 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Generalization in Aerial and Terrestrial Mobile Robots Control Through Delayed Policy Learning
Jun 04, 2024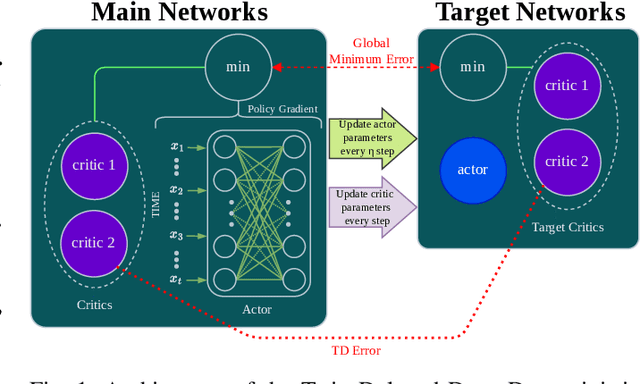
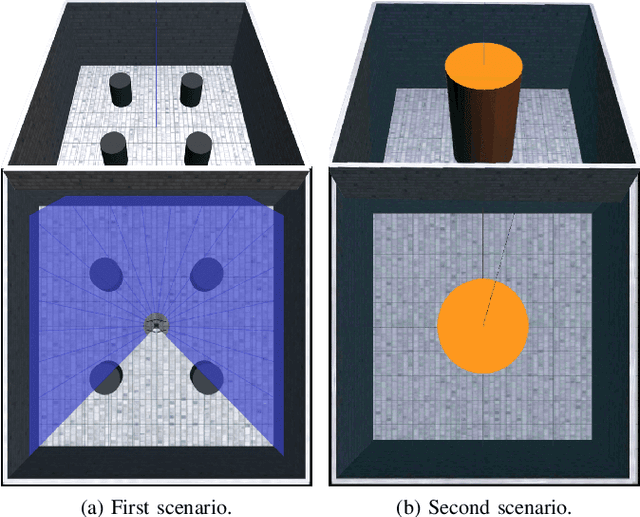
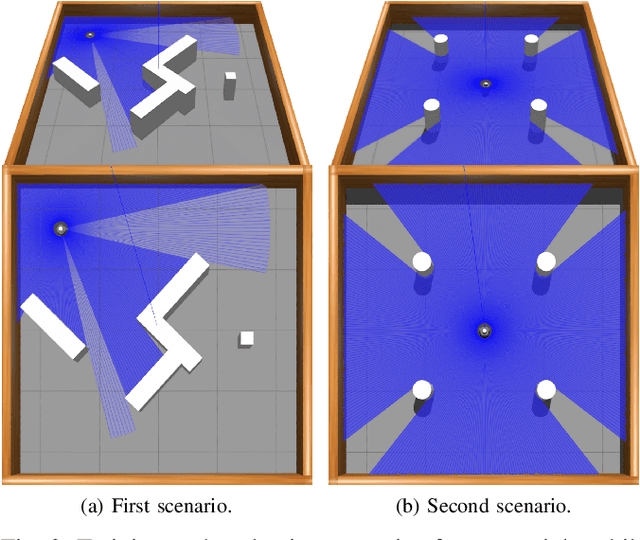
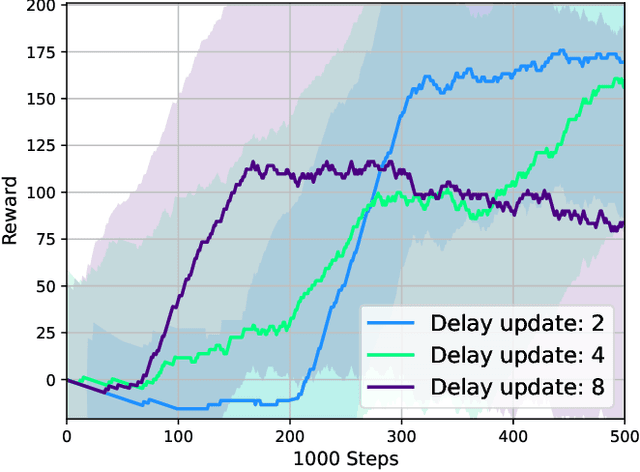
Deep Reinforcement Learning (DRL) has emerged as a promising approach to enhancing motion control and decision-making through a wide range of robotic applications. While prior research has demonstrated the efficacy of DRL algorithms in facilitating autonomous mapless navigation for aerial and terrestrial mobile robots, these methods often grapple with poor generalization when faced with unknown tasks and environments. This paper explores the impact of the Delayed Policy Updates (DPU) technique on fostering generalization to new situations, and bolstering the overall performance of agents. Our analysis of DPU in aerial and terrestrial mobile robots reveals that this technique significantly curtails the lack of generalization and accelerates the learning process for agents, enhancing their efficiency across diverse tasks and unknown scenarios.