 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExpertGen: Scalable Sim-to-Real Expert Policy Learning from Imperfect Behavior Priors
Mar 16, 2026Learning generalizable and robust behavior cloning policies requires large volumes of high-quality robotics data. While human demonstrations (e.g., through teleoperation) serve as the standard source for expert behaviors, acquiring such data at scale in the real world is prohibitively expensive. This paper introduces ExpertGen, a framework that automates expert policy learning in simulation to enable scalable sim-to-real transfer. ExpertGen first initializes a behavior prior using a diffusion policy trained on imperfect demonstrations, which may be synthesized by large language models or provided by humans. Reinforcement learning is then used to steer this prior toward high task success by optimizing the diffusion model's initial noise while keep original policy frozen. By keeping the pretrained diffusion policy frozen, ExpertGen regularizes exploration to remain within safe, human-like behavior manifolds, while also enabling effective learning with only sparse rewards. Empirical evaluations on challenging manipulation benchmarks demonstrate that ExpertGen reliably produces high-quality expert policies with no reward engineering. On industrial assembly tasks, ExpertGen achieves a 90.5% overall success rate, while on long-horizon manipulation tasks it attains 85% overall success, outperforming all baseline methods. The resulting policies exhibit dexterous control and remain robust across diverse initial configurations and failure states. To validate sim-to-real transfer, the learned state-based expert policies are further distilled into visuomotor policies via DAgger and successfully deployed on real robotic hardware.
BEAGLE: Behavior-Enforced Agent for Grounded Learner Emulation
Feb 06, 2026Simulating student learning behaviors in open-ended problem-solving environments holds potential for education research, from training adaptive tutoring systems to stress-testing pedagogical interventions. However, collecting authentic data is challenging due to privacy concerns and the high cost of longitudinal studies. While Large Language Models (LLMs) offer a promising path to student simulation, they suffer from competency bias, optimizing for efficient correctness rather than the erratic, iterative struggle characteristic of novice learners. We present BEAGLE, a neuro-symbolic framework that addresses this bias by incorporating Self-Regulated Learning (SRL) theory into a novel architecture. BEAGLE integrates three key technical innovations: (1) a semi-Markov model that governs the timing and transitions of cognitive behaviors and metacognitive behaviors; (2) Bayesian Knowledge Tracing with explicit flaw injection to enforce realistic knowledge gaps and "unknown unknowns"; and (3) a decoupled agent design that separates high-level strategy use from code generation actions to prevent the model from silently correcting its own intentional errors. In evaluations on Python programming tasks, BEAGLE significantly outperforms state-of-the-art baselines in reproducing authentic trajectories. In a human Turing test, users were unable to distinguish synthetic traces from real student data, achieving an accuracy indistinguishable from random guessing (52.8%).
Entropy-Guided k-Guard Sampling for Long-Horizon Autoregressive Video Generation
Jan 27, 2026Autoregressive (AR) architectures have achieved significant successes in LLMs, inspiring explorations for video generation. In LLMs, top-p/top-k sampling strategies work exceptionally well: language tokens have high semantic density and low redundancy, so a fixed size of token candidates already strikes a balance between semantic accuracy and generation diversity. In contrast, video tokens have low semantic density and high spatio-temporal redundancy. This mismatch makes static top-k/top-p strategies ineffective for video decoders: they either introduce unnecessary randomness for low-uncertainty regions (static backgrounds) or get stuck in early errors for high-uncertainty regions (foreground objects). Prediction errors will accumulate as more frames are generated and eventually severely degrade long-horizon quality. To address this, we propose Entropy-Guided k-Guard (ENkG) sampling, a simple yet effective strategy that adapts sampling to token-wise dispersion, quantified by the entropy of each token's predicted distribution. ENkG uses adaptive token candidate sizes: for low-entropy regions, it employs fewer candidates to suppress redundant noise and preserve structural integrity; for high-entropy regions, it uses more candidates to mitigate error compounding. ENkG is model-agnostic, training-free, and adds negligible overhead. Experiments demonstrate consistent improvements in perceptual quality and structural stability compared to static top-k/top-p strategies.
The Essentials of AI for Life and Society: An AI Literacy Course for the University Community
Jan 13, 2025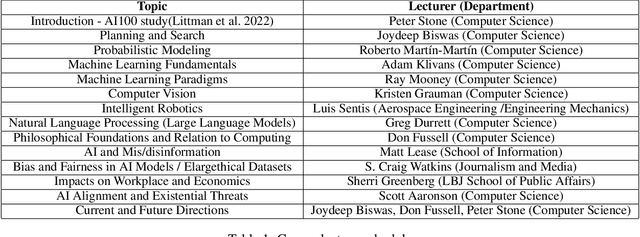

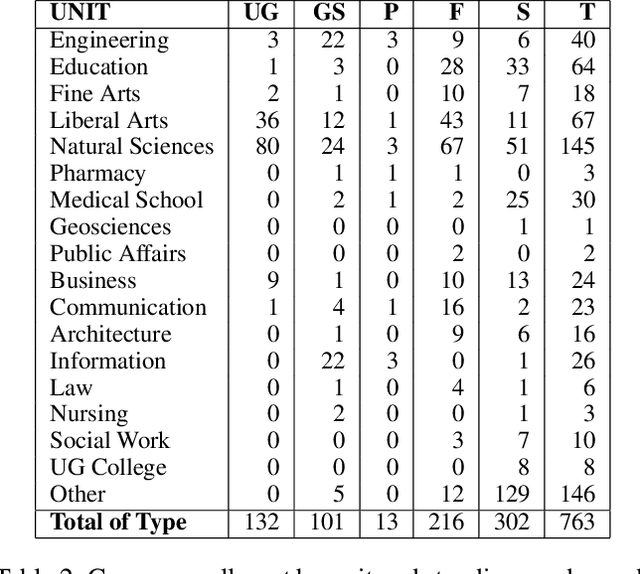
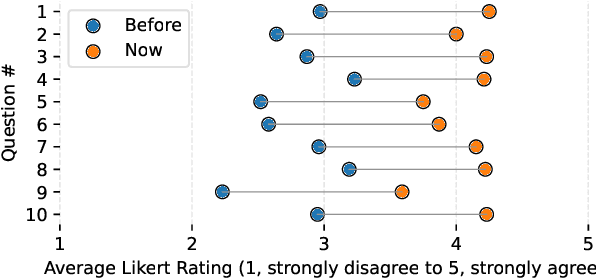
We describe the development of a one-credit course to promote AI literacy at The University of Texas at Austin. In response to a call for the rapid deployment of class to serve a broad audience in Fall of 2023, we designed a 14-week seminar-style course that incorporated an interdisciplinary group of speakers who lectured on topics ranging from the fundamentals of AI to societal concerns including disinformation and employment. University students, faculty, and staff, and even community members outside of the University, were invited to enroll in this online offering: The Essentials of AI for Life and Society. We collected feedback from course participants through weekly reflections and a final survey. Satisfyingly, we found that attendees reported gains in their AI literacy. We sought critical feedback through quantitative and qualitative analysis, which uncovered challenges in designing a course for this general audience. We utilized the course feedback to design a three-credit version of the course that is being offered in Fall of 2024. The lessons we learned and our plans for this new iteration may serve as a guide to instructors designing AI courses for a broad audience.
Grounded Curriculum Learning
Sep 29, 2024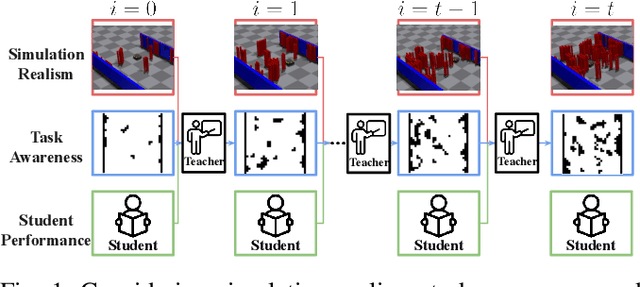
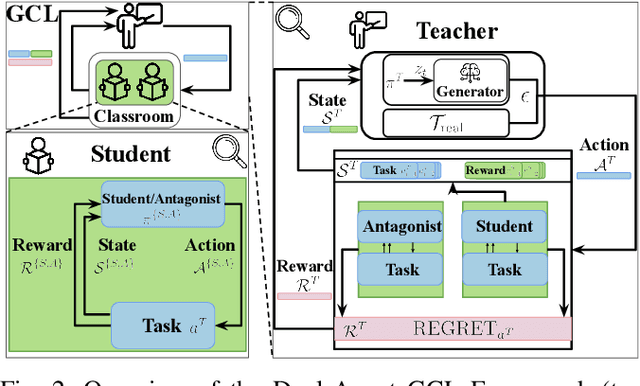
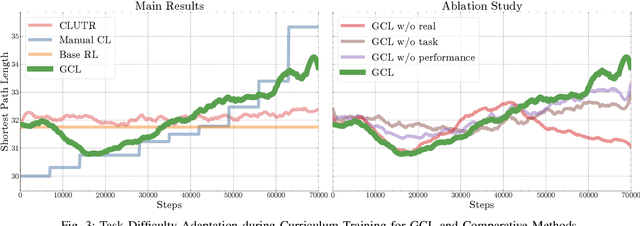
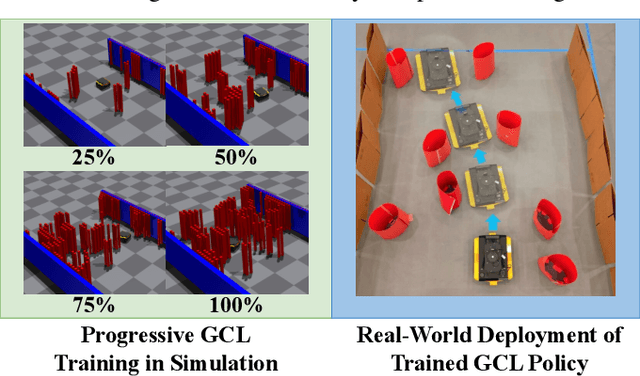
The high cost of real-world data for robotics Reinforcement Learning (RL) leads to the wide usage of simulators. Despite extensive work on building better dynamics models for simulators to match with the real world, there is another, often-overlooked mismatch between simulations and the real world, namely the distribution of available training tasks. Such a mismatch is further exacerbated by existing curriculum learning techniques, which automatically vary the simulation task distribution without considering its relevance to the real world. Considering these challenges, we posit that curriculum learning for robotics RL needs to be grounded in real-world task distributions. To this end, we propose Grounded Curriculum Learning (GCL), which aligns the simulated task distribution in the curriculum with the real world, as well as explicitly considers what tasks have been given to the robot and how the robot has performed in the past. We validate GCL using the BARN dataset on complex navigation tasks, achieving a 6.8% and 6.5% higher success rate compared to a state-of-the-art CL method and a curriculum designed by human experts, respectively. These results show that GCL can enhance learning efficiency and navigation performance by grounding the simulation task distribution in the real world within an adaptive curriculum.
Dexterous Legged Locomotion in Confined 3D Spaces with Reinforcement Learning
Mar 06, 2024
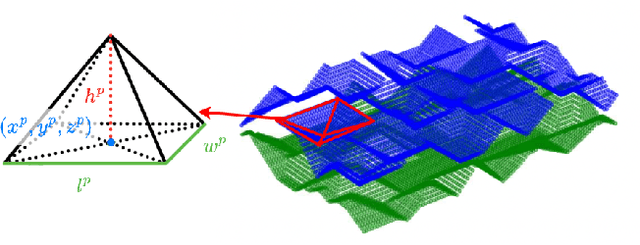
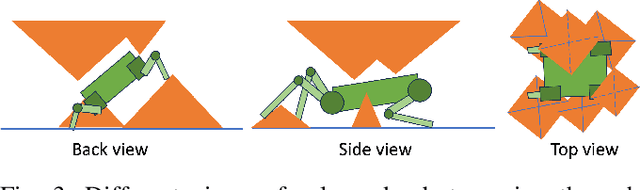

Recent advances of locomotion controllers utilizing deep reinforcement learning (RL) have yielded impressive results in terms of achieving rapid and robust locomotion across challenging terrain, such as rugged rocks, non-rigid ground, and slippery surfaces. However, while these controllers primarily address challenges underneath the robot, relatively little research has investigated legged mobility through confined 3D spaces, such as narrow tunnels or irregular voids, which impose all-around constraints. The cyclic gait patterns resulted from existing RL-based methods to learn parameterized locomotion skills characterized by motion parameters, such as velocity and body height, may not be adequate to navigate robots through challenging confined 3D spaces, requiring both agile 3D obstacle avoidance and robust legged locomotion. Instead, we propose to learn locomotion skills end-to-end from goal-oriented navigation in confined 3D spaces. To address the inefficiency of tracking distant navigation goals, we introduce a hierarchical locomotion controller that combines a classical planner tasked with planning waypoints to reach a faraway global goal location, and an RL-based policy trained to follow these waypoints by generating low-level motion commands. This approach allows the policy to explore its own locomotion skills within the entire solution space and facilitates smooth transitions between local goals, enabling long-term navigation towards distant goals. In simulation, our hierarchical approach succeeds at navigating through demanding confined 3D environments, outperforming both pure end-to-end learning approaches and parameterized locomotion skills. We further demonstrate the successful real-world deployment of our simulation-trained controller on a real robot.
Sample Efficient Myopic Exploration Through Multitask Reinforcement Learning with Diverse Tasks
Mar 06, 2024



Multitask Reinforcement Learning (MTRL) approaches have gained increasing attention for its wide applications in many important Reinforcement Learning (RL) tasks. However, while recent advancements in MTRL theory have focused on the improved statistical efficiency by assuming a shared structure across tasks, exploration--a crucial aspect of RL--has been largely overlooked. This paper addresses this gap by showing that when an agent is trained on a sufficiently diverse set of tasks, a generic policy-sharing algorithm with myopic exploration design like $\epsilon$-greedy that are inefficient in general can be sample-efficient for MTRL. To the best of our knowledge, this is the first theoretical demonstration of the "exploration benefits" of MTRL. It may also shed light on the enigmatic success of the wide applications of myopic exploration in practice. To validate the role of diversity, we conduct experiments on synthetic robotic control environments, where the diverse task set aligns with the task selection by automatic curriculum learning, which is empirically shown to improve sample-efficiency.
Latent Skill Discovery for Chain-of-Thought Reasoning
Dec 07, 2023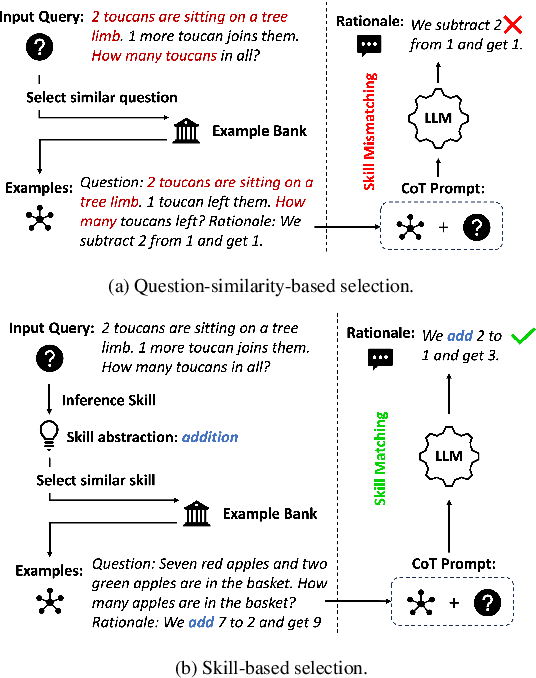
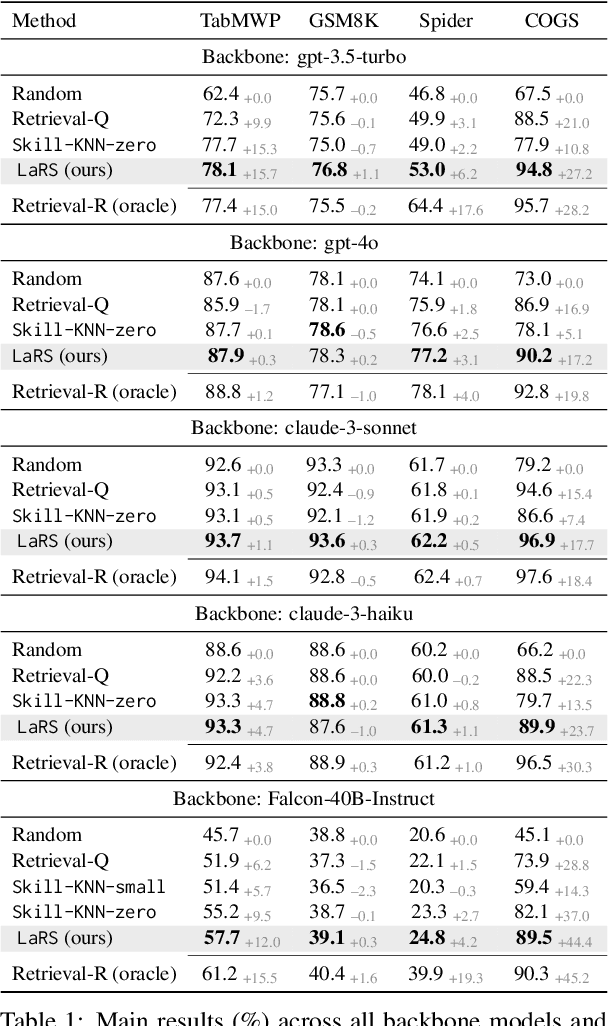
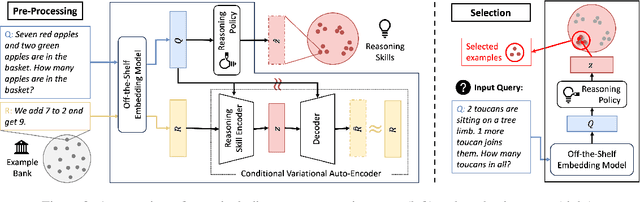
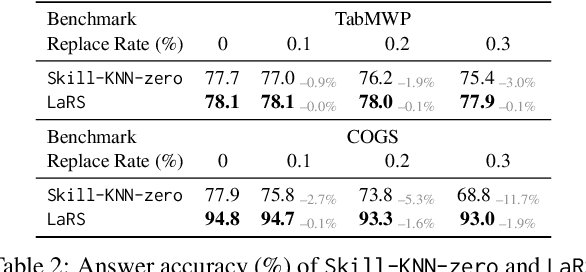
Recent advances in Large Language Models (LLMs) have led to an emergent ability of chain-of-thought (CoT) prompting, a prompt reasoning strategy that adds intermediate rationale steps between questions and answers to construct prompts. Conditioned on these prompts, LLMs can effectively learn in context to generate rationales that lead to more accurate answers than when answering the same question directly. To design LLM prompts, one important setting, called demonstration selection, considers selecting demonstrations from an example bank. Existing methods use various heuristics for this selection, but for CoT prompting, which involves unique rationales, it is essential to base the selection upon the intrinsic skills that CoT rationales need, for instance, the skills of addition or subtraction for math word problems. To address this requirement, we introduce a novel approach named Reasoning Skill Discovery (RSD) that use unsupervised learning to create a latent space representation of rationales, called a reasoning skill. Simultaneously, RSD learns a reasoning policy to determine the required reasoning skill for a given question. This can then guide the selection of examples that demonstrate the required reasoning skills. Our approach offers several desirable properties: it is (1) theoretically grounded, (2) sample-efficient, requiring no LLM inference or manual prompt design, and (3) LLM-agnostic. Empirically, RSD outperforms existing methods by up to 6% in terms of the answer accuracy across multiple reasoning tasks.
Autonomous Ground Navigation in Highly Constrained Spaces: Lessons learned from The 2nd BARN Challenge at ICRA 2023
Aug 06, 2023The 2nd BARN (Benchmark Autonomous Robot Navigation) Challenge took place at the 2023 IEEE International Conference on Robotics and Automation (ICRA 2023) in London, UK and continued to evaluate the performance of state-of-the-art autonomous ground navigation systems in highly constrained environments. Compared to The 1st BARN Challenge at ICRA 2022 in Philadelphia, the competition has grown significantly in size, doubling the numbers of participants in both the simulation qualifier and physical finals: Ten teams from all over the world participated in the qualifying simulation competition, six of which were invited to compete with each other in three physical obstacle courses at the conference center in London, and three teams won the challenge by navigating a Clearpath Jackal robot from a predefined start to a goal with the shortest amount of time without colliding with any obstacle. The competition results, compared to last year, suggest that the teams are making progress toward more robust and efficient ground navigation systems that work out-of-the-box in many obstacle environments. However, a significant amount of fine-tuning is still needed onsite to cater to different difficult navigation scenarios. Furthermore, challenges still remain for many teams when facing extremely cluttered obstacles and increasing navigation speed. In this article, we discuss the challenge, the approaches used by the three winning teams, and lessons learned to direct future research.
A Domain-Agnostic Approach for Characterization of Lifelong Learning Systems
Jan 18, 2023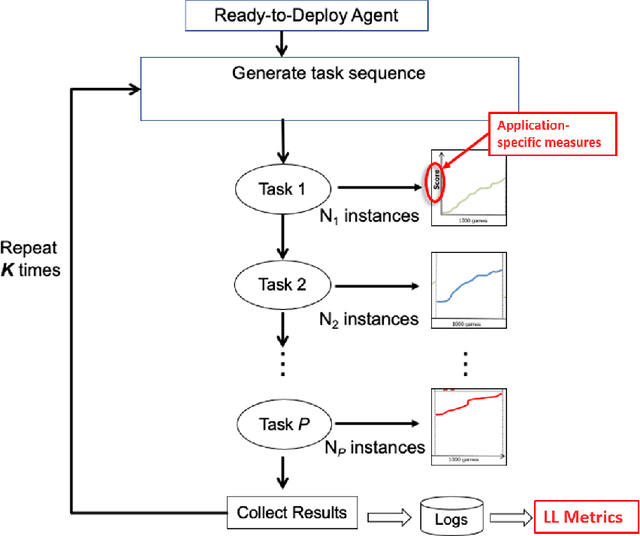
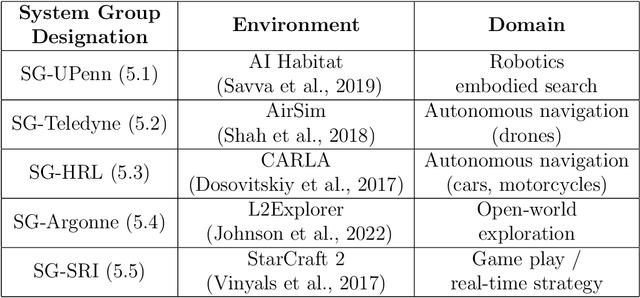


Despite the advancement of machine learning techniques in recent years, state-of-the-art systems lack robustness to "real world" events, where the input distributions and tasks encountered by the deployed systems will not be limited to the original training context, and systems will instead need to adapt to novel distributions and tasks while deployed. This critical gap may be addressed through the development of "Lifelong Learning" systems that are capable of 1) Continuous Learning, 2) Transfer and Adaptation, and 3) Scalability. Unfortunately, efforts to improve these capabilities are typically treated as distinct areas of research that are assessed independently, without regard to the impact of each separate capability on other aspects of the system. We instead propose a holistic approach, using a suite of metrics and an evaluation framework to assess Lifelong Learning in a principled way that is agnostic to specific domains or system techniques. Through five case studies, we show that this suite of metrics can inform the development of varied and complex Lifelong Learning systems. We highlight how the proposed suite of metrics quantifies performance trade-offs present during Lifelong Learning system development - both the widely discussed Stability-Plasticity dilemma and the newly proposed relationship between Sample Efficient and Robust Learning. Further, we make recommendations for the formulation and use of metrics to guide the continuing development of Lifelong Learning systems and assess their progress in the future.