 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeasibility-Guided Planning over Multi-Specialized Locomotion Policies
Feb 08, 2026Planning over unstructured terrain presents a significant challenge in the field of legged robotics. Although recent works in reinforcement learning have yielded various locomotion strategies, planning over multiple experts remains a complex issue. Existing approaches encounter several constraints: traditional planners are unable to integrate skill-specific policies, whereas hierarchical learning frameworks often lose interpretability and require retraining whenever new policies are added. In this paper, we propose a feasibility-guided planning framework that successfully incorporates multiple terrain-specific policies. Each policy is paired with a Feasibility-Net, which learned to predict feasibility tensors based on the local elevation maps and task vectors. This integration allows classical planning algorithms to derive optimal paths. Through both simulated and real-world experiments, we demonstrate that our method efficiently generates reliable plans across diverse and challenging terrains, while consistently aligning with the capabilities of the underlying policies.
Benchmarking Smoothness and Reducing High-Frequency Oscillations in Continuous Control Policies
Oct 22, 2024
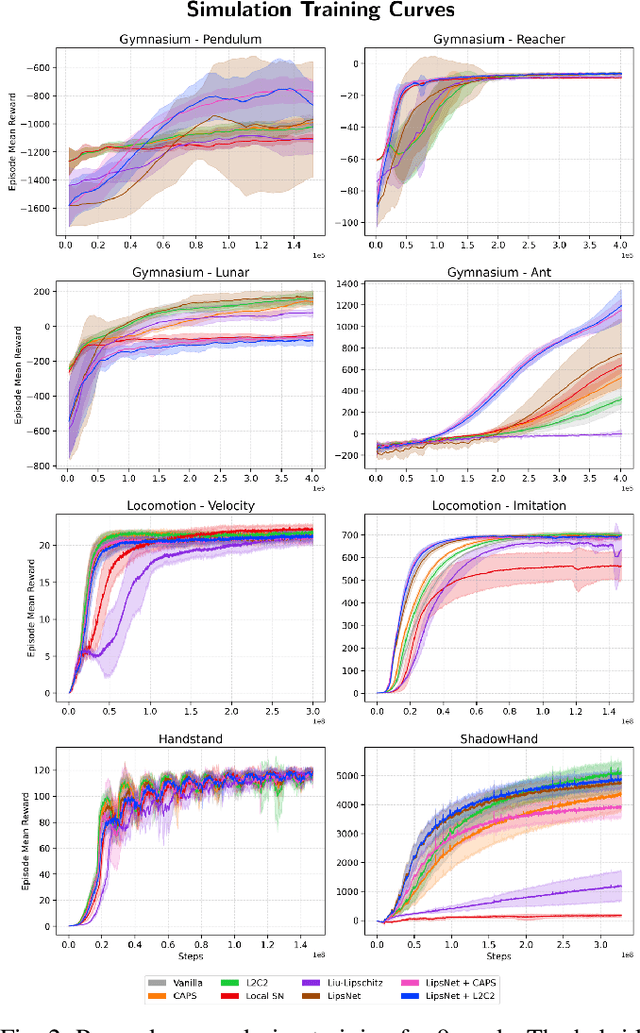
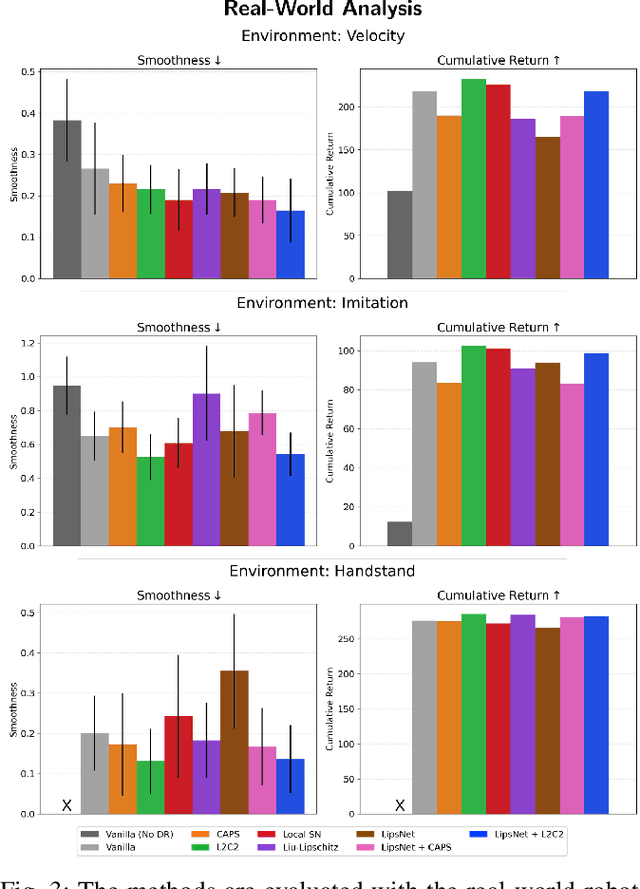
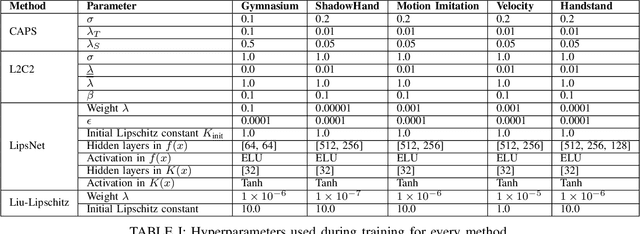
Reinforcement learning (RL) policies are prone to high-frequency oscillations, especially undesirable when deploying to hardware in the real-world. In this paper, we identify, categorize, and compare methods from the literature that aim to mitigate high-frequency oscillations in deep RL. We define two broad classes: loss regularization and architectural methods. At their core, these methods incentivize learning a smooth mapping, such that nearby states in the input space produce nearby actions in the output space. We present benchmarks in terms of policy performance and control smoothness on traditional RL environments from the Gymnasium and a complex manipulation task, as well as three robotics locomotion tasks that include deployment and evaluation with real-world hardware. Finally, we also propose hybrid methods that combine elements from both loss regularization and architectural methods. We find that the best-performing hybrid outperforms other methods, and improves control smoothness by 26.8% over the baseline, with a worst-case performance degradation of just 2.8%.
Expert Composer Policy: Scalable Skill Repertoire for Quadruped Robots
Mar 18, 2024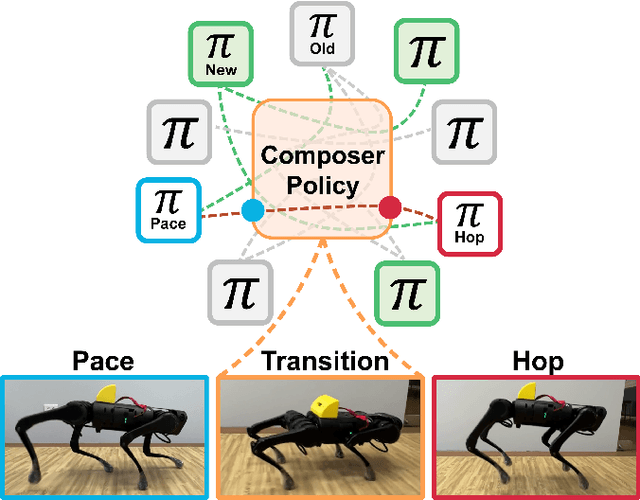
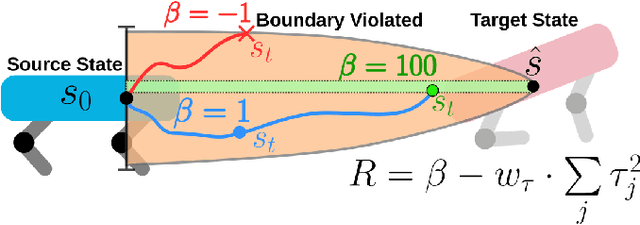

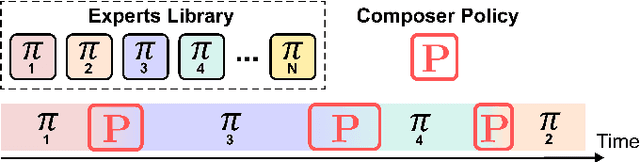
We propose the expert composer policy, a framework to reliably expand the skill repertoire of quadruped agents. The composer policy links pair of experts via transitions to a sampled target state, allowing experts to be composed sequentially. Each expert specializes in a single skill, such as a locomotion gait or a jumping motion. Instead of a hierarchical or mixture-of-experts architecture, we train a single composer policy in an independent process that is not conditioned on the other expert policies. By reusing the same composer policy, our approach enables adding new experts without affecting existing ones, enabling incremental repertoire expansion and preserving original motion quality. We measured the transition success rate of 72 transition pairs and achieved an average success rate of 99.99\%, which is over 10\% higher than the baseline random approach, and outperforms other state-of-the-art methods. Using domain randomization during training we ensure a successful transfer to the real world, where we achieve an average transition success rate of 97.22\% (N=360) in our experiments.
Autonomous Ground Navigation in Highly Constrained Spaces: Lessons learned from The 2nd BARN Challenge at ICRA 2023
Aug 06, 2023The 2nd BARN (Benchmark Autonomous Robot Navigation) Challenge took place at the 2023 IEEE International Conference on Robotics and Automation (ICRA 2023) in London, UK and continued to evaluate the performance of state-of-the-art autonomous ground navigation systems in highly constrained environments. Compared to The 1st BARN Challenge at ICRA 2022 in Philadelphia, the competition has grown significantly in size, doubling the numbers of participants in both the simulation qualifier and physical finals: Ten teams from all over the world participated in the qualifying simulation competition, six of which were invited to compete with each other in three physical obstacle courses at the conference center in London, and three teams won the challenge by navigating a Clearpath Jackal robot from a predefined start to a goal with the shortest amount of time without colliding with any obstacle. The competition results, compared to last year, suggest that the teams are making progress toward more robust and efficient ground navigation systems that work out-of-the-box in many obstacle environments. However, a significant amount of fine-tuning is still needed onsite to cater to different difficult navigation scenarios. Furthermore, challenges still remain for many teams when facing extremely cluttered obstacles and increasing navigation speed. In this article, we discuss the challenge, the approaches used by the three winning teams, and lessons learned to direct future research.
The BARN Challenge 2023 -- Autonomous Navigation in Highly Constrained Spaces -- Inventec Team
Jul 27, 2023


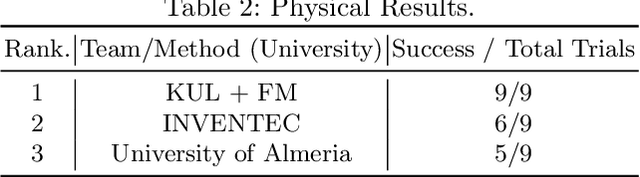
Navigation in the real-world is hard and filled with complex scenarios. The Benchmark Autonomous Robot Navigation (BARN) Challenge is a competition that focuses on highly constrained spaces. Teams compete using a standard platform in a simulation and a real-world stage, with scenarios ranging from easy to challenging. This technical report presents the system and methods employed by the Inventec Team during the BARN Challenge 2023 (https://cs.gmu.edu/~xiao/Research/BARN_Challenge/BARN_Challenge23.html). At its core, our method uses the baseline learning-based controller LfLH. We developed extensions using a finite state machine to trigger recovery behaviors, and introduced two alternatives for forward safety collision checks, based on footprint inflation and model-predictive control. Moreover, we also present a backtrack safety check based on costmap region-of-interest. Compared to the original baseline, we managed a significant increase in the navigation score, from 0.2334 to 0.2445 (4.76%). Overall, our team ranked second place both in simulation and in the real-world stage. Our code is publicly available at: (https://github.com/inventec-ai-center/inventec-team-barn-challenge-2023.git)
Expanding Versatility of Agile Locomotion through Policy Transitions Using Latent State Representation
Jun 14, 2023
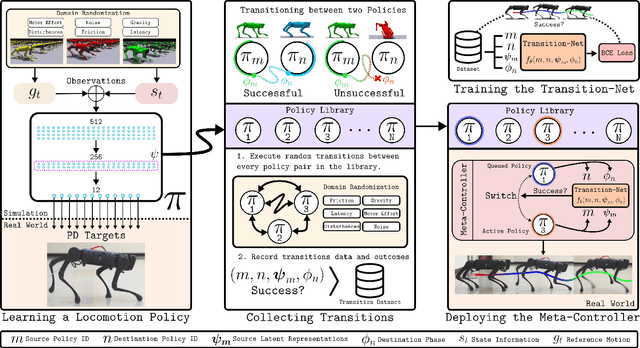
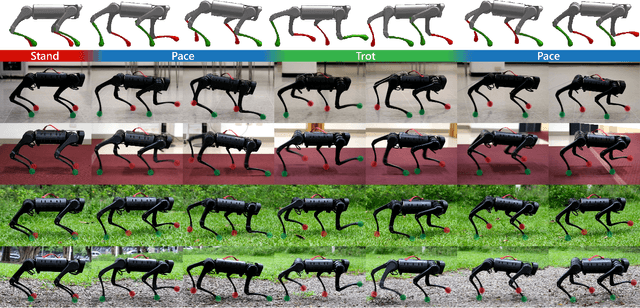
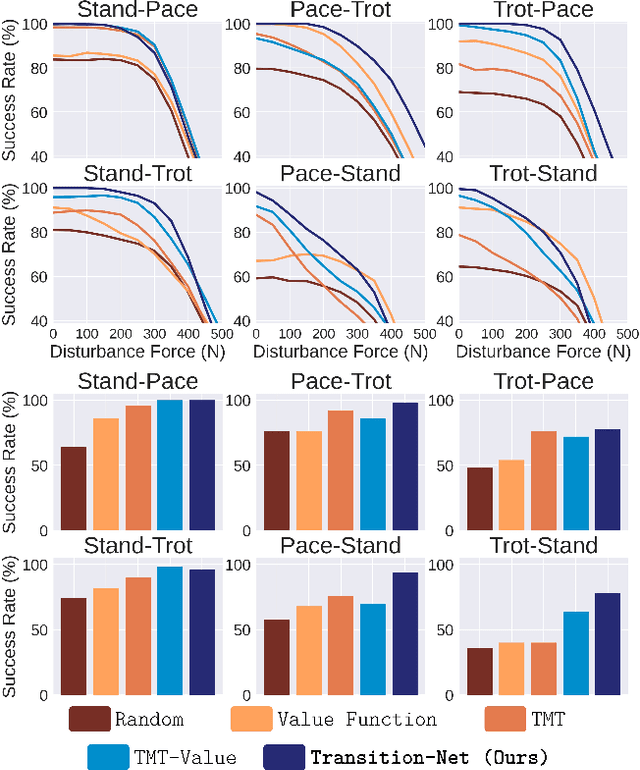
This paper proposes the transition-net, a robust transition strategy that expands the versatility of robot locomotion in the real-world setting. To this end, we start by distributing the complexity of different gaits into dedicated locomotion policies applicable to real-world robots. Next, we expand the versatility of the robot by unifying the policies with robust transitions into a single coherent meta-controller by examining the latent state representations. Our approach enables the robot to iteratively expand its skill repertoire and robustly transition between any policy pair in a library. In our framework, adding new skills does not introduce any process that alters the previously learned skills. Moreover, training of a locomotion policy takes less than an hour with a single consumer GPU. Our approach is effective in the real-world and achieves a 19% higher average success rate for the most challenging transition pairs in our experiments compared to existing approaches.
Can a Robot Shoot an Olympic Recurve Bow? A preliminary study
Dec 21, 2022The field of robotics, and more especially humanoid robotics, has several established competitions with research oriented goals in mind. Challenging the robots in a handful of tasks, these competitions provide a way to gauge the state of the art in robotic design, as well as an indicator for how far we are from reaching human performance. The most notable competitions are RoboCup, which has the long-term goal of competing against a real human team in 2050, and the FIRA HuroCup league, in which humanoid robots have to perform tasks based on actual Olympic events. Having robots compete against humans under the same rules is a challenging goal, and, we believe that it is in the sport of archery that humanoid robots have the most potential to achieve it in the near future. In this work, we perform a first step in this direction. We present a humanoid robot that is capable of gripping, drawing and shooting a recurve bow at a target 10 meters away with considerable accuracy. Additionally, we show that it is also capable of shooting distances of over 50 meters.
Multi-modal estimation of the properties of containers and their content: survey and evaluation
Jul 27, 2021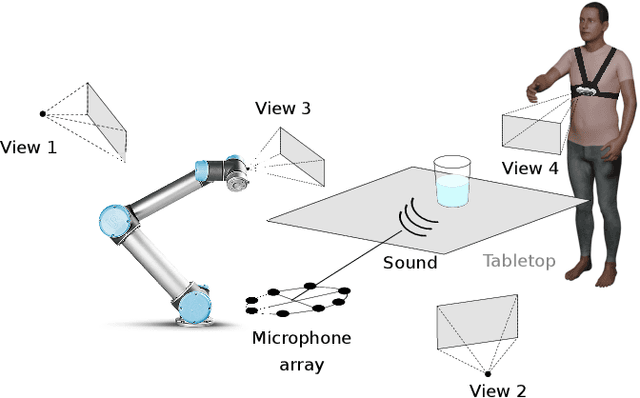


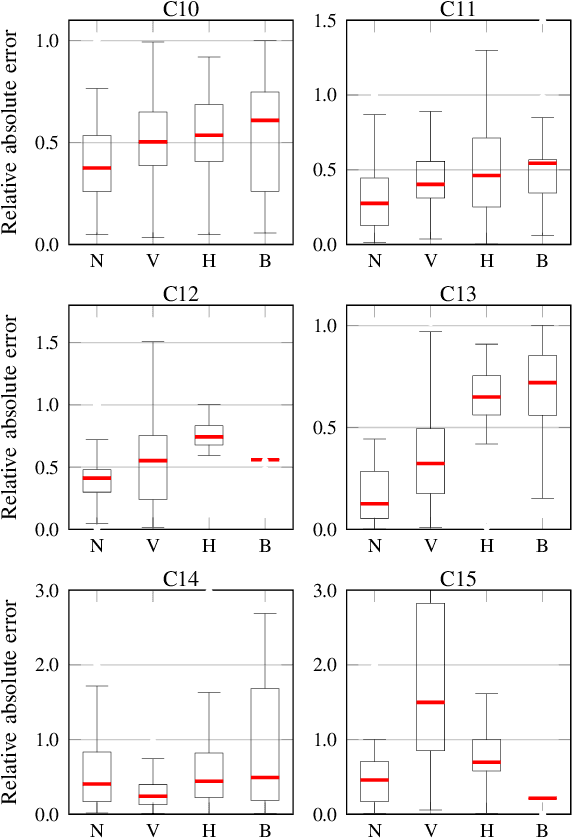
Acoustic and visual sensing can support the contactless estimation of the weight of a container and the amount of its content when the container is manipulated by a person. However, transparencies (both of the container and of the content) and the variability of materials, shapes and sizes make this problem challenging. In this paper, we present an open benchmarking framework and an in-depth comparative analysis of recent methods that estimate the capacity of a container, as well as the type, mass, and amount of its content. These methods use learned and handcrafted features, such as mel-frequency cepstrum coefficients, zero-crossing rate, spectrograms, with different types of classifiers to estimate the type and amount of the content with acoustic data, and geometric approaches with visual data to determine the capacity of the container. Results on a newly distributed dataset show that audio alone is a strong modality and methods achieves a weighted average F1-score up to 81% and 97% for content type and level classification, respectively. Estimating the container capacity with vision-only approaches and filling mass with multi-modal, multi-stage algorithms reaches up to 65% weighted average capacity and mass scores.