 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAligning Agents via Planning: A Benchmark for Trajectory-Level Reward Modeling
Apr 09, 2026In classical Reinforcement Learning from Human Feedback (RLHF), Reward Models (RMs) serve as the fundamental signal provider for model alignment. As Large Language Models evolve into agentic systems capable of autonomous tool invocation and complex reasoning, the paradigm of reward modeling faces unprecedented challenges--most notably, the lack of benchmarks specifically designed to assess RM capabilities within tool-integrated environments. To address this gap, we present Plan-RewardBench, a trajectory-level preference benchmark designed to evaluate how well judges distinguish preferred versus distractor agent trajectories in complex tool-using scenarios. Plan-RewardBench covers four representative task families -- (i) Safety Refusal, (ii) Tool-Irrelevance / Unavailability, (iii) Complex Planning, and (iv) Robust Error Recovery -- comprising validated positive trajectories and confusable hard negatives constructed via multi-model natural rollouts, rule-based perturbations, and minimal-edit LLM perturbations. We benchmark representative RMs (generative, discriminative, and LLM-as-Judge) under a unified pairwise protocol, reporting accuracy trends across varying trajectory lengths and task categories. Furthermore, we provide diagnostic analyses of prevalent failure modes. Our results reveal that all three evaluator families face substantial challenges, with performance degrading sharply on long-horizon trajectories, underscoring the necessity for specialized training in agentic, trajectory-level reward modeling. Ultimately, Plan-RewardBench aims to serve as both a practical evaluation suite and a reusable blueprint for constructing agentic planning preference data.
TTT-Parkour: Rapid Test-Time Training for Perceptive Robot Parkour
Feb 02, 2026Achieving highly dynamic humanoid parkour on unseen, complex terrains remains a challenge in robotics. Although general locomotion policies demonstrate capabilities across broad terrain distributions, they often struggle with arbitrary and highly challenging environments. To overcome this limitation, we propose a real-to-sim-to-real framework that leverages rapid test-time training (TTT) on novel terrains, significantly enhancing the robot's capability to traverse extremely difficult geometries. We adopt a two-stage end-to-end learning paradigm: a policy is first pre-trained on diverse procedurally generated terrains, followed by rapid fine-tuning on high-fidelity meshes reconstructed from real-world captures. Specifically, we develop a feed-forward, efficient, and high-fidelity geometry reconstruction pipeline using RGB-D inputs, ensuring both speed and quality during test-time training. We demonstrate that TTT-Parkour empowers humanoid robots to master complex obstacles, including wedges, stakes, boxes, trapezoids, and narrow beams. The whole pipeline of capturing, reconstructing, and test-time training requires less than 10 minutes on most tested terrains. Extensive experiments show that the policy after test-time training exhibits robust zero-shot sim-to-real transfer capability.
Predictive Response Optimization: Using Reinforcement Learning to Fight Online Social Network Abuse
Feb 24, 2025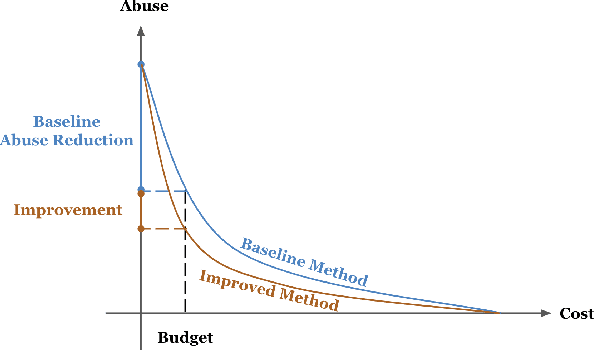

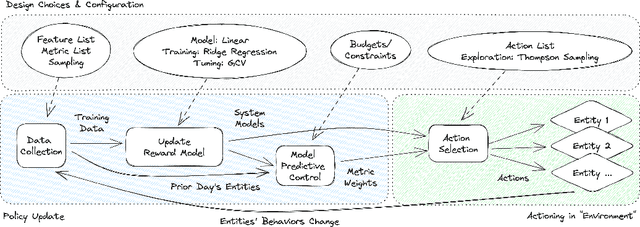
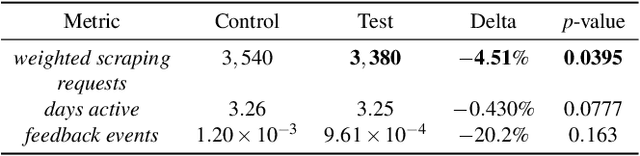
Detecting phishing, spam, fake accounts, data scraping, and other malicious activity in online social networks (OSNs) is a problem that has been studied for well over a decade, with a number of important results. Nearly all existing works on abuse detection have as their goal producing the best possible binary classifier; i.e., one that labels unseen examples as "benign" or "malicious" with high precision and recall. However, no prior published work considers what comes next: what does the service actually do after it detects abuse? In this paper, we argue that detection as described in previous work is not the goal of those who are fighting OSN abuse. Rather, we believe the goal to be selecting actions (e.g., ban the user, block the request, show a CAPTCHA, or "collect more evidence") that optimize a tradeoff between harm caused by abuse and impact on benign users. With this framing, we see that enlarging the set of possible actions allows us to move the Pareto frontier in a way that is unattainable by simply tuning the threshold of a binary classifier. To demonstrate the potential of our approach, we present Predictive Response Optimization (PRO), a system based on reinforcement learning that utilizes available contextual information to predict future abuse and user-experience metrics conditioned on each possible action, and select actions that optimize a multi-dimensional tradeoff between abuse/harm and impact on user experience. We deployed versions of PRO targeted at stopping automated activity on Instagram and Facebook. In both cases our experiments showed that PRO outperforms a baseline classification system, reducing abuse volume by 59% and 4.5% (respectively) with no negative impact to users. We also present several case studies that demonstrate how PRO can quickly and automatically adapt to changes in business constraints, system behavior, and/or adversarial tactics.
Structure PLP-SLAM: Efficient Sparse Mapping and Localization using Point, Line and Plane for Monocular, RGB-D and Stereo Cameras
Jul 19, 2022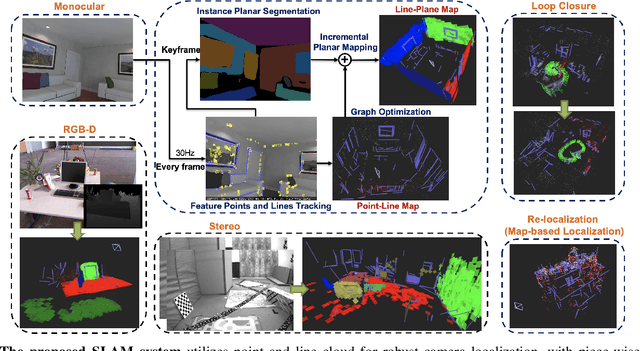
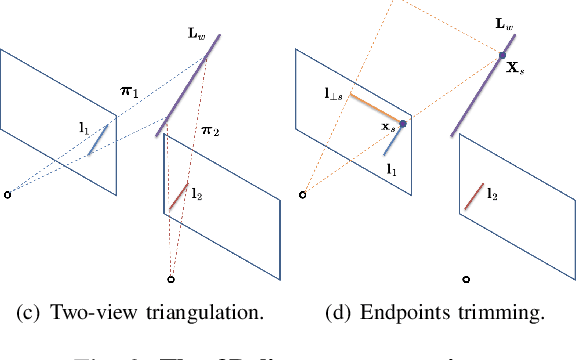
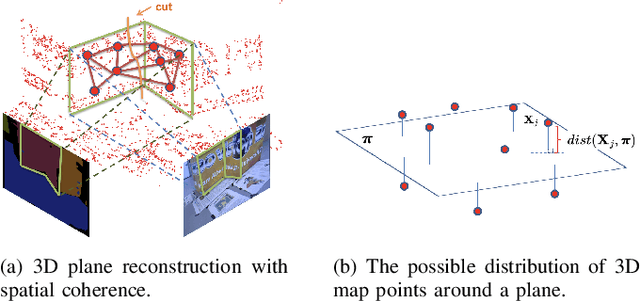

This paper demonstrates a visual SLAM system that utilizes point and line cloud for robust camera localization, simultaneously, with an embedded piece-wise planar reconstruction (PPR) module which in all provides a structural map. To build a scale consistent map in parallel with tracking, such as employing a single camera brings the challenge of reconstructing geometric primitives with scale ambiguity, and further introduces the difficulty in graph optimization of bundle adjustment (BA). We address these problems by proposing several run-time optimizations on the reconstructed lines and planes. The system is then extended with depth and stereo sensors based on the design of the monocular framework. The results show that our proposed SLAM tightly incorporates the semantic features to boost both frontend tracking as well as backend optimization. We evaluate our system exhaustively on various datasets, and open-source our code for the community (https://github.com/PeterFWS/Structure-PLP-SLAM).
Shapley Flow: A Graph-based Approach to Interpreting Model Predictions
Nov 13, 2020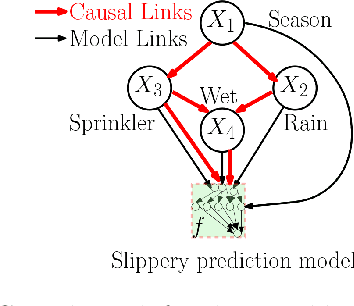
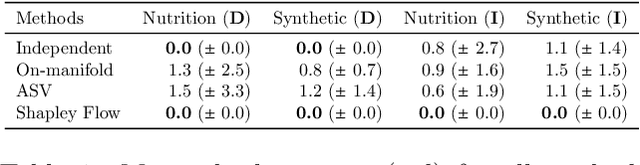
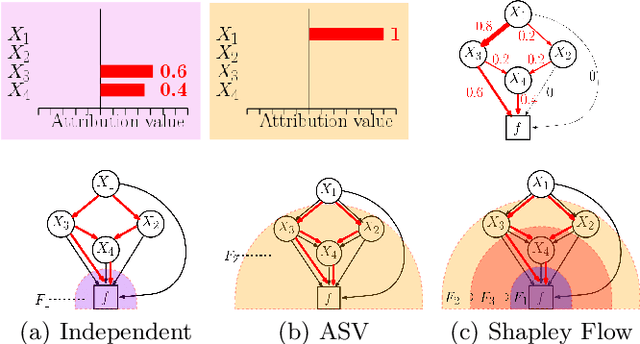
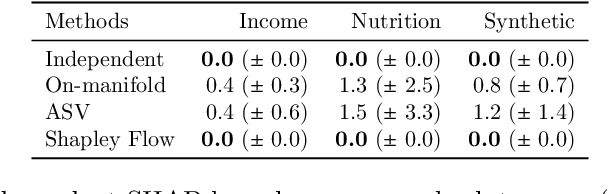
Many existing approaches for estimating feature importance are problematic because they ignore or hide dependencies among features. A causal graph, which encodes the relationships among input variables, can aid in assigning feature importance. However, current approaches that assign credit to nodes in the causal graph fail to explain the entire graph. In light of these limitations, we propose Shapley Flow, a novel approach to interpreting machine learning models. It considers the entire causal graph, and assigns credit to \textit{edges} instead of treating nodes as the fundamental unit of credit assignment. Shapley Flow is the unique solution to a generalization of the Shapley value axioms to directed acyclic graphs. We demonstrate the benefit of using Shapley Flow to reason about the impact of a model's input on its output. In addition to maintaining insights from existing approaches, Shapley Flow extends the flat, set-based, view prevalent in game theory based explanation methods to a deeper, \textit{graph-based}, view. This graph-based view enables users to understand the flow of importance through a system, and reason about potential interventions.
AdaSGD: Bridging the gap between SGD and Adam
Jun 30, 2020
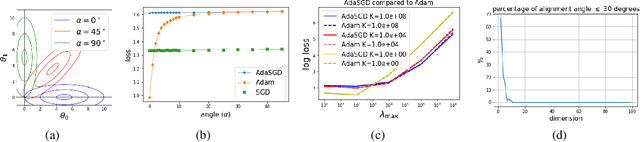
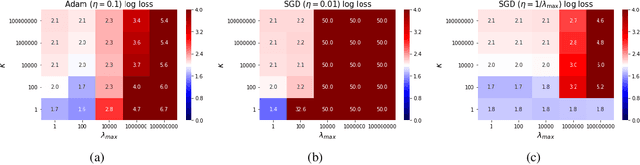
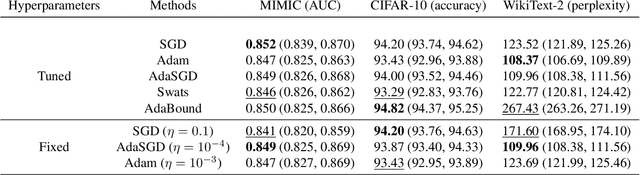
In the context of stochastic gradient descent(SGD) and adaptive moment estimation (Adam),researchers have recently proposed optimization techniques that transition from Adam to SGD with the goal of improving both convergence and generalization performance. However, precisely how each approach trades off early progress and generalization is not well understood; thus, it is unclear when or even if, one should transition from one approach to the other. In this work, by first studying the convex setting, we identify potential contributors to observed differences in performance between SGD and Adam. In particular,we provide theoretical insights for when and why Adam outperforms SGD and vice versa. We ad-dress the performance gap by adapting a single global learning rate for SGD, which we refer to as AdaSGD. We justify this proposed approach with empirical analyses in non-convex settings. On several datasets that span three different domains,we demonstrate how AdaSGD combines the benefits of both SGD and Adam, eliminating the need for approaches that transition from Adam to SGD.
Relaxed Weight Sharing: Effectively Modeling Time-Varying Relationships in Clinical Time-Series
Jun 07, 2019
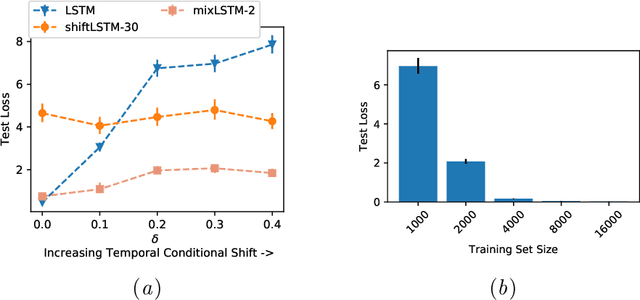
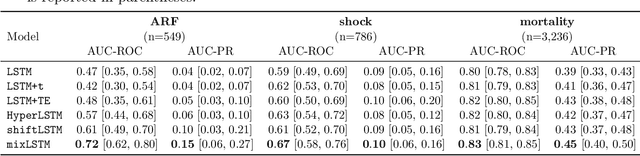
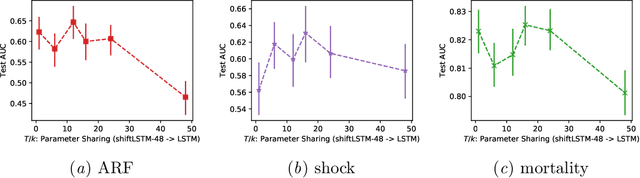
Recurrent neural networks (RNNs) are commonly applied to clinical time-series data with the goal of learning patient risk stratification models. Their effectiveness is due, in part, to their use of parameter sharing over time (i.e., cells are repeated hence the name recurrent). We hypothesize, however, that this trait also contributes to the increased difficulty such models have with learning relationships that change over time. Conditional shift, i.e., changes in the relationship between the input X and the output y, arises if the risk factors for the event of interest change over the course of a patient admission. While in theory, RNNs and gated RNNs (e.g., LSTMs) in particular should be capable of learning time-varying relationships, when training data are limited, such models often fail to accurately capture these dynamics. We illustrate the advantages and disadvantages of complete weight sharing (RNNs) by comparing an LSTM with shared parameters to a sequential architecture with time-varying parameters on three clinically-relevant prediction tasks: acute respiratory failure (ARF), shock, and in-hospital mortality. In experiments using synthetic data, we demonstrate how weight sharing in LSTMs leads to worse performance in the presence of conditional shift. To improve upon the dichotomy between complete weight sharing vs. no weight sharing, we propose a novel RNN formulation based on a mixture model in which we relax weight sharing over time. The proposed method outperforms standard LSTMs and other state-of-the-art baselines across all tasks. In settings with limited data, relaxed weight sharing can lead to improved patient risk stratification performance.
Learning to Exploit Invariances in Clinical Time-Series Data using Sequence Transformer Networks
Aug 21, 2018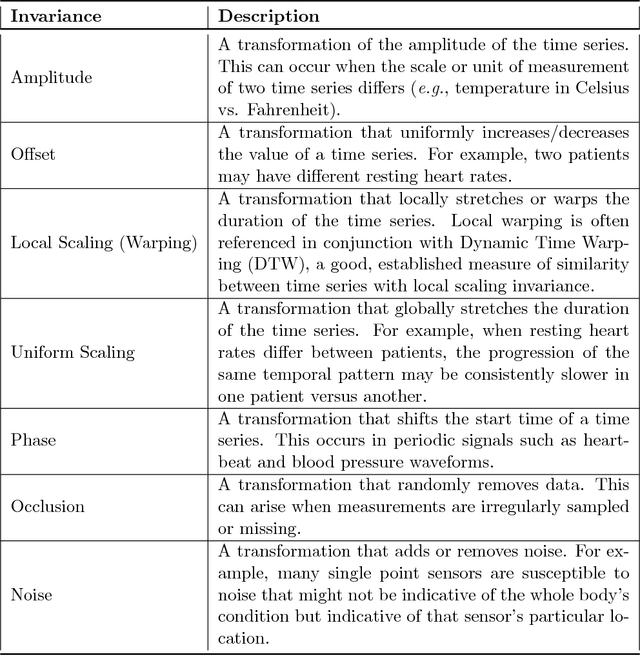
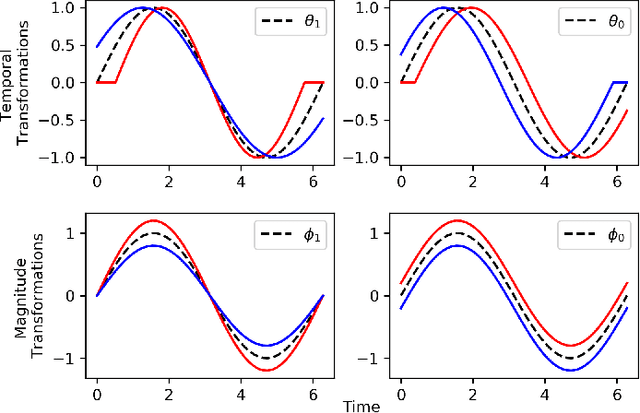
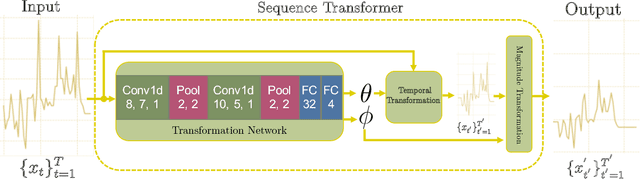
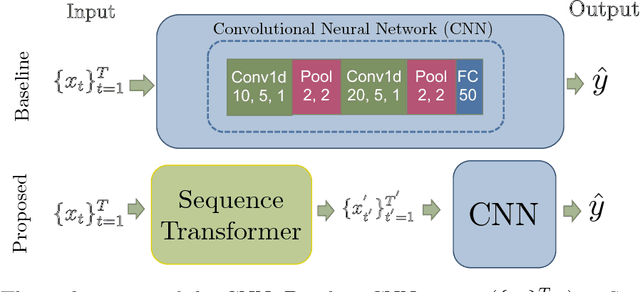
Recently, researchers have started applying convolutional neural networks (CNNs) with one-dimensional convolutions to clinical tasks involving time-series data. This is due, in part, to their computational efficiency, relative to recurrent neural networks and their ability to efficiently exploit certain temporal invariances, (e.g., phase invariance). However, it is well-established that clinical data may exhibit many other types of invariances (e.g., scaling). While preprocessing techniques, (e.g., dynamic time warping) may successfully transform and align inputs, their use often requires one to identify the types of invariances in advance. In contrast, we propose the use of Sequence Transformer Networks, an end-to-end trainable architecture that learns to identify and account for invariances in clinical time-series data. Applied to the task of predicting in-hospital mortality, our proposed approach achieves an improvement in the area under the receiver operating characteristic curve (AUROC) relative to a baseline CNN (AUROC=0.851 vs. AUROC=0.838). Our results suggest that a variety of valuable invariances can be learned directly from the data.
Learning Credible Models
Jun 07, 2018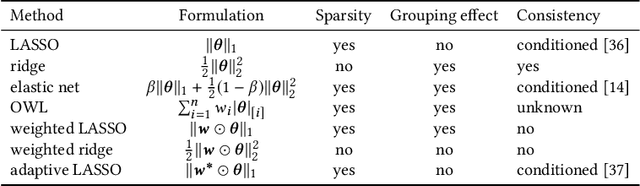
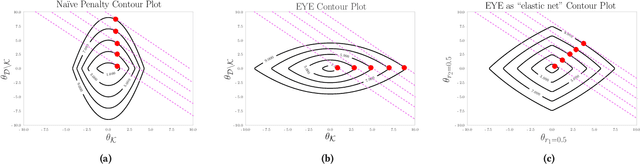
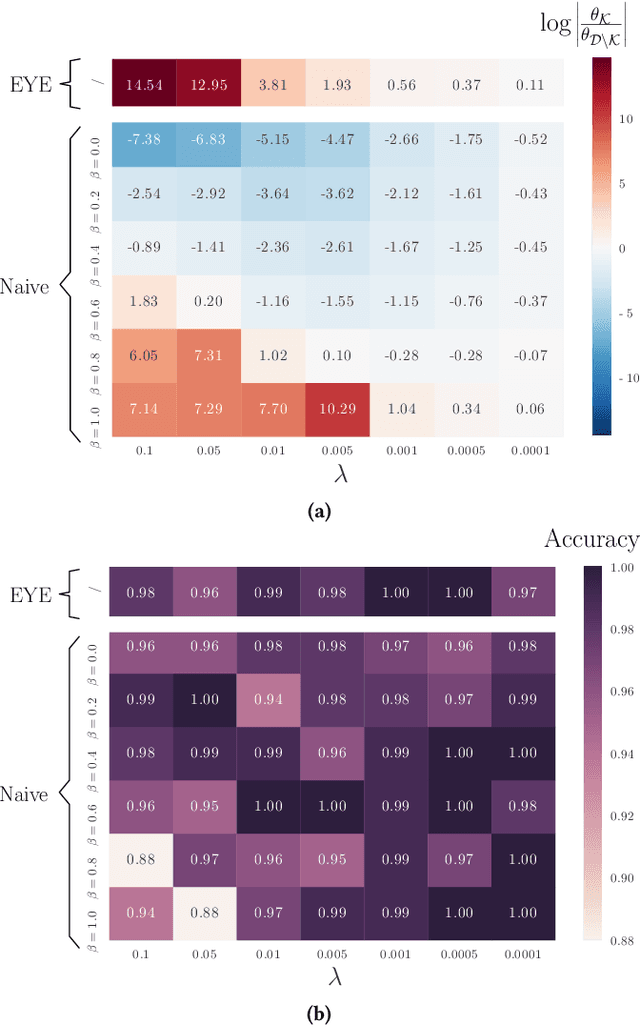
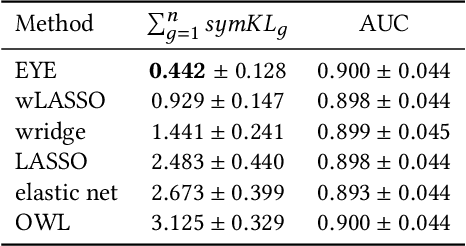
In many settings, it is important that a model be capable of providing reasons for its predictions (i.e., the model must be interpretable). However, the model's reasoning may not conform with well-established knowledge. In such cases, while interpretable, the model lacks \textit{credibility}. In this work, we formally define credibility in the linear setting and focus on techniques for learning models that are both accurate and credible. In particular, we propose a regularization penalty, expert yielded estimates (EYE), that incorporates expert knowledge about well-known relationships among covariates and the outcome of interest. We give both theoretical and empirical results comparing our proposed method to several other regularization techniques. Across a range of settings, experiments on both synthetic and real data show that models learned using the EYE penalty are significantly more credible than those learned using other penalties. Applied to a large-scale patient risk stratification task, our proposed technique results in a model whose top features overlap significantly with known clinical risk factors, while still achieving good predictive performance.
The Advantage of Doubling: A Deep Reinforcement Learning Approach to Studying the Double Team in the NBA
Mar 08, 2018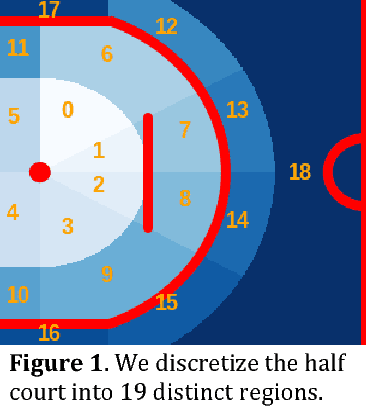
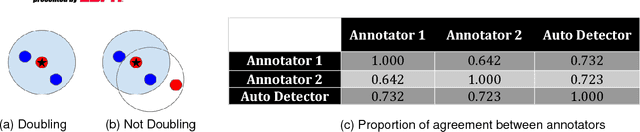

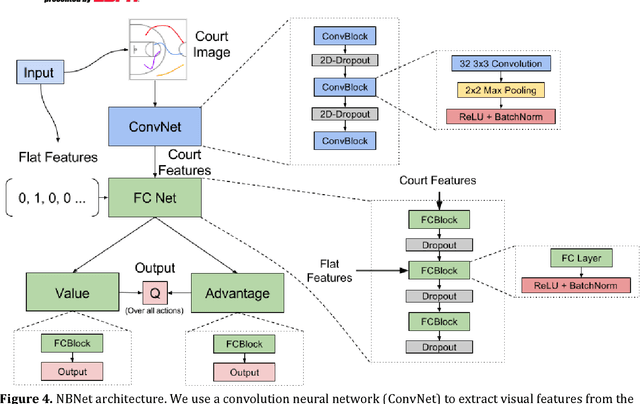
During the 2017 NBA playoffs, Celtics coach Brad Stevens was faced with a difficult decision when defending against the Cavaliers: "Do you double and risk giving up easy shots, or stay at home and do the best you can?" It's a tough call, but finding a good defensive strategy that effectively incorporates doubling can make all the difference in the NBA. In this paper, we analyze double teaming in the NBA, quantifying the trade-off between risk and reward. Using player trajectory data pertaining to over 643,000 possessions, we identified when the ball handler was double teamed. Given these data and the corresponding outcome (i.e., was the defense successful), we used deep reinforcement learning to estimate the quality of the defensive actions. We present qualitative and quantitative results summarizing our learned defensive strategy for defending. We show that our policy value estimates are predictive of points per possession and win percentage. Overall, the proposed framework represents a step toward a more comprehensive understanding of defensive strategies in the NBA.