 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgeabx_amr_simulator: A simulation environment for antibiotic prescribing policy optimization under antimicrobial resistance
Mar 11, 2026Antimicrobial resistance (AMR) poses a global health threat, reducing the effectiveness of antibiotics and complicating clinical decision-making. To address this challenge, we introduce abx_amr_simulator, a Python-based simulation package designed to model antibiotic prescribing and AMR dynamics within a controlled, reinforcement learning (RL)-compatible environment. The simulator allows users to specify patient populations, antibiotic-specific AMR response curves, and reward functions that balance immedi- ate clinical benefit against long-term resistance management. Key features include a modular design for configuring patient attributes, antibiotic resistance dynamics modeled via a leaky-balloon abstraction, and tools to explore partial observability through noise, bias, and delay in observations. The package is compatible with the Gymnasium RL API, enabling users to train and test RL agents under diverse clinical scenarios. From an ML perspective, the package provides a configurable benchmark environment for sequential decision-making under uncertainty, including partial observability induced by noisy, biased, and delayed observations. By providing a customizable and extensible framework, abx_amr_simulator offers a valuable tool for studying AMR dynamics and optimizing antibiotic stewardship strategies under realistic uncertainty.
GPT-4o System Card
Oct 25, 2024GPT-4o is an autoregressive omni model that accepts as input any combination of text, audio, image, and video, and generates any combination of text, audio, and image outputs. It's trained end-to-end across text, vision, and audio, meaning all inputs and outputs are processed by the same neural network. GPT-4o can respond to audio inputs in as little as 232 milliseconds, with an average of 320 milliseconds, which is similar to human response time in conversation. It matches GPT-4 Turbo performance on text in English and code, with significant improvement on text in non-English languages, while also being much faster and 50\% cheaper in the API. GPT-4o is especially better at vision and audio understanding compared to existing models. In line with our commitment to building AI safely and consistent with our voluntary commitments to the White House, we are sharing the GPT-4o System Card, which includes our Preparedness Framework evaluations. In this System Card, we provide a detailed look at GPT-4o's capabilities, limitations, and safety evaluations across multiple categories, focusing on speech-to-speech while also evaluating text and image capabilities, and measures we've implemented to ensure the model is safe and aligned. We also include third-party assessments on dangerous capabilities, as well as discussion of potential societal impacts of GPT-4o's text and vision capabilities.
Forecasting with Sparse but Informative Variables: A Case Study in Predicting Blood Glucose
Apr 17, 2023In time-series forecasting, future target values may be affected by both intrinsic and extrinsic effects. When forecasting blood glucose, for example, intrinsic effects can be inferred from the history of the target signal alone (\textit{i.e.} blood glucose), but accurately modeling the impact of extrinsic effects requires auxiliary signals, like the amount of carbohydrates ingested. Standard forecasting techniques often assume that extrinsic and intrinsic effects vary at similar rates. However, when auxiliary signals are generated at a much lower frequency than the target variable (e.g., blood glucose measurements are made every 5 minutes, while meals occur once every few hours), even well-known extrinsic effects (e.g., carbohydrates increase blood glucose) may prove difficult to learn. To better utilize these \textit{sparse but informative variables} (SIVs), we introduce a novel encoder/decoder forecasting approach that accurately learns the per-timepoint effect of the SIV, by (i) isolating it from intrinsic effects and (ii) restricting its learned effect based on domain knowledge. On a simulated dataset pertaining to the task of blood glucose forecasting, when the SIV is accurately recorded our approach outperforms baseline approaches in terms of rMSE (13.07 [95% CI: 11.77,14.16] vs. 14.14 [12.69,15.27]). In the presence of a corrupted SIV, the proposed approach can still result in lower error compared to the baseline but the advantage is reduced as noise increases. By isolating their effects and incorporating domain knowledge, our approach makes it possible to better utilize SIVs in forecasting.
* 10 pages, 9 figures, 5 tables, accepted to AAAI23
Deep Reinforcement Learning for Closed-Loop Blood Glucose Control
Sep 18, 2020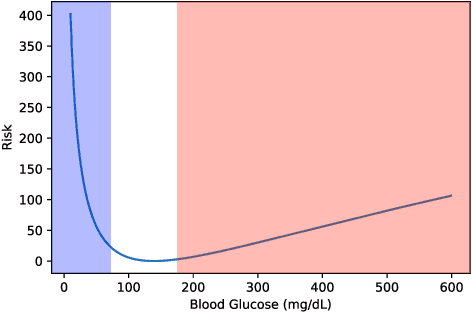
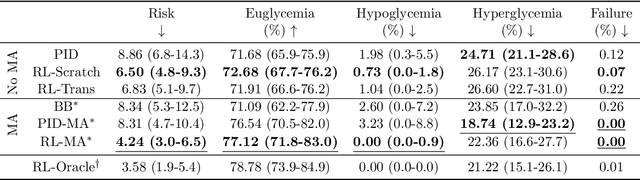
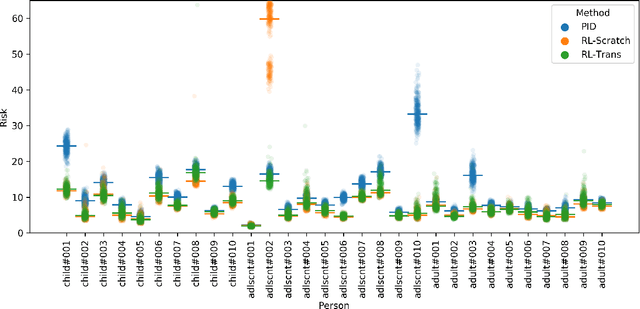

People with type 1 diabetes (T1D) lack the ability to produce the insulin their bodies need. As a result, they must continually make decisions about how much insulin to self-administer to adequately control their blood glucose levels. Longitudinal data streams captured from wearables, like continuous glucose monitors, can help these individuals manage their health, but currently the majority of the decision burden remains on the user. To relieve this burden, researchers are working on closed-loop solutions that combine a continuous glucose monitor and an insulin pump with a control algorithm in an `artificial pancreas.' Such systems aim to estimate and deliver the appropriate amount of insulin. Here, we develop reinforcement learning (RL) techniques for automated blood glucose control. Through a series of experiments, we compare the performance of different deep RL approaches to non-RL approaches. We highlight the flexibility of RL approaches, demonstrating how they can adapt to new individuals with little additional data. On over 2.1 million hours of data from 30 simulated patients, our RL approach outperforms baseline control algorithms: leading to a decrease in median glycemic risk of nearly 50% from 8.34 to 4.24 and a decrease in total time hypoglycemic of 99.8%, from 4,610 days to 6. Moreover, these approaches are able to adapt to predictable meal times (decreasing average risk by an additional 24% as meals increase in predictability). This work demonstrates the potential of deep RL to help people with T1D manage their blood glucose levels without requiring expert knowledge. All of our code is publicly available, allowing for replication and extension.