 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersonalized Execution Time Optimization for the Scheduled Jobs
Mar 11, 2022
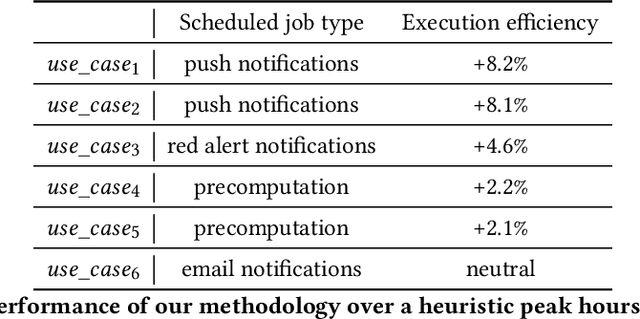
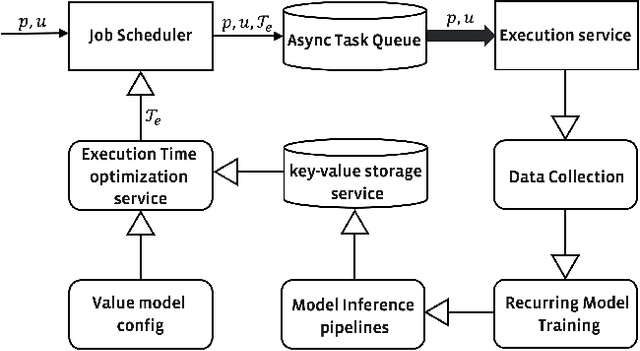

Scheduled batch jobs have been widely used on the asynchronous computing platforms to execute various enterprise applications, including the scheduled notifications and the candidate computation for the modern recommender systems. It is important to deliver or update the information to the users at the right time to maintain the user experience and the execution impact. However, it is challenging to provide a versatile execution time optimization solution for the user-basis scheduled jobs to satisfy various product scenarios while maintaining reasonable infrastructure resource consumption. In this paper, we describe how we apply a pointwise learning-to-rank approach plus a "best time policy" in the best time selection. In addition, we propose a value model approach to efficiently leverage multiple streams of user activity signals in our scheduling decisions of the execution time. Our optimization approach has been successfully tested with production traffic that serves billions of users per day, with statistically significant improvements in various product metrics, including the notifications and content candidate generation. To the best of our knowledge, our study represents the first ML-based multi-tenant solution to the execution time optimization problem for the scheduled jobs at a large industrial scale.
Deep Reinforcement Learning for Closed-Loop Blood Glucose Control
Sep 18, 2020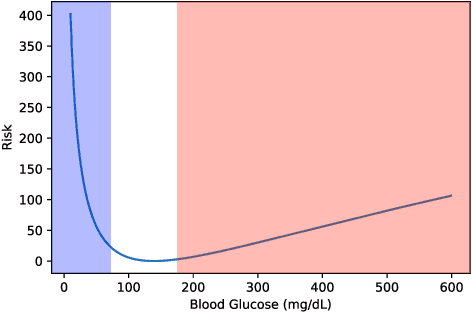
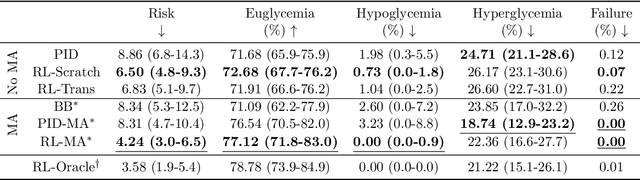

People with type 1 diabetes (T1D) lack the ability to produce the insulin their bodies need. As a result, they must continually make decisions about how much insulin to self-administer to adequately control their blood glucose levels. Longitudinal data streams captured from wearables, like continuous glucose monitors, can help these individuals manage their health, but currently the majority of the decision burden remains on the user. To relieve this burden, researchers are working on closed-loop solutions that combine a continuous glucose monitor and an insulin pump with a control algorithm in an `artificial pancreas.' Such systems aim to estimate and deliver the appropriate amount of insulin. Here, we develop reinforcement learning (RL) techniques for automated blood glucose control. Through a series of experiments, we compare the performance of different deep RL approaches to non-RL approaches. We highlight the flexibility of RL approaches, demonstrating how they can adapt to new individuals with little additional data. On over 2.1 million hours of data from 30 simulated patients, our RL approach outperforms baseline control algorithms: leading to a decrease in median glycemic risk of nearly 50% from 8.34 to 4.24 and a decrease in total time hypoglycemic of 99.8%, from 4,610 days to 6. Moreover, these approaches are able to adapt to predictable meal times (decreasing average risk by an additional 24% as meals increase in predictability). This work demonstrates the potential of deep RL to help people with T1D manage their blood glucose levels without requiring expert knowledge. All of our code is publicly available, allowing for replication and extension.
Advocacy Learning: Learning through Competition and Class-Conditional Representations
Aug 07, 2019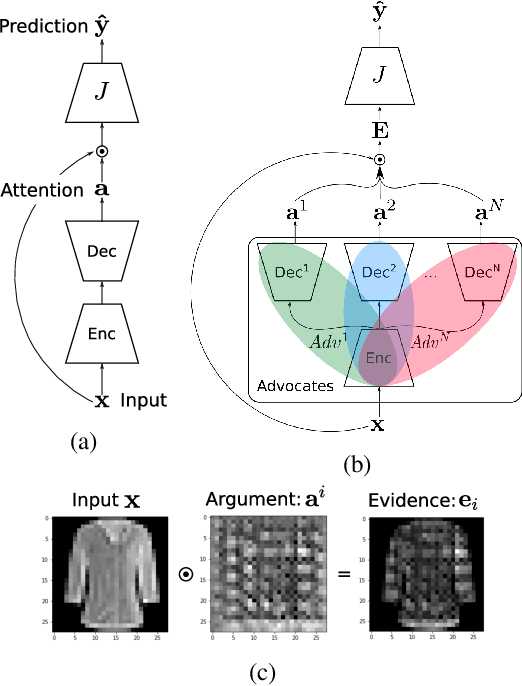
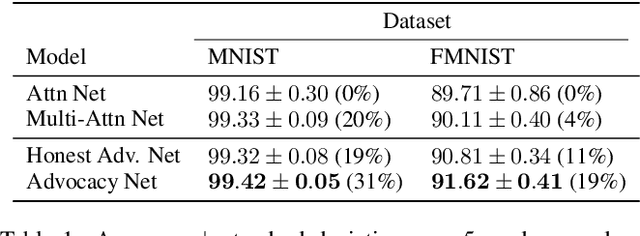
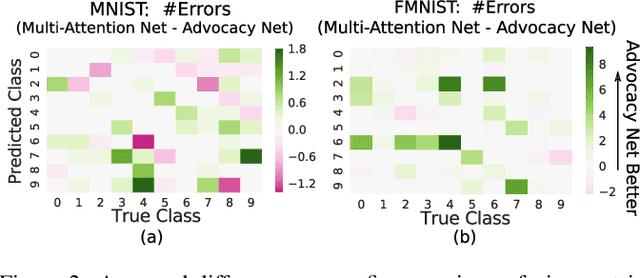
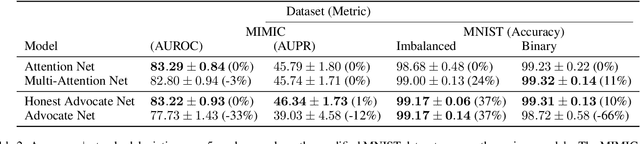
We introduce advocacy learning, a novel supervised training scheme for attention-based classification problems. Advocacy learning relies on a framework consisting of two connected networks: 1) $N$ Advocates (one for each class), each of which outputs an argument in the form of an attention map over the input, and 2) a Judge, which predicts the class label based on these arguments. Each Advocate produces a class-conditional representation with the goal of convincing the Judge that the input example belongs to their class, even when the input belongs to a different class. Applied to several different classification tasks, we show that advocacy learning can lead to small improvements in classification accuracy over an identical supervised baseline. Though a series of follow-up experiments, we analyze when and how such class-conditional representations improve discriminative performance. Though somewhat counter-intuitive, a framework in which subnetworks are trained to competitively provide evidence in support of their class shows promise, in many cases performing on par with standard learning approaches. This provides a foundation for further exploration into competition and class-conditional representations in supervised learning.
Deep Multi-Output Forecasting: Learning to Accurately Predict Blood Glucose Trajectories
Jun 14, 2018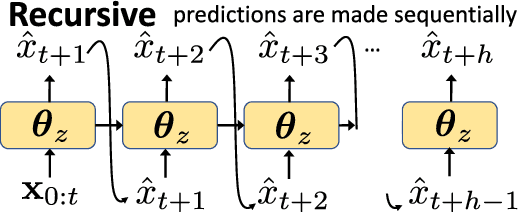
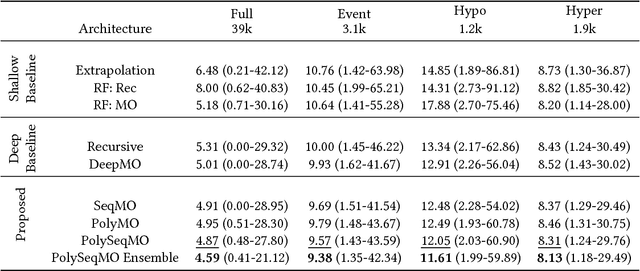
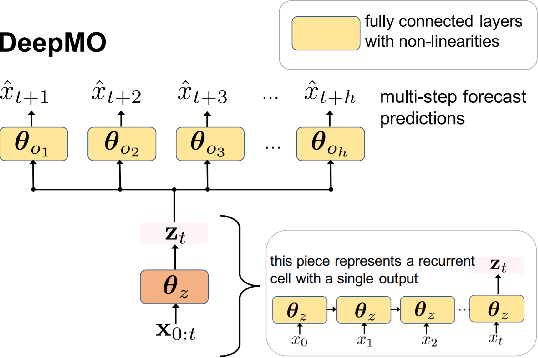
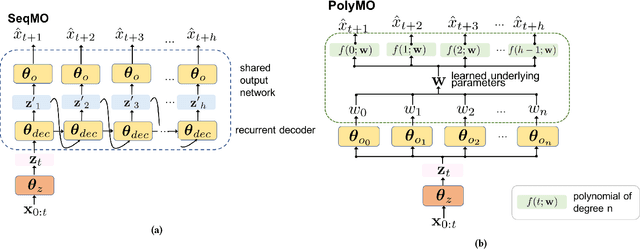
In many forecasting applications, it is valuable to predict not only the value of a signal at a certain time point in the future, but also the values leading up to that point. This is especially true in clinical applications, where the future state of the patient can be less important than the patient's overall trajectory. This requires multi-step forecasting, a forecasting variant where one aims to predict multiple values in the future simultaneously. Standard methods to accomplish this can propagate error from prediction to prediction, reducing quality over the long term. In light of these challenges, we propose multi-output deep architectures for multi-step forecasting in which we explicitly model the distribution of future values of the signal over a prediction horizon. We apply these techniques to the challenging and clinically relevant task of blood glucose forecasting. Through a series of experiments on a real-world dataset consisting of 550K blood glucose measurements, we demonstrate the effectiveness of our proposed approaches in capturing the underlying signal dynamics. Compared to existing shallow and deep methods, we find that our proposed approaches improve performance individually and capture complementary information, leading to a large improvement over the baseline when combined (4.87 vs. 5.31 absolute percentage error (APE)). Overall, the results suggest the efficacy of our proposed approach in predicting blood glucose level and multi-step forecasting more generally.
The Advantage of Doubling: A Deep Reinforcement Learning Approach to Studying the Double Team in the NBA
Mar 08, 2018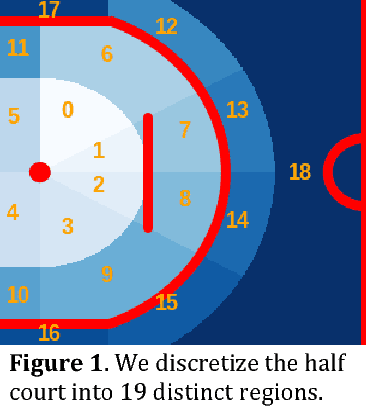
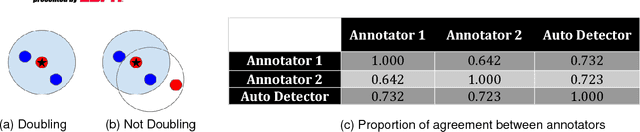

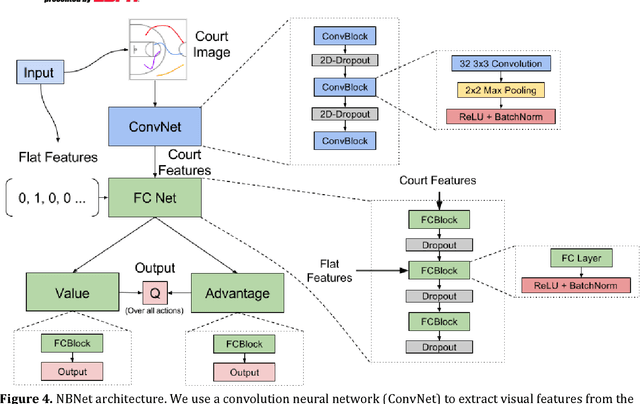
During the 2017 NBA playoffs, Celtics coach Brad Stevens was faced with a difficult decision when defending against the Cavaliers: "Do you double and risk giving up easy shots, or stay at home and do the best you can?" It's a tough call, but finding a good defensive strategy that effectively incorporates doubling can make all the difference in the NBA. In this paper, we analyze double teaming in the NBA, quantifying the trade-off between risk and reward. Using player trajectory data pertaining to over 643,000 possessions, we identified when the ball handler was double teamed. Given these data and the corresponding outcome (i.e., was the defense successful), we used deep reinforcement learning to estimate the quality of the defensive actions. We present qualitative and quantitative results summarizing our learned defensive strategy for defending. We show that our policy value estimates are predictive of points per possession and win percentage. Overall, the proposed framework represents a step toward a more comprehensive understanding of defensive strategies in the NBA.
Contextual Motifs: Increasing the Utility of Motifs using Contextual Data
Jul 31, 2017
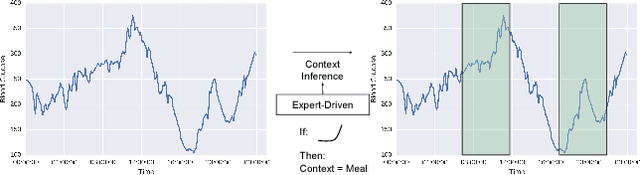
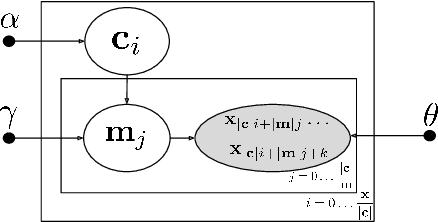
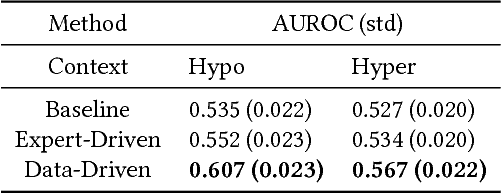
Motifs are a powerful tool for analyzing physiological waveform data. Standard motif methods, however, ignore important contextual information (e.g., what the patient was doing at the time the data were collected). We hypothesize that these additional contextual data could increase the utility of motifs. Thus, we propose an extension to motifs, contextual motifs, that incorporates context. Recognizing that, oftentimes, context may be unobserved or unavailable, we focus on methods to jointly infer motifs and context. Applied to both simulated and real physiological data, our proposed approach improves upon existing motif methods in terms of the discriminative utility of the discovered motifs. In particular, we discovered contextual motifs in continuous glucose monitor (CGM) data collected from patients with type 1 diabetes. Compared to their contextless counterparts, these contextual motifs led to better predictions of hypo- and hyperglycemic events. Our results suggest that even when inferred, context is useful in both a long- and short-term prediction horizon when processing and interpreting physiological waveform data.