 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMind the Performance Gap: Examining Dataset Shift During Prospective Validation
Jul 23, 2021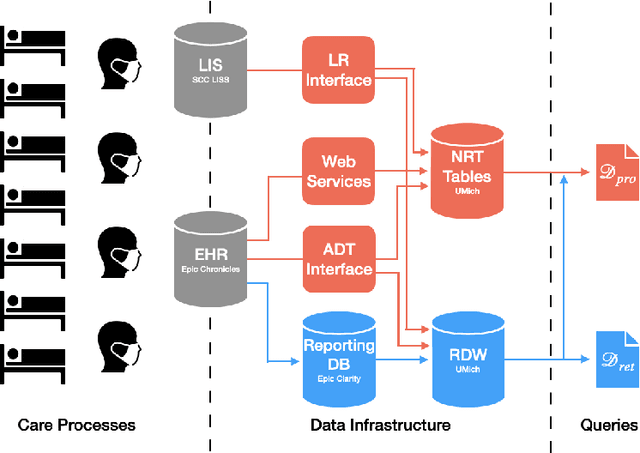
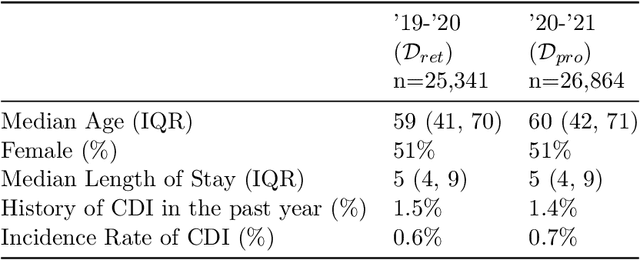
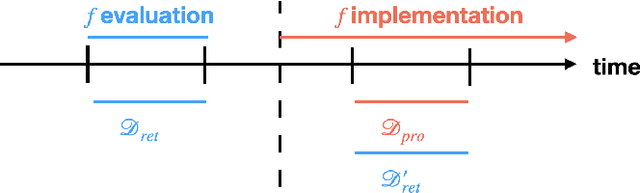

Once integrated into clinical care, patient risk stratification models may perform worse compared to their retrospective performance. To date, it is widely accepted that performance will degrade over time due to changes in care processes and patient populations. However, the extent to which this occurs is poorly understood, in part because few researchers report prospective validation performance. In this study, we compare the 2020-2021 ('20-'21) prospective performance of a patient risk stratification model for predicting healthcare-associated infections to a 2019-2020 ('19-'20) retrospective validation of the same model. We define the difference in retrospective and prospective performance as the performance gap. We estimate how i) "temporal shift", i.e., changes in clinical workflows and patient populations, and ii) "infrastructure shift", i.e., changes in access, extraction and transformation of data, both contribute to the performance gap. Applied prospectively to 26,864 hospital encounters during a twelve-month period from July 2020 to June 2021, the model achieved an area under the receiver operating characteristic curve (AUROC) of 0.767 (95% confidence interval (CI): 0.737, 0.801) and a Brier score of 0.189 (95% CI: 0.186, 0.191). Prospective performance decreased slightly compared to '19-'20 retrospective performance, in which the model achieved an AUROC of 0.778 (95% CI: 0.744, 0.815) and a Brier score of 0.163 (95% CI: 0.161, 0.165). The resulting performance gap was primarily due to infrastructure shift and not temporal shift. So long as we continue to develop and validate models using data stored in large research data warehouses, we must consider differences in how and when data are accessed, measure how these differences may affect prospective performance, and work to mitigate those differences.