 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredictive Response Optimization: Using Reinforcement Learning to Fight Online Social Network Abuse
Feb 24, 2025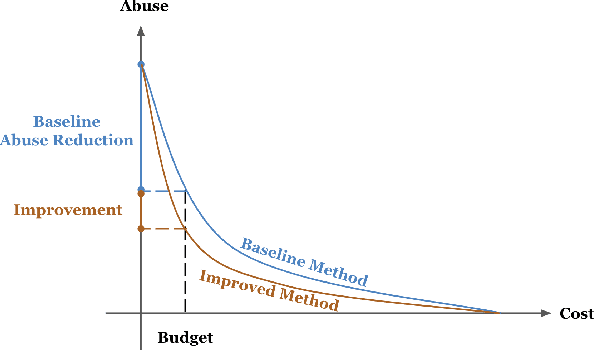

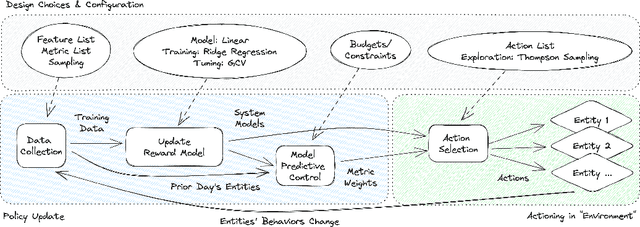
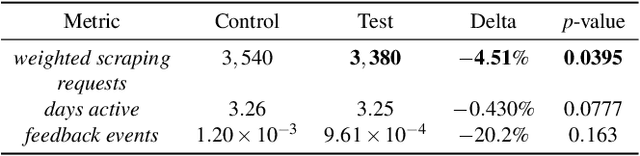
Detecting phishing, spam, fake accounts, data scraping, and other malicious activity in online social networks (OSNs) is a problem that has been studied for well over a decade, with a number of important results. Nearly all existing works on abuse detection have as their goal producing the best possible binary classifier; i.e., one that labels unseen examples as "benign" or "malicious" with high precision and recall. However, no prior published work considers what comes next: what does the service actually do after it detects abuse? In this paper, we argue that detection as described in previous work is not the goal of those who are fighting OSN abuse. Rather, we believe the goal to be selecting actions (e.g., ban the user, block the request, show a CAPTCHA, or "collect more evidence") that optimize a tradeoff between harm caused by abuse and impact on benign users. With this framing, we see that enlarging the set of possible actions allows us to move the Pareto frontier in a way that is unattainable by simply tuning the threshold of a binary classifier. To demonstrate the potential of our approach, we present Predictive Response Optimization (PRO), a system based on reinforcement learning that utilizes available contextual information to predict future abuse and user-experience metrics conditioned on each possible action, and select actions that optimize a multi-dimensional tradeoff between abuse/harm and impact on user experience. We deployed versions of PRO targeted at stopping automated activity on Instagram and Facebook. In both cases our experiments showed that PRO outperforms a baseline classification system, reducing abuse volume by 59% and 4.5% (respectively) with no negative impact to users. We also present several case studies that demonstrate how PRO can quickly and automatically adapt to changes in business constraints, system behavior, and/or adversarial tactics.
Domain Adaptation Under Behavioral and Temporal Shifts for Natural Time Series Mobile Activity Recognition
Jul 10, 2022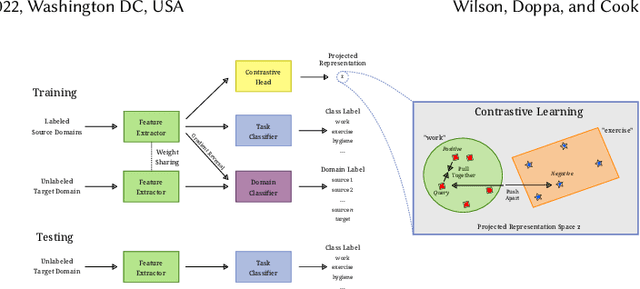
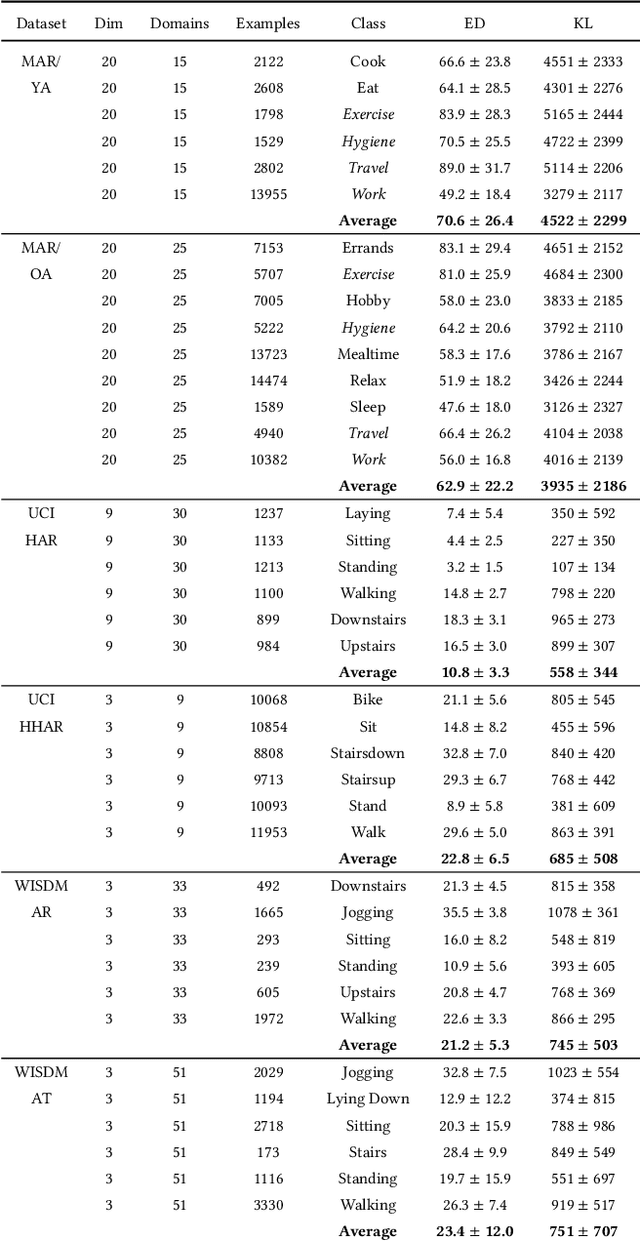
Increasingly, human behavior is captured on mobile devices, leading to an increased interest in automated human activity recognition. However, existing datasets typically consist of scripted movements. Our long-term goal is to perform mobile activity recognition in natural settings. We collect a dataset to support this goal with activity categories that are relevant for downstream tasks such as health monitoring and intervention. Because of the large variations present in human behavior, we collect data from many participants across two different age groups. Because human behavior can change over time, we also collect data from participants over a month's time to capture the temporal drift. We hypothesize that mobile activity recognition can benefit from unsupervised domain adaptation algorithms. To address this need and test this hypothesis, we analyze the performance of domain adaptation across people and across time. We then enhance unsupervised domain adaptation with contrastive learning and with weak supervision when label proportions are available. The dataset is available at https://github.com/WSU-CASAS/smartwatch-data
CALDA: Improving Multi-Source Time Series Domain Adaptation with Contrastive Adversarial Learning
Sep 30, 2021
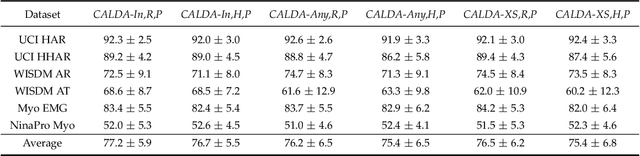
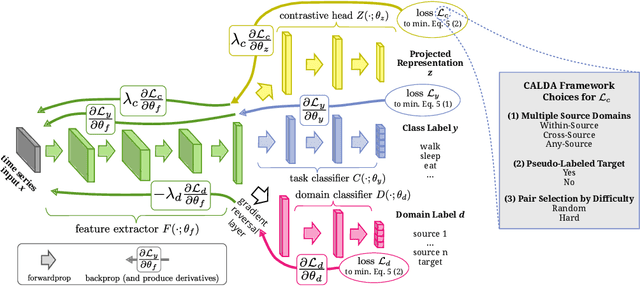
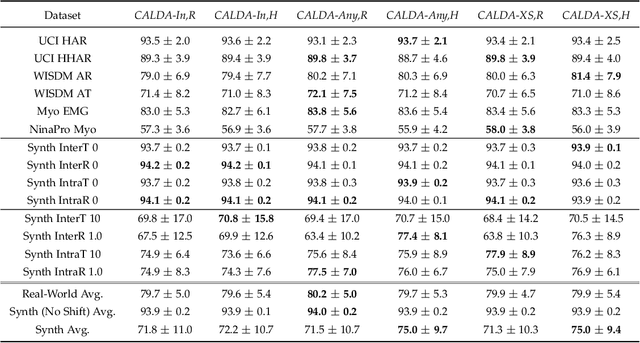
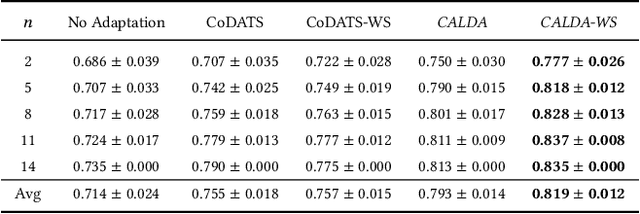
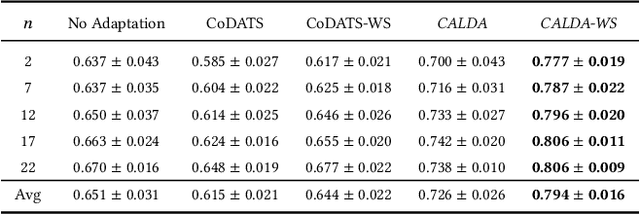
Unsupervised domain adaptation (UDA) provides a strategy for improving machine learning performance in data-rich (target) domains where ground truth labels are inaccessible but can be found in related (source) domains. In cases where meta-domain information such as label distributions is available, weak supervision can further boost performance. We propose a novel framework, CALDA, to tackle these two problems. CALDA synergistically combines the principles of contrastive learning and adversarial learning to robustly support multi-source UDA (MS-UDA) for time series data. Similar to prior methods, CALDA utilizes adversarial learning to align source and target feature representations. Unlike prior approaches, CALDA additionally leverages cross-source label information across domains. CALDA pulls examples with the same label close to each other, while pushing apart examples with different labels, reshaping the space through contrastive learning. Unlike prior contrastive adaptation methods, CALDA requires neither data augmentation nor pseudo labeling, which may be more challenging for time series. We empirically validate our proposed approach. Based on results from human activity recognition, electromyography, and synthetic datasets, we find utilizing cross-source information improves performance over prior time series and contrastive methods. Weak supervision further improves performance, even in the presence of noise, allowing CALDA to offer generalizable strategies for MS-UDA. Code is available at: https://github.com/floft/calda
Multi-Source Deep Domain Adaptation with Weak Supervision for Time-Series Sensor Data
May 22, 2020


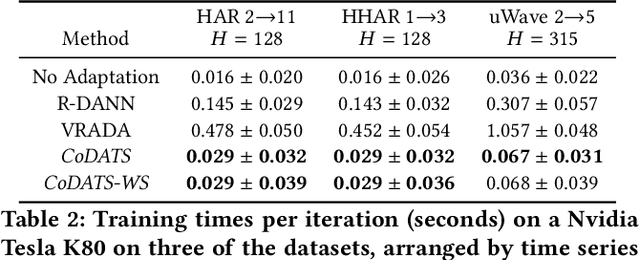
Domain adaptation (DA) offers a valuable means to reuse data and models for new problem domains. However, robust techniques have not yet been considered for time series data with varying amounts of data availability. In this paper, we make three main contributions to fill this gap. First, we propose a novel Convolutional deep Domain Adaptation model for Time Series data (CoDATS) that significantly improves accuracy and training time over state-of-the-art DA strategies on real-world sensor data benchmarks. By utilizing data from multiple source domains, we increase the usefulness of CoDATS to further improve accuracy over prior single-source methods, particularly on complex time series datasets that have high variability between domains. Second, we propose a novel Domain Adaptation with Weak Supervision (DA-WS) method by utilizing weak supervision in the form of target-domain label distributions, which may be easier to collect than additional data labels. Third, we perform comprehensive experiments on diverse real-world datasets to evaluate the effectiveness of our domain adaptation and weak supervision methods. Results show that CoDATS for single-source DA significantly improves over the state-of-the-art methods, and we achieve additional improvements in accuracy using data from multiple source domains and weakly supervised signals. Code is available at: https://github.com/floft/codats
Multi-Purposing Domain Adaptation Discriminators for Pseudo Labeling Confidence
Jul 17, 2019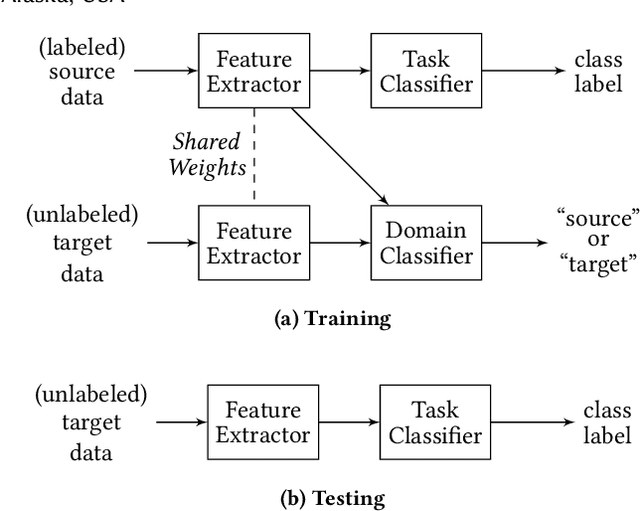
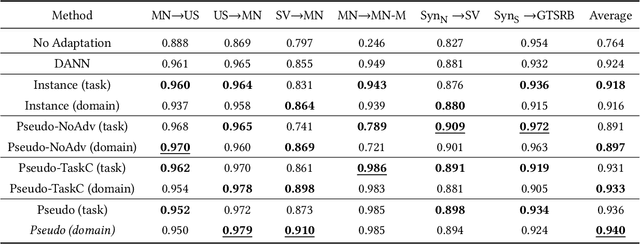
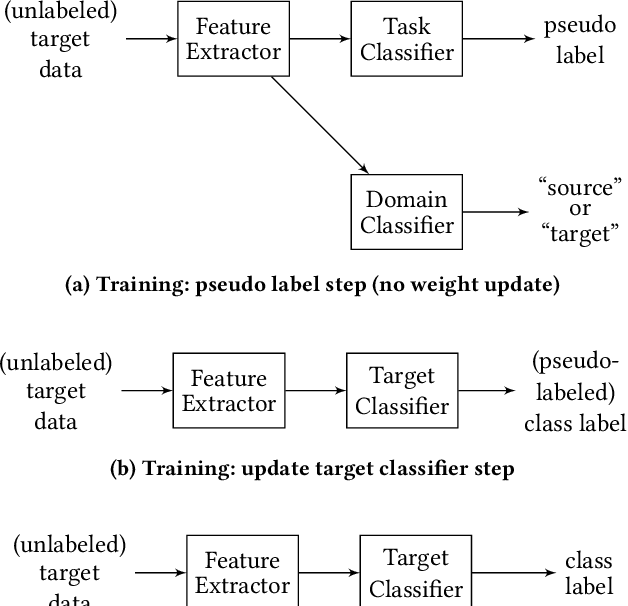
Often domain adaptation is performed using a discriminator (domain classifier) to learn domain-invariant feature representations so that a classifier trained on labeled source data will generalize well to unlabeled target data. A line of research stemming from semi-supervised learning uses pseudo labeling to directly generate "pseudo labels" for the unlabeled target data and trains a classifier on the now-labeled target data, where the samples are selected or weighted based on some measure of confidence. In this paper, we propose multi-purposing the discriminator to not only aid in producing domain-invariant representations but also to provide pseudo labeling confidence.
Adversarial Transfer Learning
Dec 06, 2018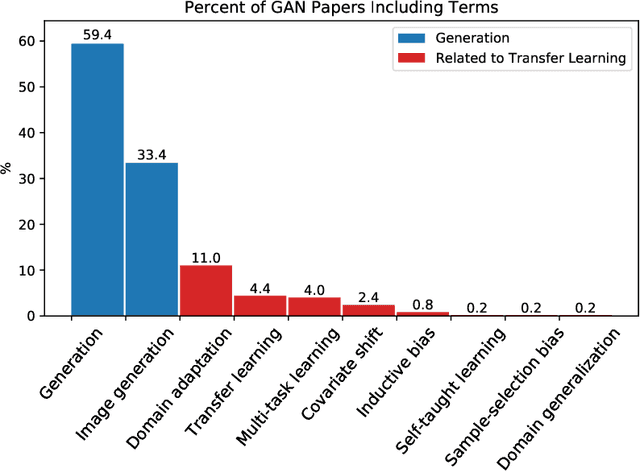


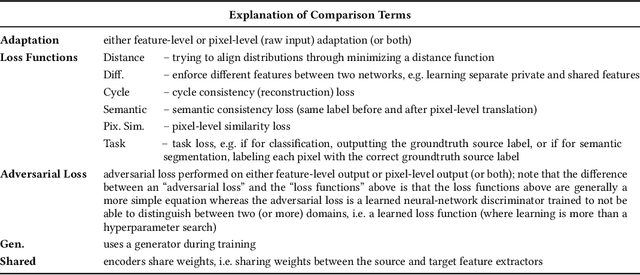
There is a recent large and growing interest in generative adversarial networks (GANs), which offer powerful features for generative modeling, density estimation, and energy function learning. GANs are difficult to train and evaluate but are capable of creating amazingly realistic, though synthetic, image data. Ideas stemming from GANs such as adversarial losses are creating research opportunities for other challenges such as domain adaptation. In this paper, we look at the field of GANs with emphasis on these areas of emerging research. To provide background for adversarial techniques, we survey the field of GANs, looking at the original formulation, training variants, evaluation methods, and extensions. Then we survey recent work on transfer learning, focusing on comparing different adversarial domain adaptation methods. Finally, we take a look forward to identify open research directions for GANs and domain adaptation, including some promising applications such as sensor-based human behavior modeling.