 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Generalization in Aerial and Terrestrial Mobile Robots Control Through Delayed Policy Learning
Jun 04, 2024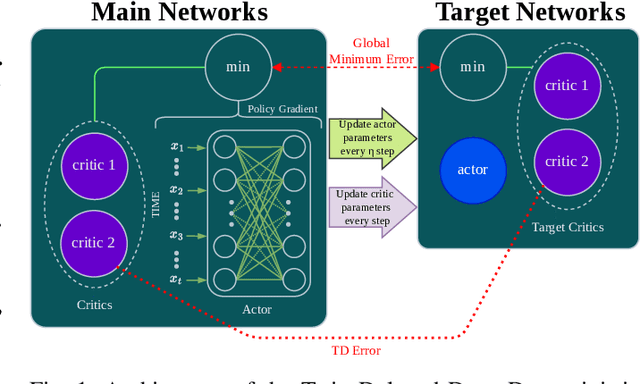
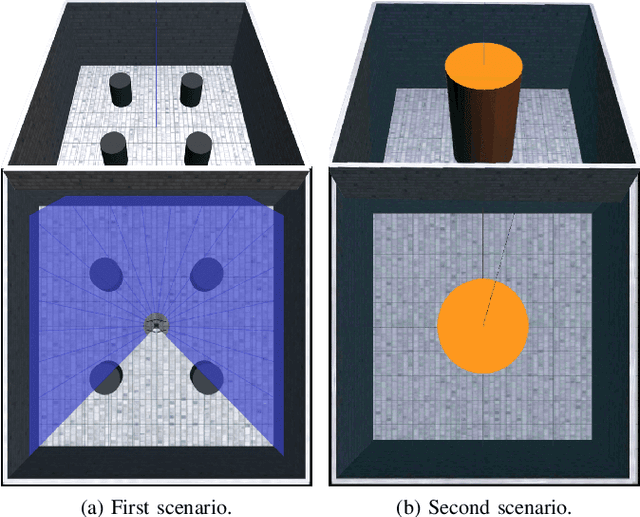
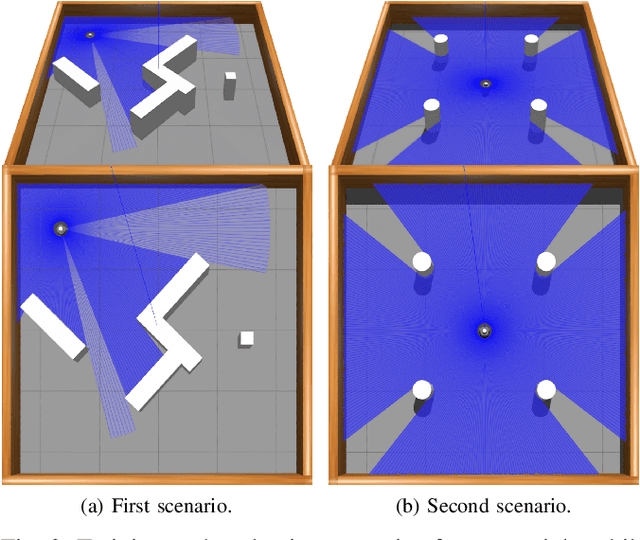
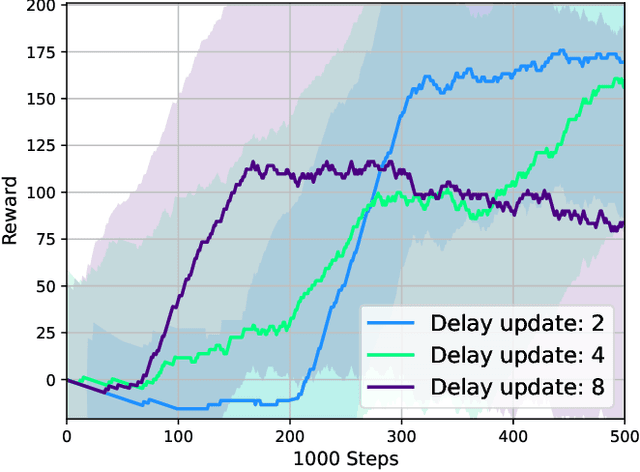
Deep Reinforcement Learning (DRL) has emerged as a promising approach to enhancing motion control and decision-making through a wide range of robotic applications. While prior research has demonstrated the efficacy of DRL algorithms in facilitating autonomous mapless navigation for aerial and terrestrial mobile robots, these methods often grapple with poor generalization when faced with unknown tasks and environments. This paper explores the impact of the Delayed Policy Updates (DPU) technique on fostering generalization to new situations, and bolstering the overall performance of agents. Our analysis of DPU in aerial and terrestrial mobile robots reveals that this technique significantly curtails the lack of generalization and accelerates the learning process for agents, enhancing their efficiency across diverse tasks and unknown scenarios.
DoCRL: Double Critic Deep Reinforcement Learning for Mapless Navigation of a Hybrid Aerial Underwater Vehicle with Medium Transition
Aug 18, 2023


Deep Reinforcement Learning (Deep-RL) techniques for motion control have been continuously used to deal with decision-making problems for a wide variety of robots. Previous works showed that Deep-RL can be applied to perform mapless navigation, including the medium transition of Hybrid Unmanned Aerial Underwater Vehicles (HUAUVs). These are robots that can operate in both air and water media, with future potential for rescue tasks in robotics. This paper presents new approaches based on the state-of-the-art Double Critic Actor-Critic algorithms to address the navigation and medium transition problems for a HUAUV. We show that double-critic Deep-RL with Recurrent Neural Networks using range data and relative localization solely improves the navigation performance of HUAUVs. Our DoCRL approaches achieved better navigation and transitioning capability, outperforming previous approaches.
Mapless Navigation of a Hybrid Aerial Underwater Vehicle with Deep Reinforcement Learning Through Environmental Generalization
Sep 13, 2022

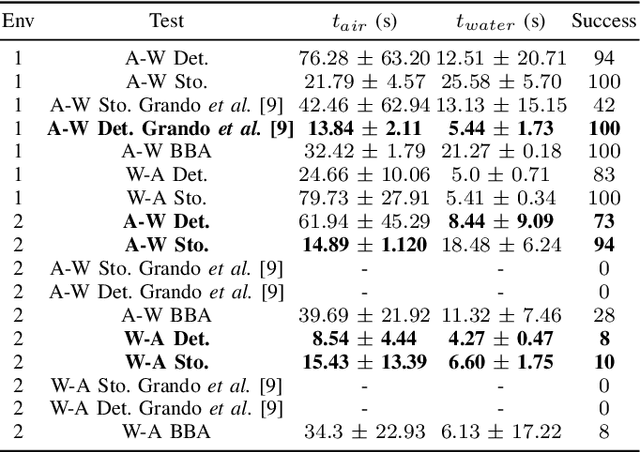

Previous works showed that Deep-RL can be applied to perform mapless navigation, including the medium transition of Hybrid Unmanned Aerial Underwater Vehicles (HUAUVs). This paper presents new approaches based on the state-of-the-art actor-critic algorithms to address the navigation and medium transition problems for a HUAUV. We show that a double critic Deep-RL with Recurrent Neural Networks improves the navigation performance of HUAUVs using solely range data and relative localization. Our Deep-RL approaches achieved better navigation and transitioning capabilities with a solid generalization of learning through distinct simulated scenarios, outperforming previous approaches.
Deterministic and Stochastic Analysis of Deep Reinforcement Learning for Low Dimensional Sensing-based Navigation of Mobile Robots
Sep 13, 2022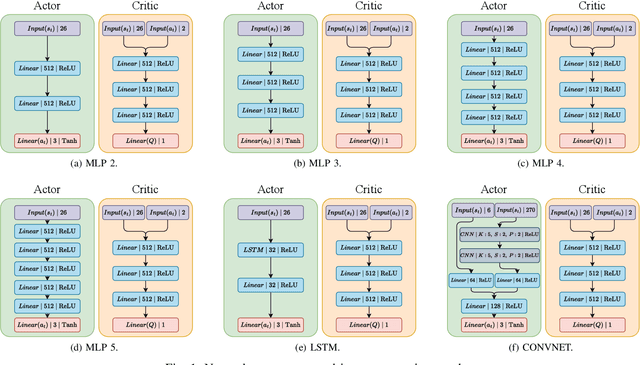

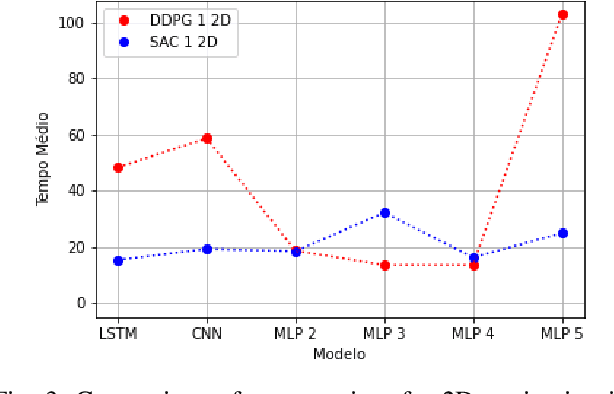
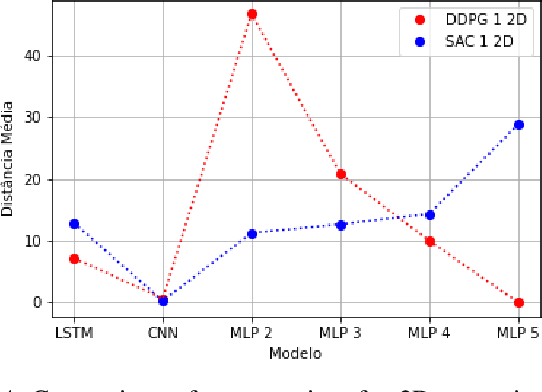
Deterministic and Stochastic techniques in Deep Reinforcement Learning (Deep-RL) have become a promising solution to improve motion control and the decision-making tasks for a wide variety of robots. Previous works showed that these Deep-RL algorithms can be applied to perform mapless navigation of mobile robots in general. However, they tend to use simple sensing strategies since it has been shown that they perform poorly with a high dimensional state spaces, such as the ones yielded from image-based sensing. This paper presents a comparative analysis of two Deep-RL techniques - Deep Deterministic Policy Gradients (DDPG) and Soft Actor-Critic (SAC) - when performing tasks of mapless navigation for mobile robots. We aim to contribute by showing how the neural network architecture influences the learning itself, presenting quantitative results based on the time and distance of navigation of aerial mobile robots for each approach. Overall, our analysis of six distinct architectures highlights that the stochastic approach (SAC) better suits with deeper architectures, while the opposite happens with the deterministic approach (DDPG).