 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCURLing the Dream: Contrastive Representations for World Modeling in Reinforcement Learning
Aug 11, 2024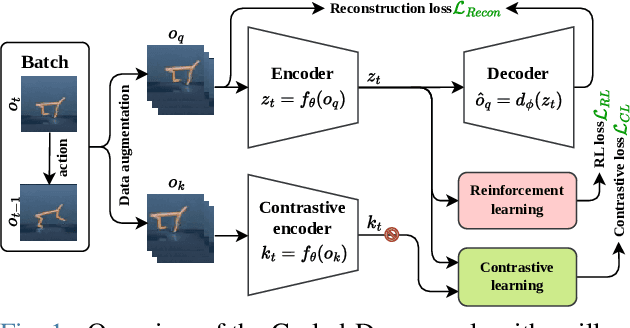



In this work, we present Curled-Dreamer, a novel reinforcement learning algorithm that integrates contrastive learning into the DreamerV3 framework to enhance performance in visual reinforcement learning tasks. By incorporating the contrastive loss from the CURL algorithm and a reconstruction loss from autoencoder, Curled-Dreamer achieves significant improvements in various DeepMind Control Suite tasks. Our extensive experiments demonstrate that Curled-Dreamer consistently outperforms state-of-the-art algorithms, achieving higher mean and median scores across a diverse set of tasks. The results indicate that the proposed approach not only accelerates learning but also enhances the robustness of the learned policies. This work highlights the potential of combining different learning paradigms to achieve superior performance in reinforcement learning applications.
Kolmogorov-Arnold Network for Online Reinforcement Learning
Aug 09, 2024


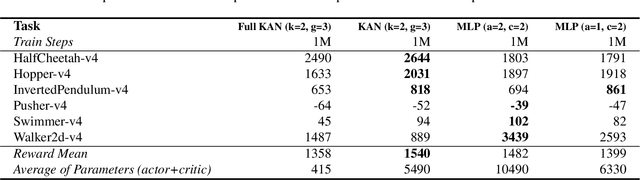
Kolmogorov-Arnold Networks (KANs) have shown potential as an alternative to Multi-Layer Perceptrons (MLPs) in neural networks, providing universal function approximation with fewer parameters and reduced memory usage. In this paper, we explore the use of KANs as function approximators within the Proximal Policy Optimization (PPO) algorithm. We evaluate this approach by comparing its performance to the original MLP-based PPO using the DeepMind Control Proprio Robotics benchmark. Our results indicate that the KAN-based reinforcement learning algorithm can achieve comparable performance to its MLP-based counterpart, often with fewer parameters. These findings suggest that KANs may offer a more efficient option for reinforcement learning models.
Improving Generalization in Aerial and Terrestrial Mobile Robots Control Through Delayed Policy Learning
Jun 04, 2024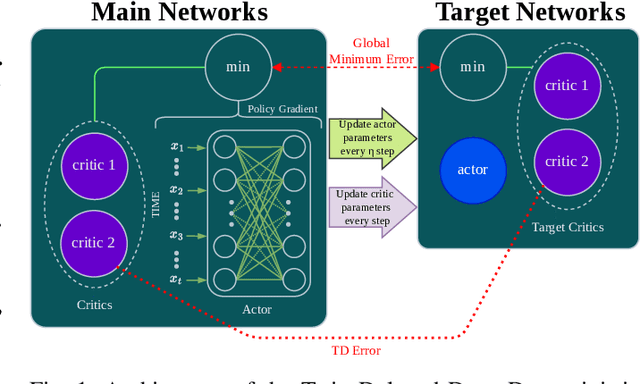
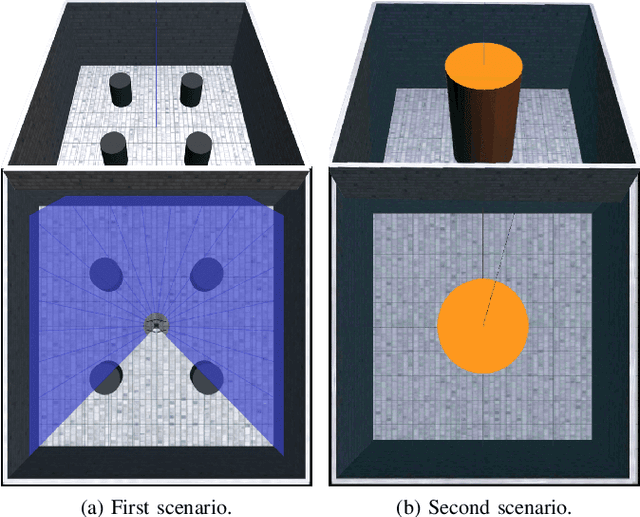
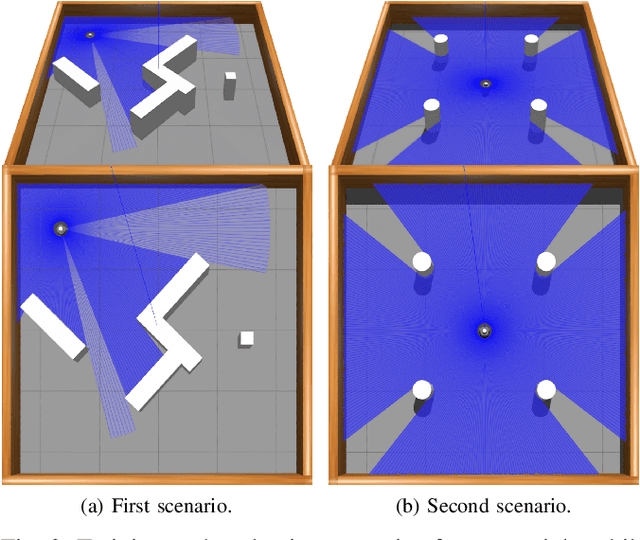
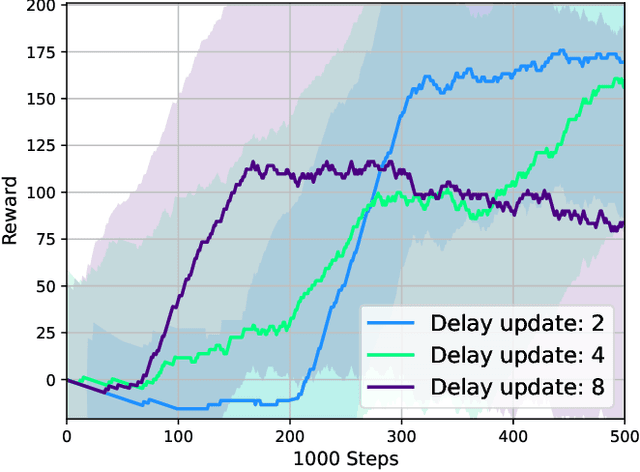
Deep Reinforcement Learning (DRL) has emerged as a promising approach to enhancing motion control and decision-making through a wide range of robotic applications. While prior research has demonstrated the efficacy of DRL algorithms in facilitating autonomous mapless navigation for aerial and terrestrial mobile robots, these methods often grapple with poor generalization when faced with unknown tasks and environments. This paper explores the impact of the Delayed Policy Updates (DPU) technique on fostering generalization to new situations, and bolstering the overall performance of agents. Our analysis of DPU in aerial and terrestrial mobile robots reveals that this technique significantly curtails the lack of generalization and accelerates the learning process for agents, enhancing their efficiency across diverse tasks and unknown scenarios.
From Seedling to Harvest: The GrowingSoy Dataset for Weed Detection in Soy Crops via Instance Segmentation
Jun 01, 2024Deep learning, particularly Convolutional Neural Networks (CNNs), has gained significant attention for its effectiveness in computer vision, especially in agricultural tasks. Recent advancements in instance segmentation have improved image classification accuracy. In this work, we introduce a comprehensive dataset for training neural networks to detect weeds and soy plants through instance segmentation. Our dataset covers various stages of soy growth, offering a chronological perspective on weed invasion's impact, with 1,000 meticulously annotated images. We also provide 6 state of the art models, trained in this dataset, that can understand and detect soy and weed in every stage of the plantation process. By using this dataset for weed and soy segmentation, we achieved a segmentation average precision of 79.1% and an average recall of 69.2% across all plant classes, with the YOLOv8X model. Moreover, the YOLOv8M model attained 78.7% mean average precision (mAp-50) in caruru weed segmentation, 69.7% in grassy weed segmentation, and 90.1% in soy plant segmentation.
Advancing Behavior Generation in Mobile Robotics through High-Fidelity Procedural Simulations
May 27, 2024



This paper introduces YamaS, a simulator integrating Unity3D Engine with Robotic Operating System for robot navigation research and aims to facilitate the development of both Deep Reinforcement Learning (Deep-RL) and Natural Language Processing (NLP). It supports single and multi-agent configurations with features like procedural environment generation, RGB vision, and dynamic obstacle navigation. Unique to YamaS is its ability to construct single and multi-agent environments, as well as generating agent's behaviour through textual descriptions. The simulator's fidelity is underscored by comparisons with the real-world Yamabiko Beego robot, demonstrating high accuracy in sensor simulations and spatial reasoning. Moreover, YamaS integrates Virtual Reality (VR) to augment Human-Robot Interaction (HRI) studies, providing an immersive platform for developers and researchers. This fusion establishes YamaS as a versatile and valuable tool for the development and testing of autonomous systems, contributing to the fields of robot simulation and AI-driven training methodologies.
Double Deep Reinforcement Learning Techniques for Low Dimensional Sensing Mapless Navigation of Terrestrial Mobile Robots
Jan 26, 2023In this work, we present two Deep Reinforcement Learning (Deep-RL) approaches to enhance the problem of mapless navigation for a terrestrial mobile robot. Our methodology focus on comparing a Deep-RL technique based on the Deep Q-Network (DQN) algorithm with a second one based on the Double Deep Q-Network (DDQN) algorithm. We use 24 laser measurement samples and the relative position and angle of the agent to the target as information for our agents, which provide the actions as velocities for our robot. By using a low-dimensional sensing structure of learning, we show that it is possible to train an agent to perform navigation-related tasks and obstacle avoidance without using complex sensing information. The proposed methodology was successfully used in three distinct simulated environments. Overall, it was shown that Double Deep structures further enhance the problem for the navigation of mobile robots when compared to the ones with simple Q structures.
Virtual Reality Platform to Develop and Test Applications on Human-Robot Social Interaction
Aug 13, 2022
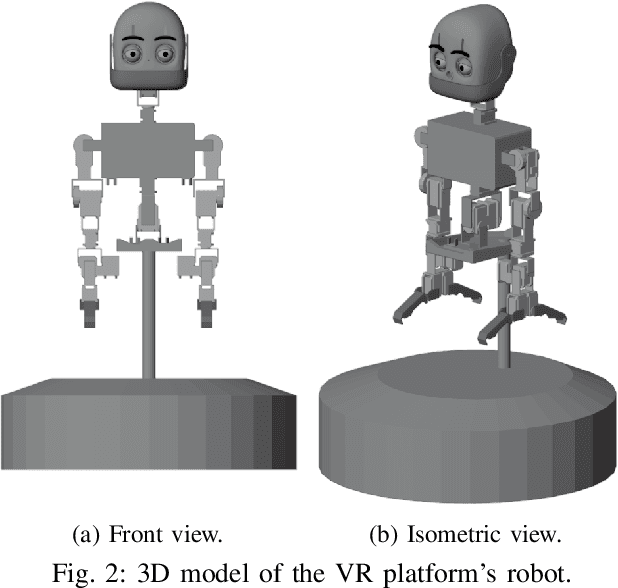
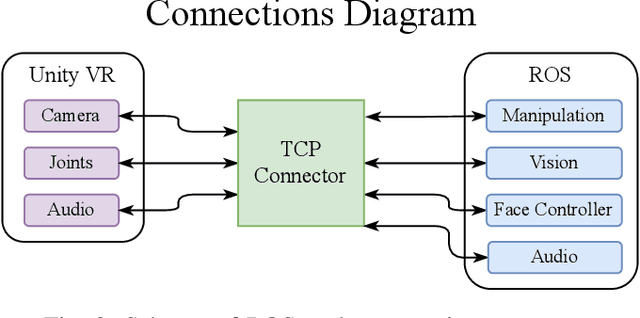

Robotics simulation has been an integral part of research and development in the robotics area. The simulation eliminates the possibility of harm to sensors, motors, and the physical structure of a real robot by enabling robotics application testing to be carried out quickly and affordably without being subjected to mechanical or electronic errors. Simulation through virtual reality (VR) offers a more immersive experience by providing better visual cues of environments, making it an appealing alternative for interacting with simulated robots. This immersion is crucial, particularly when discussing sociable robots, a subarea of the human-robot interaction (HRI) field. The widespread use of robots in daily life depends on HRI. In the future, robots will be able to interact effectively with people to perform a variety of tasks in human civilization. It is crucial to develop simple and understandable interfaces for robots as they begin to proliferate in the personal workspace. Due to this, in this study, we implement a VR robotic framework with ready-to-use tools and packages to enhance research and application development in social HRI. Since the entire VR interface is an open-source project, the tests can be conducted in an immersive environment without needing a physical robot.