 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDemonstration Based Explainable AI for Learning from Demonstration Methods
Oct 10, 2024Learning from Demonstration (LfD) is a powerful type of machine learning that can allow novices to teach and program robots to complete various tasks. However, the learning process for these systems may still be difficult for novices to interpret and understand, making effective teaching challenging. Explainable artificial intelligence (XAI) aims to address this challenge by explaining a system to the user. In this work, we investigate XAI within LfD by implementing an adaptive explanatory feedback system on an inverse reinforcement learning (IRL) algorithm. The feedback is implemented by demonstrating selected learnt trajectories to users. The system adapts to user teaching by categorizing and then selectively sampling trajectories shown to a user, to show a representative sample of both successful and unsuccessful trajectories. The system was evaluated through a user study with 26 participants teaching a robot a navigation task. The results of the user study demonstrated that the proposed explanatory feedback system can improve robot performance, teaching efficiency and user understanding of the robot.
Deep Learning Approaches to Grasp Synthesis: A Review
Jul 06, 2022


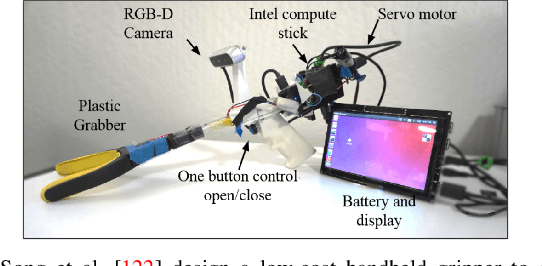
Grasping is the process of picking an object by applying forces and torques at a set of contacts. Recent advances in deep-learning methods have allowed rapid progress in robotic object grasping. We systematically surveyed the publications over the last decade, with a particular interest in grasping an object using all 6 degrees of freedom of the end-effector pose. Our review found four common methodologies for robotic grasping: sampling-based approaches, direct regression, reinforcement learning, and exemplar approaches. Furthermore, we found two 'supporting methods' around grasping that use deep-learning to support the grasping process, shape approximation, and affordances. We have distilled the publications found in this systematic review (85 papers) into ten key takeaways we consider crucial for future robotic grasping and manipulation research. An online version of the survey is available at https://rhys-newbury.github.io/projects/6dof/
Integrating High-Resolution Tactile Sensing into Grasp Stability Prediction
Jun 12, 2022

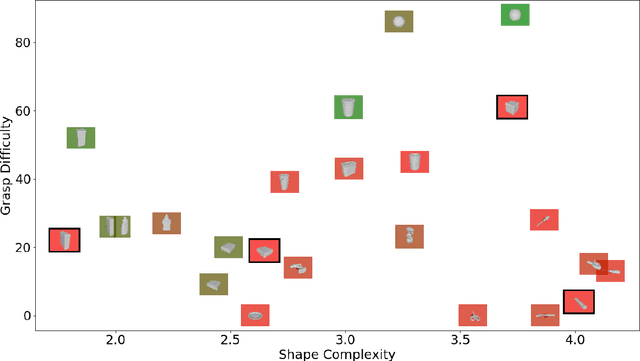
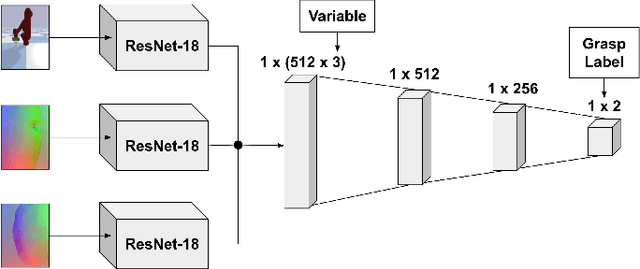
We investigate how high-resolution tactile sensors can be utilized in combination with vision and depth sensing, to improve grasp stability prediction. Recent advances in simulating high-resolution tactile sensing, in particular the TACTO simulator, enabled us to evaluate how neural networks can be trained with a combination of sensing modalities. With the large amounts of data needed to train large neural networks, robotic simulators provide a fast way to automate the data collection process. We expand on the existing work through an ablation study and an increased set of objects taken from the YCB benchmark set. Our results indicate that while the combination of vision, depth, and tactile sensing provides the best prediction results on known objects, the network fails to generalize to unknown objects. Our work also addresses existing issues with robotic grasping in tactile simulation and how to overcome them.
AR Point&Click: An Interface for Setting Robot Navigation Goals
Mar 29, 2022


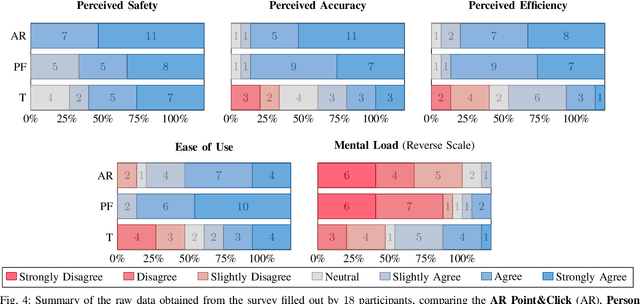
This paper considers the problem of designating navigation goal locations for interactive mobile robots. We propose a point-and-click interface, implemented with an Augmented Reality (AR) headset. The cameras on the AR headset are used to detect natural pointing gestures performed by the user. The selected goal is visualized through the AR headset, allowing the users to adjust the goal location if desired. We conduct a user study in which participants set consecutive navigation goals for the robot using three different interfaces: AR Point & Click, Person Following and Tablet (birdeye map view). Results show that the proposed AR Point&Click interface improved the perceived accuracy, efficiency and reduced mental load compared to the baseline tablet interface, and it performed on-par to the Person Following method. These results show that the AR Point\&Click is a feasible interaction model for setting navigation goals.
Seeing Thru Walls: Visualizing Mobile Robots in Augmented Reality
Apr 08, 2021

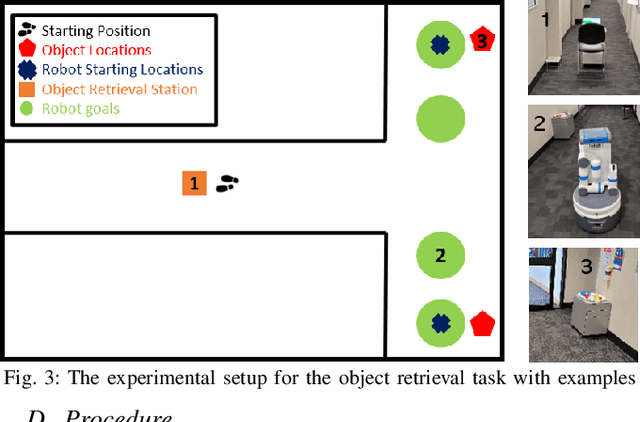

We present an approach for visualizing mobile robots through an Augmented Reality headset when there is no line-of-sight visibility between the robot and the human. Three elements are visualized in Augmented Reality: 1) Robot's 3D model to indicate its position, 2) An arrow emanating from the robot to indicate its planned movement direction, and 3) A 2D grid to represent the ground plane. We conduct a user study with 18 participants, in which each participant are asked to retrieve objects, one at a time, from stations at the two sides of a T-junction at the end of a hallway where a mobile robot is roaming. The results show that visualizations improved the perceived safety and efficiency of the task and led to participants being more comfortable with the robot within their personal spaces. Furthermore, visualizing the motion intent in addition to the robot model was found to be more effective than visualizing the robot model alone. The proposed system can improve the safety of automated warehouses by increasing the visibility and predictability of robots.