 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKolmogorov-Arnold Network for Online Reinforcement Learning
Paper and Code



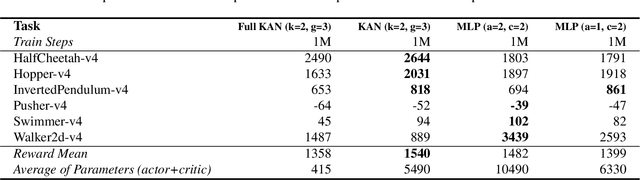
Kolmogorov-Arnold Networks (KANs) have shown potential as an alternative to Multi-Layer Perceptrons (MLPs) in neural networks, providing universal function approximation with fewer parameters and reduced memory usage. In this paper, we explore the use of KANs as function approximators within the Proximal Policy Optimization (PPO) algorithm. We evaluate this approach by comparing its performance to the original MLP-based PPO using the DeepMind Control Proprio Robotics benchmark. Our results indicate that the KAN-based reinforcement learning algorithm can achieve comparable performance to its MLP-based counterpart, often with fewer parameters. These findings suggest that KANs may offer a more efficient option for reinforcement learning models.