 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan a Robot Shoot an Olympic Recurve Bow? A preliminary study
Dec 21, 2022The field of robotics, and more especially humanoid robotics, has several established competitions with research oriented goals in mind. Challenging the robots in a handful of tasks, these competitions provide a way to gauge the state of the art in robotic design, as well as an indicator for how far we are from reaching human performance. The most notable competitions are RoboCup, which has the long-term goal of competing against a real human team in 2050, and the FIRA HuroCup league, in which humanoid robots have to perform tasks based on actual Olympic events. Having robots compete against humans under the same rules is a challenging goal, and, we believe that it is in the sport of archery that humanoid robots have the most potential to achieve it in the near future. In this work, we perform a first step in this direction. We present a humanoid robot that is capable of gripping, drawing and shooting a recurve bow at a target 10 meters away with considerable accuracy. Additionally, we show that it is also capable of shooting distances of over 50 meters.
Depth-CUPRL: Depth-Imaged Contrastive Unsupervised Prioritized Representations in Reinforcement Learning for Mapless Navigation of Unmanned Aerial Vehicles
Jul 01, 2022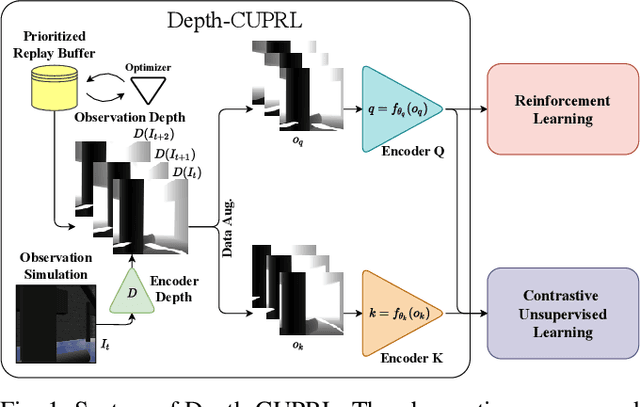
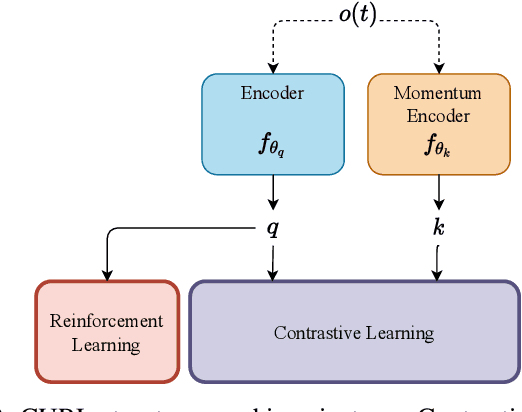
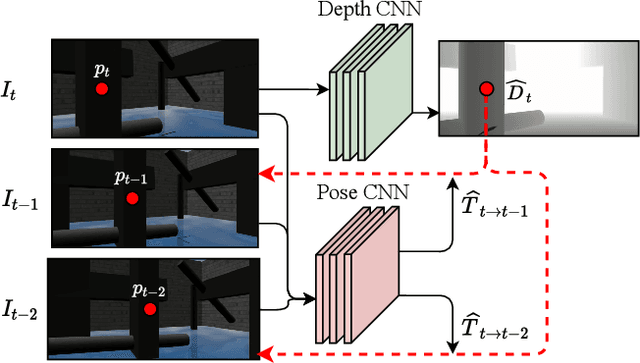
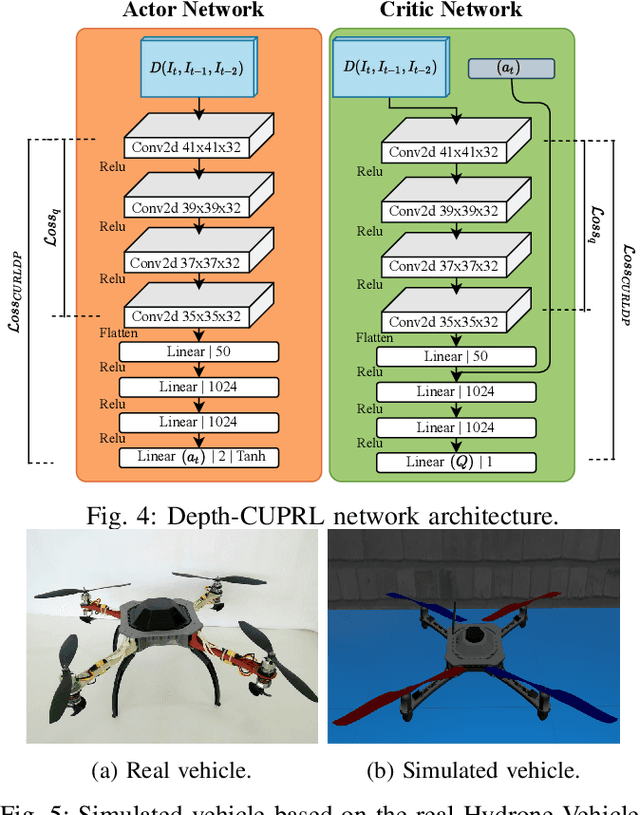
Reinforcement Learning (RL) has presented an impressive performance in video games through raw pixel imaging and continuous control tasks. However, RL performs poorly with high-dimensional observations such as raw pixel images. It is generally accepted that physical state-based RL policies such as laser sensor measurements give a more sample-efficient result than learning by pixels. This work presents a new approach that extracts information from a depth map estimation to teach an RL agent to perform the mapless navigation of Unmanned Aerial Vehicle (UAV). We propose the Depth-Imaged Contrastive Unsupervised Prioritized Representations in Reinforcement Learning(Depth-CUPRL) that estimates the depth of images with a prioritized replay memory. We used a combination of RL and Contrastive Learning to lead with the problem of RL based on images. From the analysis of the results with Unmanned Aerial Vehicles (UAVs), it is possible to conclude that our Depth-CUPRL approach is effective for the decision-making and outperforms state-of-the-art pixel-based approaches in the mapless navigation capability.
Deep Reinforcement Learning Using a Low-Dimensional Observation Filter for Visual Complex Video Game Playing
Apr 24, 2022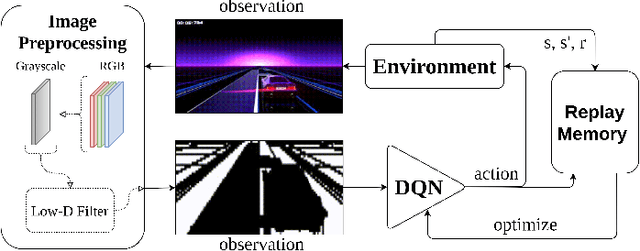
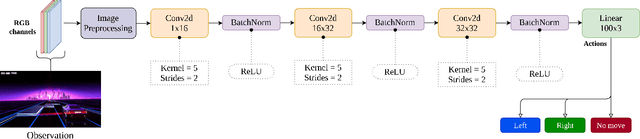
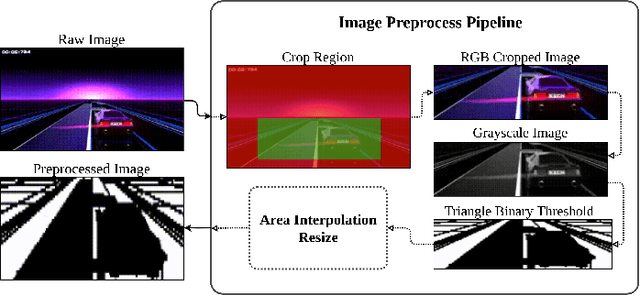
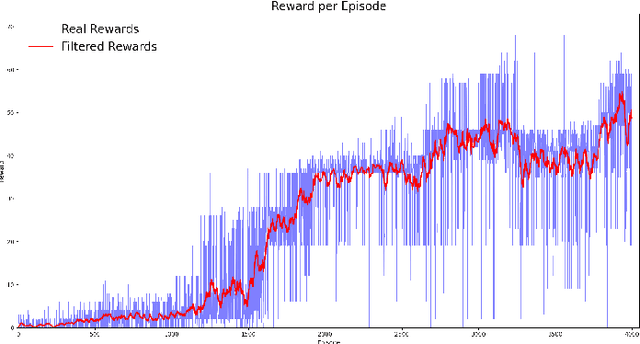
Deep Reinforcement Learning (DRL) has produced great achievements since it was proposed, including the possibility of processing raw vision input data. However, training an agent to perform tasks based on image feedback remains a challenge. It requires the processing of large amounts of data from high-dimensional observation spaces, frame by frame, and the agent's actions are computed according to deep neural network policies, end-to-end. Image pre-processing is an effective way of reducing these high dimensional spaces, eliminating unnecessary information present in the scene, supporting the extraction of features and their representations in the agent's neural network. Modern video-games are examples of this type of challenge for DRL algorithms because of their visual complexity. In this paper, we propose a low-dimensional observation filter that allows a deep Q-network agent to successfully play in a visually complex and modern video-game, called Neon Drive.