 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParallel Distributional Deep Reinforcement Learning for Mapless Navigation of Terrestrial Mobile Robots
Aug 11, 2024
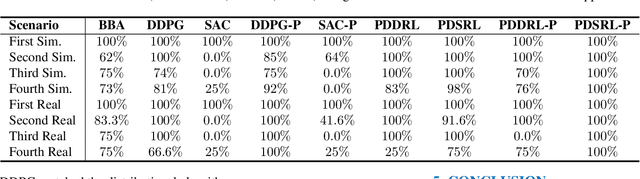

This paper introduces novel deep reinforcement learning (Deep-RL) techniques using parallel distributional actor-critic networks for navigating terrestrial mobile robots. Our approaches use laser range findings, relative distance, and angle to the target to guide the robot. We trained agents in the Gazebo simulator and deployed them in real scenarios. Results show that parallel distributional Deep-RL algorithms enhance decision-making and outperform non-distributional and behavior-based approaches in navigation and spatial generalization.
Parallel Distributional Prioritized Deep Reinforcement Learning for Unmanned Aerial Vehicles
Sep 01, 2023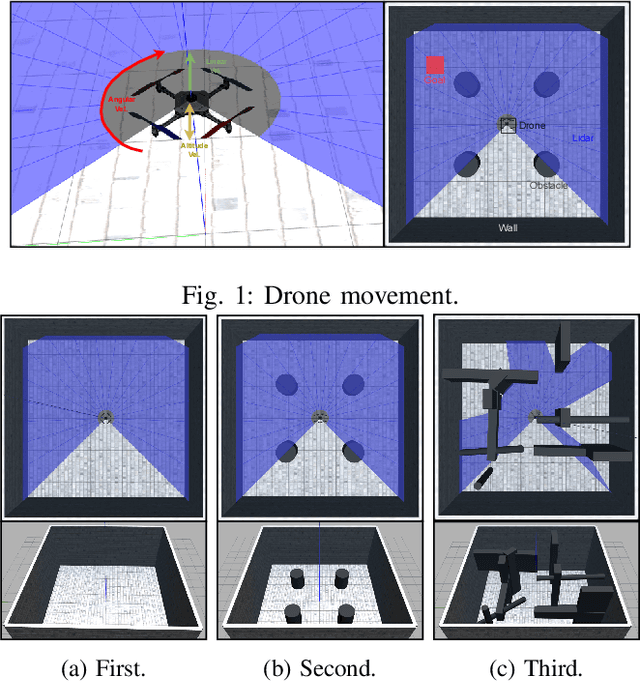
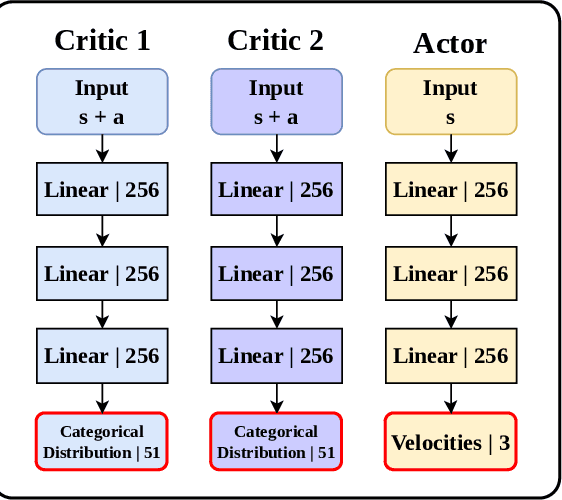
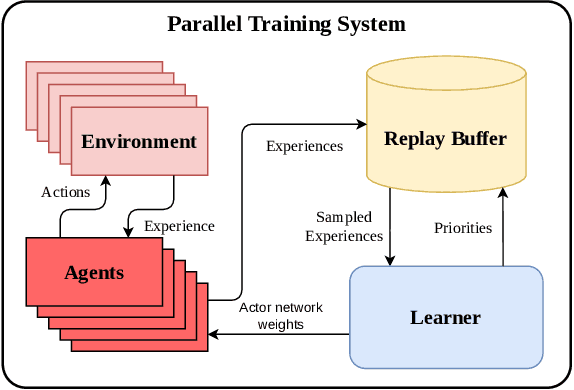
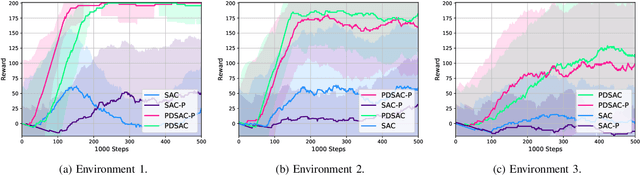
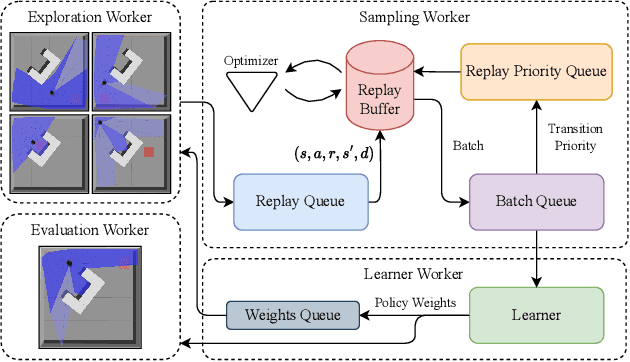
This work presents a study on parallel and distributional deep reinforcement learning applied to the mapless navigation of UAVs. For this, we developed an approach based on the Soft Actor-Critic method, producing a distributed and distributional variant named PDSAC, and compared it with a second one based on the traditional SAC algorithm. In addition, we also embodied a prioritized memory system into them. The UAV used in the study is based on the Hydrone vehicle, a hybrid quadrotor operating solely in the air. The inputs for the system are 23 range findings from a Lidar sensor and the distance and angles towards a desired goal, while the outputs consist of the linear, angular, and, altitude velocities. The methods were trained in environments of varying complexity, from obstacle-free environments to environments with multiple obstacles in three dimensions. The results obtained, demonstrate a concise improvement in the navigation capabilities by the proposed approach when compared to the agent based on the SAC for the same amount of training steps. In summary, this work presented a study on deep reinforcement learning applied to mapless navigation of drones in three dimensions, with promising results and potential applications in various contexts related to robotics and autonomous air navigation with distributed and distributional variants.
Depth-CUPRL: Depth-Imaged Contrastive Unsupervised Prioritized Representations in Reinforcement Learning for Mapless Navigation of Unmanned Aerial Vehicles
Jul 01, 2022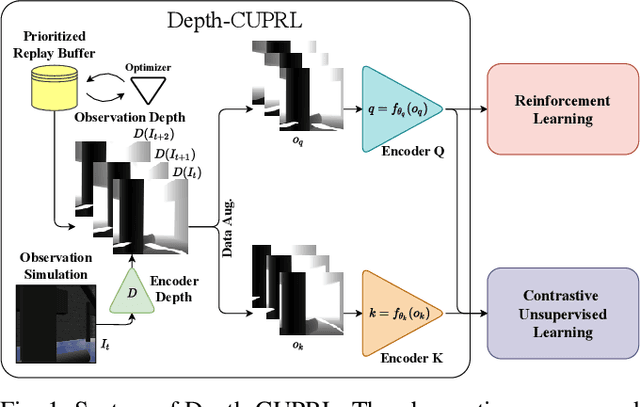
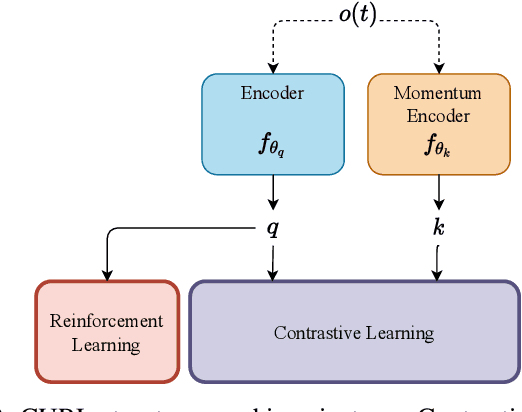
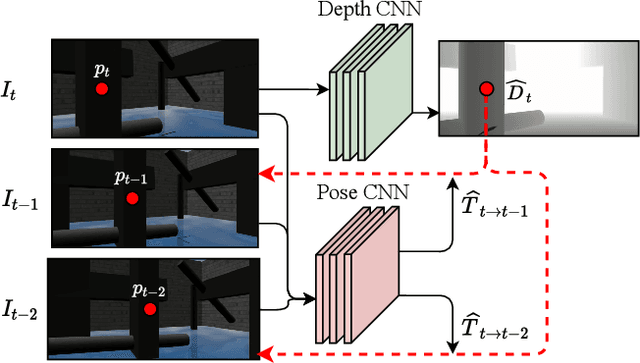
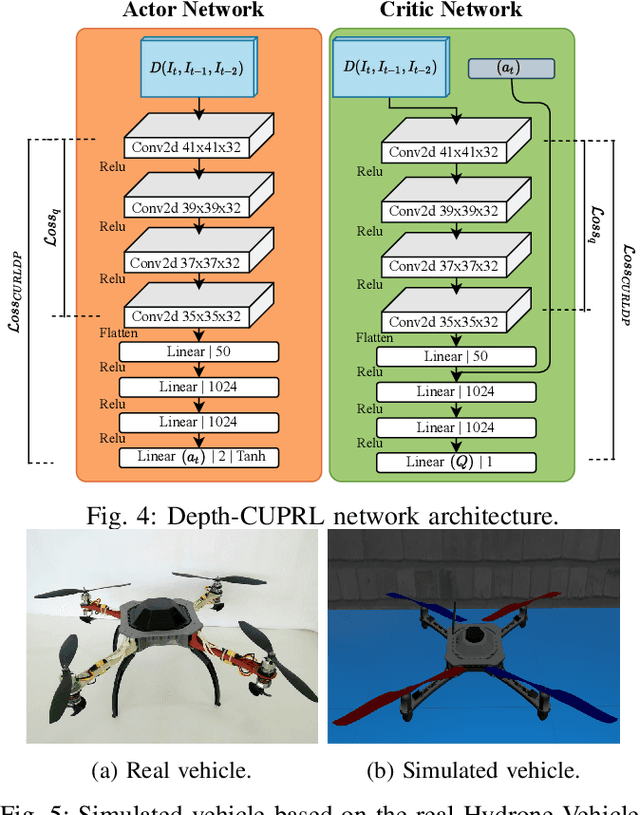
Reinforcement Learning (RL) has presented an impressive performance in video games through raw pixel imaging and continuous control tasks. However, RL performs poorly with high-dimensional observations such as raw pixel images. It is generally accepted that physical state-based RL policies such as laser sensor measurements give a more sample-efficient result than learning by pixels. This work presents a new approach that extracts information from a depth map estimation to teach an RL agent to perform the mapless navigation of Unmanned Aerial Vehicle (UAV). We propose the Depth-Imaged Contrastive Unsupervised Prioritized Representations in Reinforcement Learning(Depth-CUPRL) that estimates the depth of images with a prioritized replay memory. We used a combination of RL and Contrastive Learning to lead with the problem of RL based on images. From the analysis of the results with Unmanned Aerial Vehicles (UAVs), it is possible to conclude that our Depth-CUPRL approach is effective for the decision-making and outperforms state-of-the-art pixel-based approaches in the mapless navigation capability.
Deep Reinforcement Learning Using a Low-Dimensional Observation Filter for Visual Complex Video Game Playing
Apr 24, 2022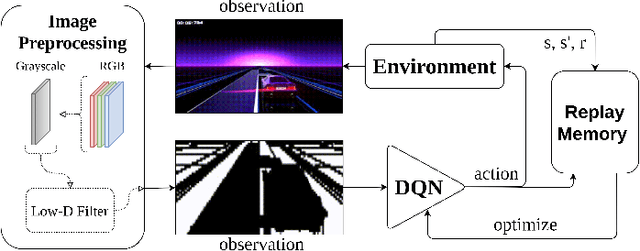
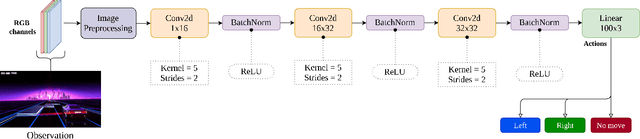
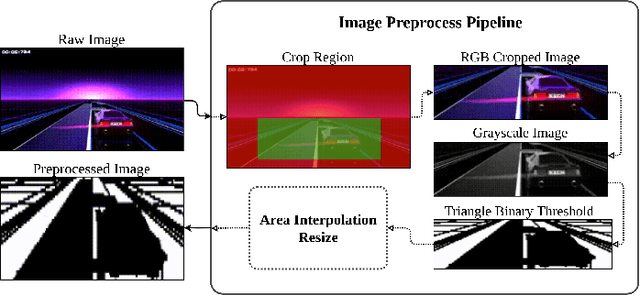
Deep Reinforcement Learning (DRL) has produced great achievements since it was proposed, including the possibility of processing raw vision input data. However, training an agent to perform tasks based on image feedback remains a challenge. It requires the processing of large amounts of data from high-dimensional observation spaces, frame by frame, and the agent's actions are computed according to deep neural network policies, end-to-end. Image pre-processing is an effective way of reducing these high dimensional spaces, eliminating unnecessary information present in the scene, supporting the extraction of features and their representations in the agent's neural network. Modern video-games are examples of this type of challenge for DRL algorithms because of their visual complexity. In this paper, we propose a low-dimensional observation filter that allows a deep Q-network agent to successfully play in a visually complex and modern video-game, called Neon Drive.
Double Critic Deep Reinforcement Learning for Mapless 3D Navigation of Unmanned Aerial Vehicles
Dec 27, 2021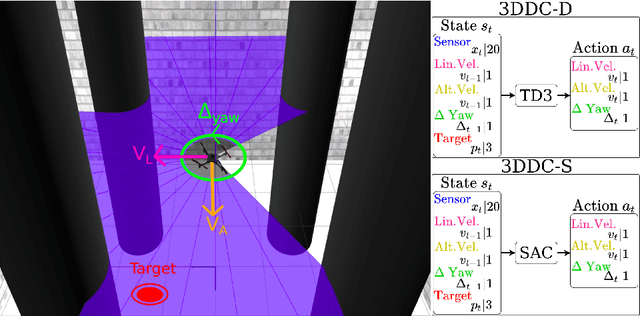
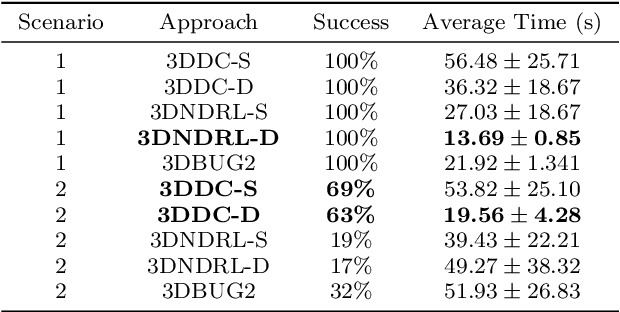
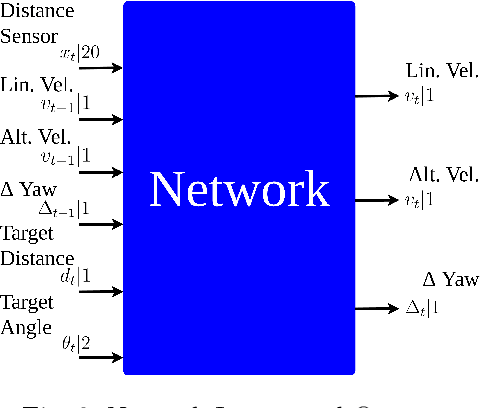
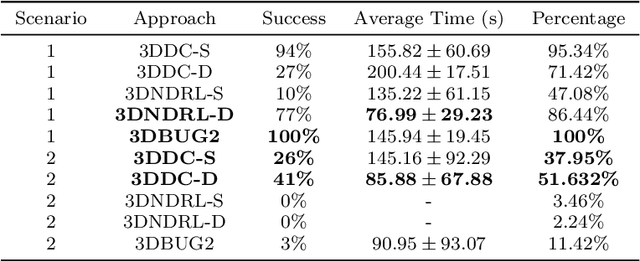
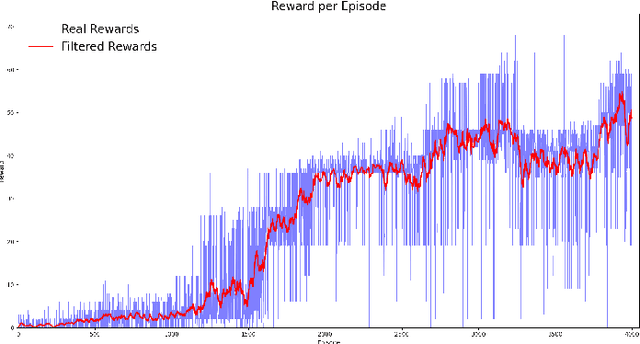
This paper presents a novel deep reinforcement learning-based system for 3D mapless navigation for Unmanned Aerial Vehicles (UAVs). Instead of using a image-based sensing approach, we propose a simple learning system that uses only a few sparse range data from a distance sensor to train a learning agent. We based our approaches on two state-of-art double critic Deep-RL models: Twin Delayed Deep Deterministic Policy Gradient (TD3) and Soft Actor-Critic (SAC). We show that our two approaches manage to outperform an approach based on the Deep Deterministic Policy Gradient (DDPG) technique and the BUG2 algorithm. Also, our new Deep-RL structure based on Recurrent Neural Networks (RNNs) outperforms the current structure used to perform mapless navigation of mobile robots. Overall, we conclude that Deep-RL approaches based on double critic with Recurrent Neural Networks (RNNs) are better suited to perform mapless navigation and obstacle avoidance of UAVs.
Deep Reinforcement Learning for Mapless Navigation of a Hybrid Aerial Underwater Vehicle with Medium Transition
Mar 28, 2021

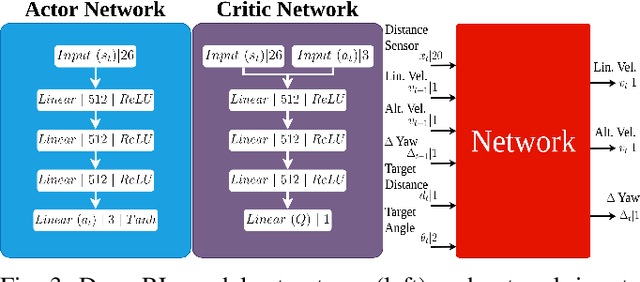
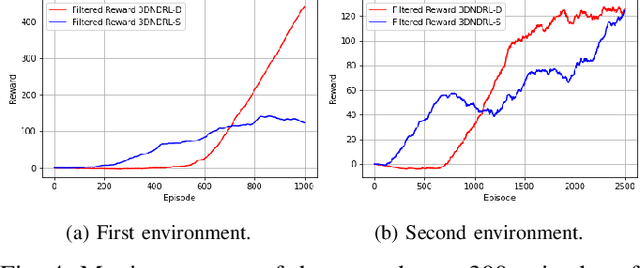
Since the application of Deep Q-Learning to the continuous action domain in Atari-like games, Deep Reinforcement Learning (Deep-RL) techniques for motion control have been qualitatively enhanced. Nowadays, modern Deep-RL can be successfully applied to solve a wide range of complex decision-making tasks for many types of vehicles. Based on this context, in this paper, we propose the use of Deep-RL to perform autonomous mapless navigation for Hybrid Unmanned Aerial Underwater Vehicles (HUAUVs), robots that can operate in both, air or water media. We developed two approaches, one deterministic and the other stochastic. Our system uses the relative localization of the vehicle and simple sparse range data to train the network. We compared our approaches with a traditional geometric tracking controller for mapless navigation. Based on experimental results, we can conclude that Deep-RL-based approaches can be successfully used to perform mapless navigation and obstacle avoidance for HUAUVs. Our vehicle accomplished the navigation in two scenarios, being capable to achieve the desired target through both environments, and even outperforming the geometric-based tracking controller on the obstacle-avoidance capability.