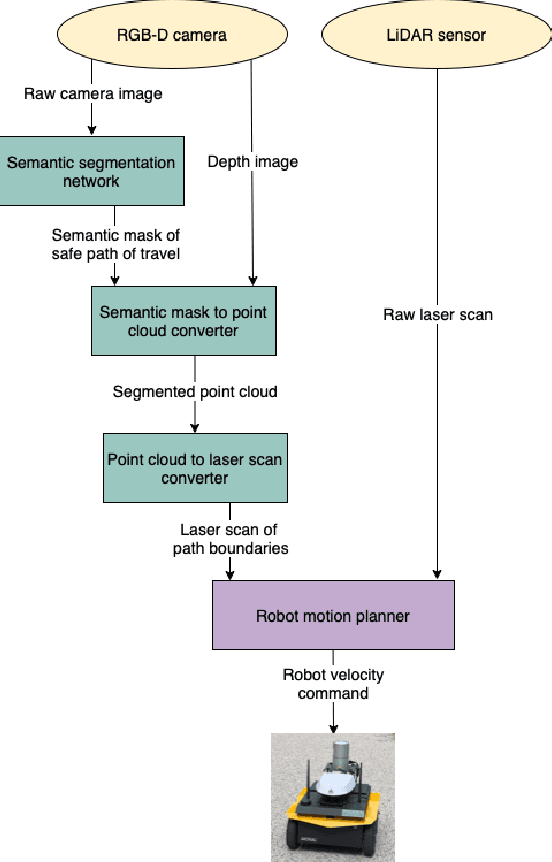
For autonomous robots navigating in urban environments, it is important for the robot to stay on the designated path of travel (i.e., the footpath), and avoid areas such as grass and garden beds, for safety and social conformity considerations. This paper presents an autonomous navigation approach for unknown urban environments that combines the use of semantic segmentation and LiDAR data. The proposed approach uses the segmented image mask to create a 3D obstacle map of the environment, from which, the boundaries of the footpath is computed. Compared to existing methods, our approach does not require a pre-built map and provides a 3D understanding of the safe region of travel, enabling the robot to plan any path through the footpath. Experiments comparing our method with two alternatives using only LiDAR or only semantic segmentation show that overall our proposed approach performs significantly better with greater than 91% success rate outdoors, and greater than 66% indoors. Our method enabled the robot to remain on the safe path of travel at all times, and reduced the number of collisions.
Design and Implementation of a Human-Robot Joint Action Framework using Augmented Reality and Eye Gaze
Aug 25, 2022

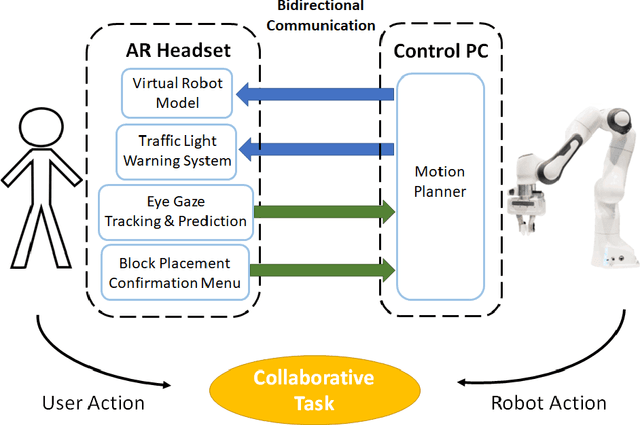

When humans work together to complete a joint task, each person builds an internal model of the situation and how it will evolve. Efficient collaboration is dependent on how these individual models overlap to form a shared mental model among team members, which is important for collaborative processes in human-robot teams. The development and maintenance of an accurate shared mental model requires bidirectional communication of individual intent and the ability to interpret the intent of other team members. To enable effective human-robot collaboration, this paper presents a design and implementation of a novel joint action framework in human-robot team collaboration, utilizing augmented reality (AR) technology and user eye gaze to enable bidirectional communication of intent. We tested our new framework through a user study with 37 participants, and found that our system improves task efficiency, trust, as well as task fluency. Therefore, using AR and eye gaze to enable bidirectional communication is a promising mean to improve core components that influence collaboration between humans and robots.
Metrics for Evaluating Social Conformity of Crowd Navigation Algorithms
Feb 02, 2022
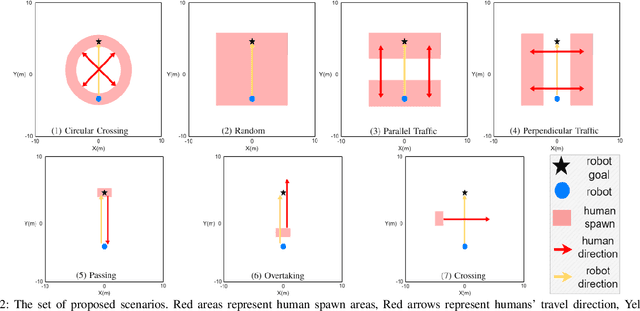


Recent protocols and metrics for training and evaluating autonomous robot navigation through crowds are inconsistent due to diversified definitions of "social behavior". This makes it difficult, if not impossible, to effectively compare published navigation algorithms. Furthermore, with the lack of a good evaluation protocol, resulting algorithms may fail to generalize, due to lack of diversity in training. To address these gaps, this paper facilitates a more comprehensive evaluation and objective comparison of crowd navigation algorithms by proposing a consistent set of metrics that accounts for both efficiency and social conformity, and a systematic protocol comprising multiple crowd navigation scenarios of varying complexity for evaluation. We tested four state-of-the-art algorithms under this protocol. Results revealed that some state-of-the-art algorithms have much challenge in generalizing, and using our protocol for training, we were able to improve the algorithm's performance. We demonstrate that the set of proposed metrics provides more insight and effectively differentiates the performance of these algorithms with respect to efficiency and social conformity.
ARviz -- An Augmented Reality-enabled Visualization Platform for ROS Applications
Oct 29, 2021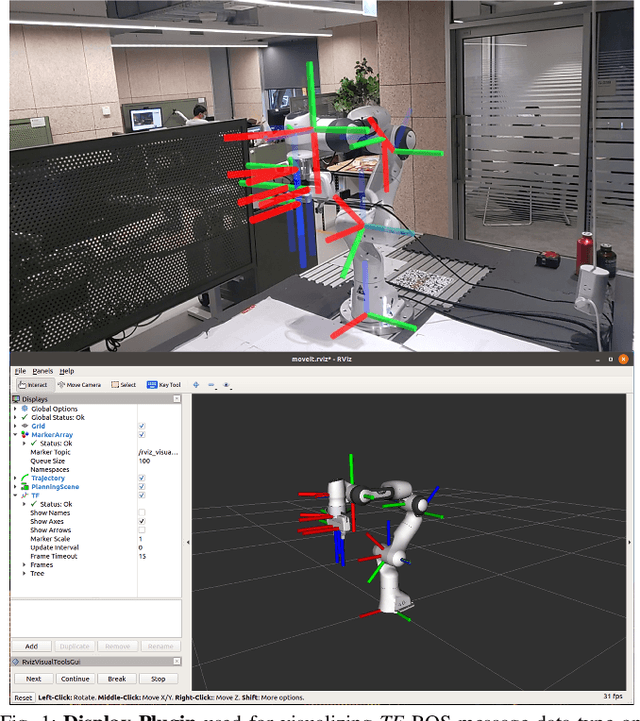
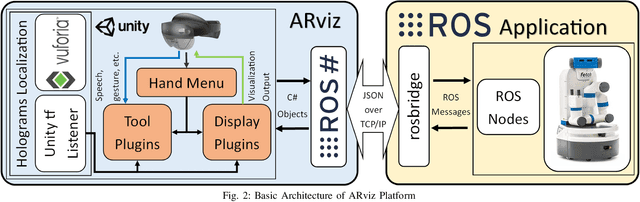


Current robot interfaces such as teach pendants and 2D screen displays used for task visualization and interaction often seem unintuitive and limited in terms of information flow. This compromises task efficiency as interacting with the interface can distract the user from the task at hand. Augmented Reality (AR) technology offers the capability to create visually rich displays and intuitive interaction elements in situ. In recent years, AR has shown promising potential to enable effective human-robot interaction. We introduce ARviz - a versatile, extendable AR visualization platform built for robot applications developed with the widely used Robot Operating System (ROS) framework. ARviz aims to provide both a universal visualization platform with the capability of displaying any ROS message data type in AR, as well as a multimodal user interface for interacting with robots over ROS. ARviz is built as a platform incorporating a collection of plugins that provide visualization and/or interaction components. Users can also extend the platform by implementing new plugins to suit their needs. We present three use cases as well as two potential use cases to showcase the capabilities and benefits of the ARviz platform for human-robot interaction applications. The open access source code for our ARviz platform is available at: https://github.com/hri-group/arviz.
A Proposed Set of Communicative Gestures for Human Robot Interaction and an RGB Image-based Gesture Recognizer Implemented in ROS
Sep 21, 2021

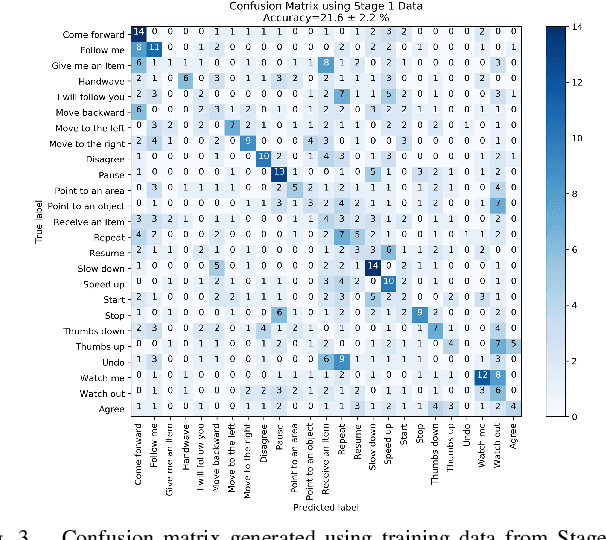
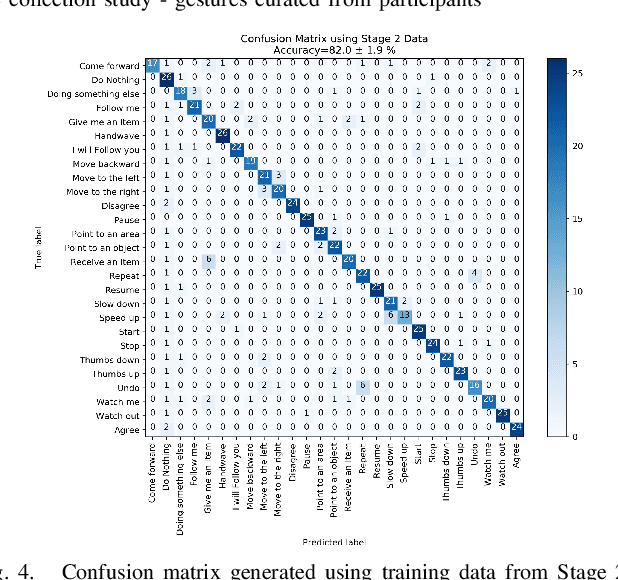
We propose a set of communicative gestures and develop a gesture recognition system with the aim of facilitating more intuitive Human-Robot Interaction (HRI) through gestures. First, we propose a set of commands commonly used for human-robot interaction. Next, an online user study with 190 participants was performed to investigate if there was an agreed set of gestures that people intuitively use to communicate the given commands to robots when no guidance or training were given. As we found large variations among the gestures exist between participants, we then proposed a set of gestures for the proposed commands to be used as a common foundation for robot interaction. We collected ~7500 video demonstrations of the proposed gestures and trained a gesture recognition model, adapting 3D Convolutional Neural Networks (CNN) as the classifier, with a final accuracy of 84.1% (sigma=2.4). The resulting model was capable of training successfully with a relatively small amount of training data. We integrated the gesture recognition model into the ROS framework and report details for a demonstrated use case, where a person commands a robot to perform a pick and place task using the proposed set. This integrated ROS gesture recognition system is made available for use, and built with the intention to allow for new adaptations depending on robot model and use case scenarios, for novel user applications.
An Experimental Validation and Comparison of Reaching Motion Models for Unconstrained Handovers: Towards Generating Humanlike Motions for Human-Robot Handovers
Aug 29, 2021

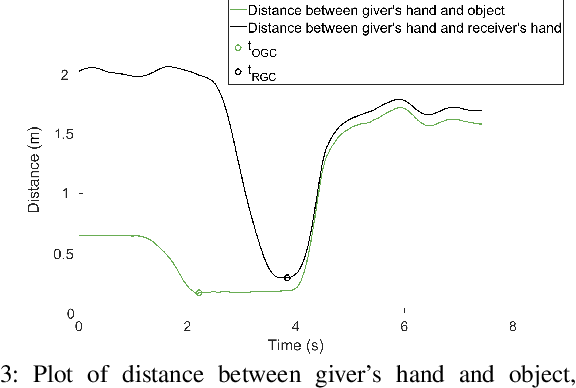
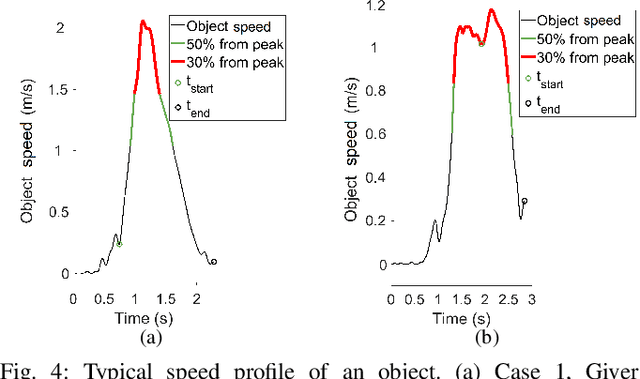
The Minimum Jerk motion model has long been cited in literature for human point-to-point reaching motions in single-person tasks. While it has been demonstrated that applying minimum-jerk-like trajectories to robot reaching motions in the joint action task of human-robot handovers allows a robot giver to be perceived as more careful, safe, and skilled, it has not been verified whether human reaching motions in handovers follow the Minimum Jerk model. To experimentally test and verify motion models for human reaches in handovers, we examined human reaching motions in unconstrained handovers (where the person is allowed to move their whole body) and fitted against 1) the Minimum Jerk model, 2) its variation, the Decoupled Minimum Jerk model, and 3) the recently proposed Elliptical (Conic) model. Results showed that Conic model fits unconstrained human handover reaching motions best. Furthermore, we discovered that unlike constrained, single-person reaching motions, which have been found to be elliptical, there is a split between elliptical and hyperbolic conic types. We expect our results will help guide generation of more humanlike reaching motions for human-robot handover tasks.
Group Surfing: A Pedestrian-Based Approach to Sidewalk Robot Navigation
Apr 13, 2021
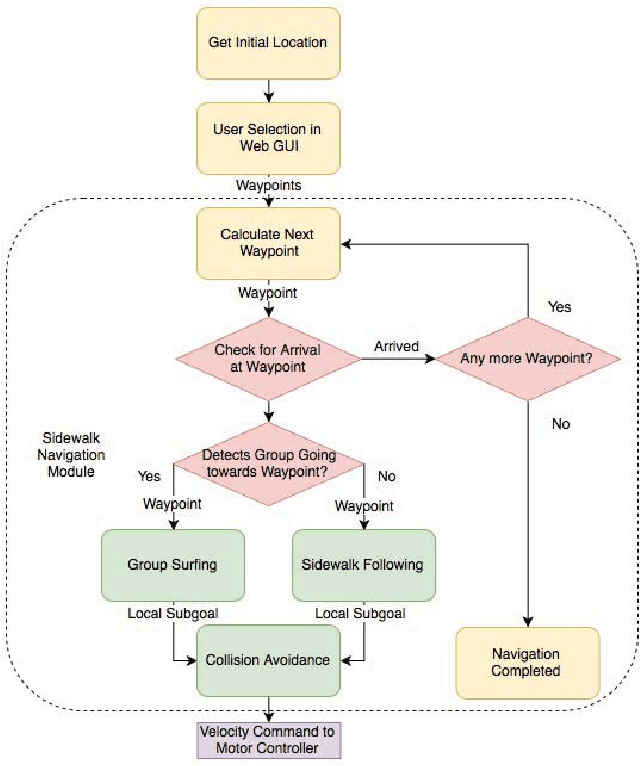
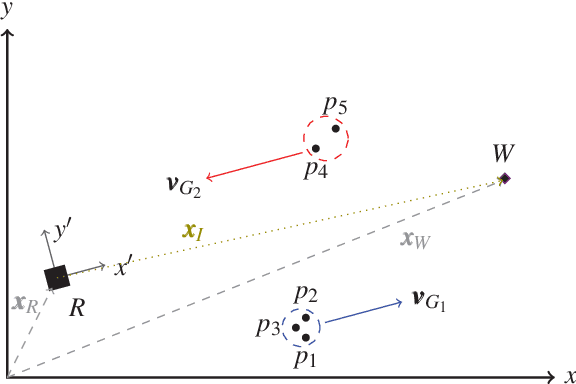
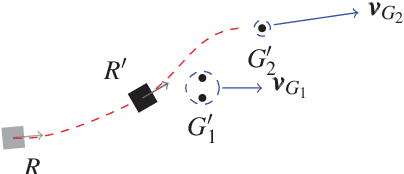
In this paper, we propose a novel navigation system for mobile robots in pedestrian-rich sidewalk environments. Sidewalks are unique in that the pedestrian-shared space has characteristics of both roads and indoor spaces. Like vehicles on roads, pedestrian movement often manifests as linear flows in opposing directions. On the other hand, pedestrians also form crowds and can exhibit much more random movements than vehicles. Classical algorithms are insufficient for safe navigation around pedestrians and remaining on the sidewalk space. Thus, our approach takes advantage of natural human motion to allow a robot to adapt to sidewalk navigation in a safe and socially-compliant manner. We developed a \textit{group surfing} method which aims to imitate the optimal pedestrian group for bringing the robot closer to its goal. For pedestrian-sparse environments, we propose a sidewalk edge detection and following method. Underlying these two navigation methods, the collision avoidance scheme is human-aware. The integrated navigation stack is evaluated and demonstrated in simulation. A hardware demonstration is also presented.
Virtual Barriers in Augmented Reality for Safe and Effective Human-Robot Cooperation in Manufacturing
Apr 12, 2021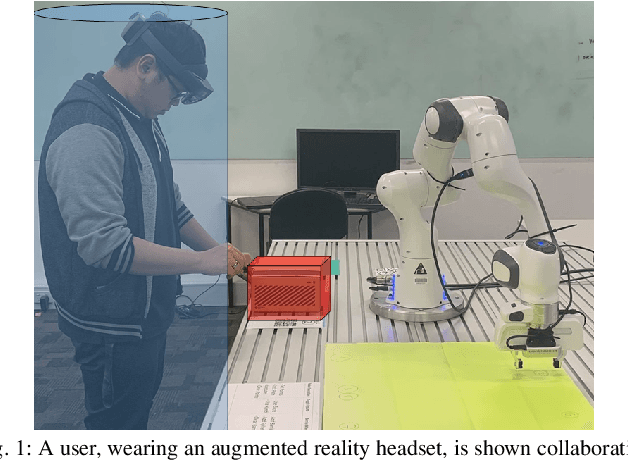
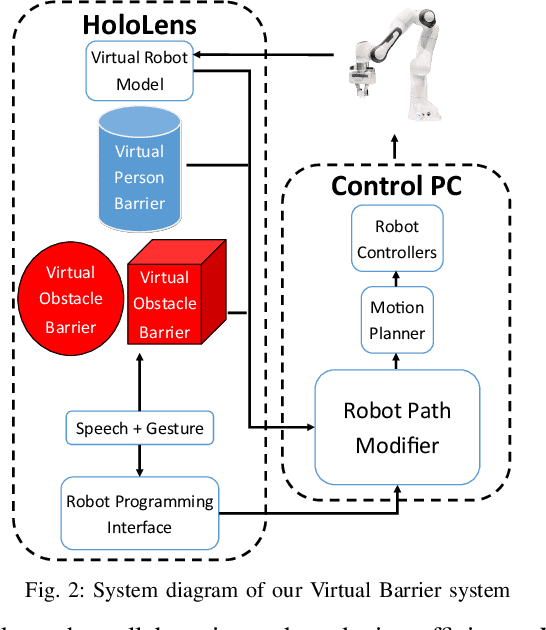


Safety is a fundamental requirement in any human-robot collaboration scenario. To ensure the safety of users for such scenarios, we propose a novel Virtual Barrier system facilitated by an augmented reality interface. Our system provides two kinds of Virtual Barriers to ensure safety: 1) a Virtual Person Barrier which encapsulates and follows the user to protect them from colliding with the robot, and 2) Virtual Obstacle Barriers which users can spawn to protect objects or regions that the robot should not enter. To enable effective human-robot collaboration, our system includes an intuitive robot programming interface utilizing speech commands and hand gestures, and features the capability of automatic path re-planning when potential collisions are detected as a result of a barrier intersecting the robot's planned path. We compared our novel system with a standard 2D display interface through a user study, where participants performed a task mimicking an industrial manufacturing procedure. Results show that our system increases the user's sense of safety and task efficiency, and makes the interaction more intuitive.
Seeing Thru Walls: Visualizing Mobile Robots in Augmented Reality
Apr 08, 2021

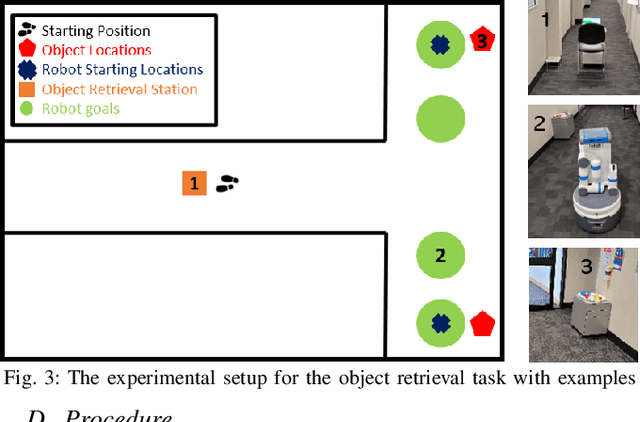

We present an approach for visualizing mobile robots through an Augmented Reality headset when there is no line-of-sight visibility between the robot and the human. Three elements are visualized in Augmented Reality: 1) Robot's 3D model to indicate its position, 2) An arrow emanating from the robot to indicate its planned movement direction, and 3) A 2D grid to represent the ground plane. We conduct a user study with 18 participants, in which each participant are asked to retrieve objects, one at a time, from stations at the two sides of a T-junction at the end of a hallway where a mobile robot is roaming. The results show that visualizations improved the perceived safety and efficiency of the task and led to participants being more comfortable with the robot within their personal spaces. Furthermore, visualizing the motion intent in addition to the robot model was found to be more effective than visualizing the robot model alone. The proposed system can improve the safety of automated warehouses by increasing the visibility and predictability of robots.