 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMobile Robots through Task-Based Human Instructions using Incremental Curriculum Learning
Dec 26, 2024



This paper explores the integration of incremental curriculum learning (ICL) with deep reinforcement learning (DRL) techniques to facilitate mobile robot navigation through task-based human instruction. By adopting a curriculum that mirrors the progressive complexity encountered in human learning, our approach systematically enhances robots' ability to interpret and execute complex instructions over time. We explore the principles of DRL and its synergy with ICL, demonstrating how this combination not only improves training efficiency but also equips mobile robots with the generalization capability required for navigating through dynamic indoor environments. Empirical results indicate that robots trained with our ICL-enhanced DRL framework outperform those trained without curriculum learning, highlighting the benefits of structured learning progressions in robotic training.
CURLing the Dream: Contrastive Representations for World Modeling in Reinforcement Learning
Aug 11, 2024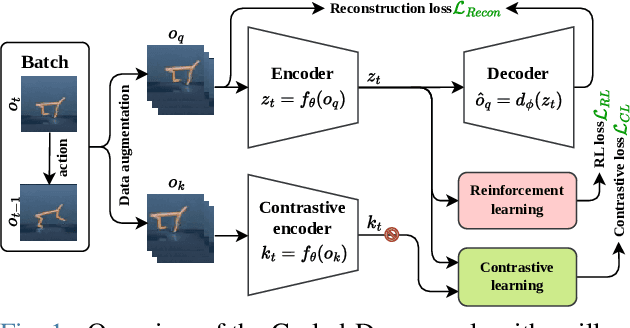



In this work, we present Curled-Dreamer, a novel reinforcement learning algorithm that integrates contrastive learning into the DreamerV3 framework to enhance performance in visual reinforcement learning tasks. By incorporating the contrastive loss from the CURL algorithm and a reconstruction loss from autoencoder, Curled-Dreamer achieves significant improvements in various DeepMind Control Suite tasks. Our extensive experiments demonstrate that Curled-Dreamer consistently outperforms state-of-the-art algorithms, achieving higher mean and median scores across a diverse set of tasks. The results indicate that the proposed approach not only accelerates learning but also enhances the robustness of the learned policies. This work highlights the potential of combining different learning paradigms to achieve superior performance in reinforcement learning applications.
Parallel Distributional Deep Reinforcement Learning for Mapless Navigation of Terrestrial Mobile Robots
Aug 11, 2024
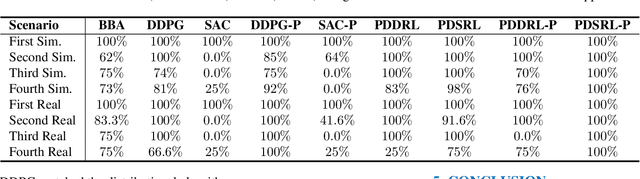
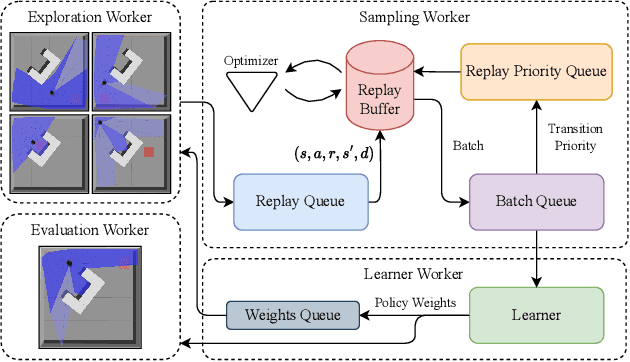

This paper introduces novel deep reinforcement learning (Deep-RL) techniques using parallel distributional actor-critic networks for navigating terrestrial mobile robots. Our approaches use laser range findings, relative distance, and angle to the target to guide the robot. We trained agents in the Gazebo simulator and deployed them in real scenarios. Results show that parallel distributional Deep-RL algorithms enhance decision-making and outperform non-distributional and behavior-based approaches in navigation and spatial generalization.
Kolmogorov-Arnold Network for Online Reinforcement Learning
Aug 09, 2024


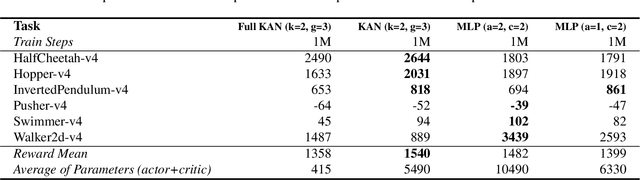
Kolmogorov-Arnold Networks (KANs) have shown potential as an alternative to Multi-Layer Perceptrons (MLPs) in neural networks, providing universal function approximation with fewer parameters and reduced memory usage. In this paper, we explore the use of KANs as function approximators within the Proximal Policy Optimization (PPO) algorithm. We evaluate this approach by comparing its performance to the original MLP-based PPO using the DeepMind Control Proprio Robotics benchmark. Our results indicate that the KAN-based reinforcement learning algorithm can achieve comparable performance to its MLP-based counterpart, often with fewer parameters. These findings suggest that KANs may offer a more efficient option for reinforcement learning models.
Precision and Adaptability of YOLOv5 and YOLOv8 in Dynamic Robotic Environments
Jun 01, 2024Recent advancements in real-time object detection frameworks have spurred extensive research into their application in robotic systems. This study provides a comparative analysis of YOLOv5 and YOLOv8 models, challenging the prevailing assumption of the latter's superiority in performance metrics. Contrary to initial expectations, YOLOv5 models demonstrated comparable, and in some cases superior, precision in object detection tasks. Our analysis delves into the underlying factors contributing to these findings, examining aspects such as model architecture complexity, training dataset variances, and real-world applicability. Through rigorous testing and an ablation study, we present a nuanced understanding of each model's capabilities, offering insights into the selection and optimization of object detection frameworks for robotic applications. Implications of this research extend to the design of more efficient and contextually adaptive systems, emphasizing the necessity for a holistic approach to evaluating model performance.
Advancing Behavior Generation in Mobile Robotics through High-Fidelity Procedural Simulations
May 27, 2024



This paper introduces YamaS, a simulator integrating Unity3D Engine with Robotic Operating System for robot navigation research and aims to facilitate the development of both Deep Reinforcement Learning (Deep-RL) and Natural Language Processing (NLP). It supports single and multi-agent configurations with features like procedural environment generation, RGB vision, and dynamic obstacle navigation. Unique to YamaS is its ability to construct single and multi-agent environments, as well as generating agent's behaviour through textual descriptions. The simulator's fidelity is underscored by comparisons with the real-world Yamabiko Beego robot, demonstrating high accuracy in sensor simulations and spatial reasoning. Moreover, YamaS integrates Virtual Reality (VR) to augment Human-Robot Interaction (HRI) studies, providing an immersive platform for developers and researchers. This fusion establishes YamaS as a versatile and valuable tool for the development and testing of autonomous systems, contributing to the fields of robot simulation and AI-driven training methodologies.