 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross domain Persistent Monitoring for Hybrid Aerial Underwater Vehicles
Feb 23, 2026Hybrid Unmanned Aerial Underwater Vehicles (HUAUVs) have emerged as platforms capable of operating in both aerial and underwater environments, enabling applications such as inspection, mapping, search, and rescue in challenging scenarios. However, the development of novel methodologies poses significant challenges due to the distinct dynamics and constraints of the air and water domains. In this work, we present persistent monitoring tasks for HUAUVs by combining Deep Reinforcement Learning (DRL) and Transfer Learning to enable cross-domain adaptability. Our approach employs a shared DRL architecture trained on Lidar sensor data (on air) and Sonar data (underwater), demonstrating the feasibility of a unified policy for both environments. We further show that the methodology presents promising results, taking into account the uncertainty of the environment and the dynamics of multiple mobile targets. The proposed framework lays the groundwork for scalable autonomous persistent monitoring solutions based on DRL for hybrid aerial-underwater vehicles.
AquaFeat: A Features-Based Image Enhancement Model for Underwater Object Detection
Aug 17, 2025The severe image degradation in underwater environments impairs object detection models, as traditional image enhancement methods are often not optimized for such downstream tasks. To address this, we propose AquaFeat, a novel, plug-and-play module that performs task-driven feature enhancement. Our approach integrates a multi-scale feature enhancement network trained end-to-end with the detector's loss function, ensuring the enhancement process is explicitly guided to refine features most relevant to the detection task. When integrated with YOLOv8m on challenging underwater datasets, AquaFeat achieves state-of-the-art Precision (0.877) and Recall (0.624), along with competitive mAP scores (mAP@0.5 of 0.677 and mAP@[0.5:0.95] of 0.421). By delivering these accuracy gains while maintaining a practical processing speed of 46.5 FPS, our model provides an effective and computationally efficient solution for real-world applications, such as marine ecosystem monitoring and infrastructure inspection.
Synthetic Enclosed Echoes: A New Dataset to Mitigate the Gap Between Simulated and Real-World Sonar Data
May 21, 2025



This paper introduces Synthetic Enclosed Echoes (SEE), a novel dataset designed to enhance robot perception and 3D reconstruction capabilities in underwater environments. SEE comprises high-fidelity synthetic sonar data, complemented by a smaller subset of real-world sonar data. To facilitate flexible data acquisition, a simulated environment has been developed, enabling the generation of additional data through modifications such as the inclusion of new structures or imaging sonar configurations. This hybrid approach leverages the advantages of synthetic data, including readily available ground truth and the ability to generate diverse datasets, while bridging the simulation-to-reality gap with real-world data acquired in a similar environment. The SEE dataset comprehensively evaluates acoustic data-based methods, including mathematics-based sonar approaches and deep learning algorithms. These techniques were employed to validate the dataset, confirming its suitability for underwater 3D reconstruction. Furthermore, this paper proposes a novel modification to a state-of-the-art algorithm, demonstrating improved performance compared to existing methods. The SEE dataset enables the evaluation of acoustic data-based methods in realistic scenarios, thereby improving their feasibility for real-world underwater applications.
UDBE: Unsupervised Diffusion-based Brightness Enhancement in Underwater Images
Jan 27, 2025Activities in underwater environments are paramount in several scenarios, which drives the continuous development of underwater image enhancement techniques. A major challenge in this domain is the depth at which images are captured, with increasing depth resulting in a darker environment. Most existing methods for underwater image enhancement focus on noise removal and color adjustment, with few works dedicated to brightness enhancement. This work introduces a novel unsupervised learning approach to underwater image enhancement using a diffusion model. Our method, called UDBE, is based on conditional diffusion to maintain the brightness details of the unpaired input images. The input image is combined with a color map and a Signal-Noise Relation map (SNR) to ensure stable training and prevent color distortion in the output images. The results demonstrate that our approach achieves an impressive accuracy rate in the datasets UIEB, SUIM and RUIE, well-established underwater image benchmarks. Additionally, the experiments validate the robustness of our approach, regarding the image quality metrics PSNR, SSIM, UIQM, and UISM, indicating the good performance of the brightness enhancement process. The source code is available here: https://github.com/gusanagy/UDBE.
Improving Generalization in Aerial and Terrestrial Mobile Robots Control Through Delayed Policy Learning
Jun 04, 2024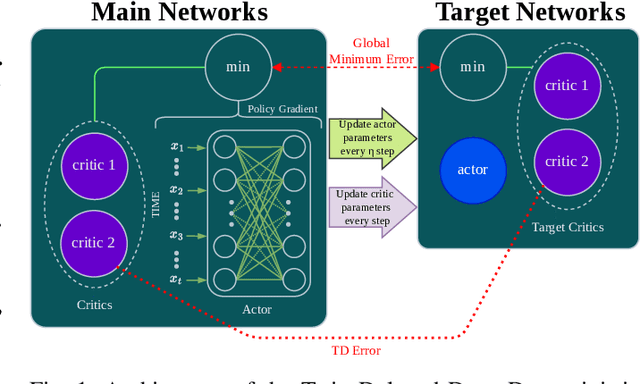
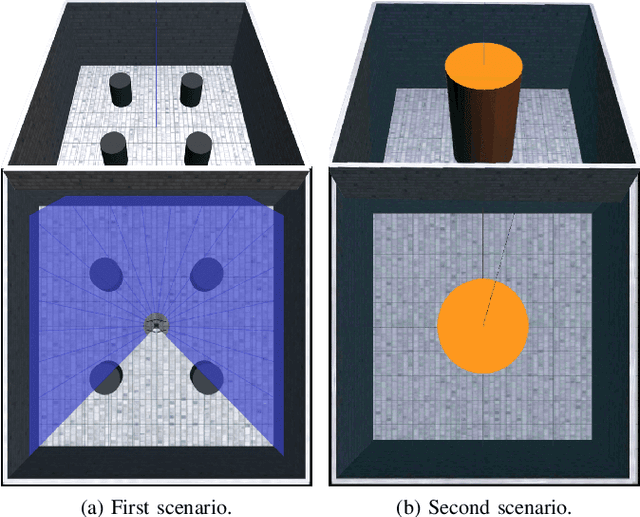
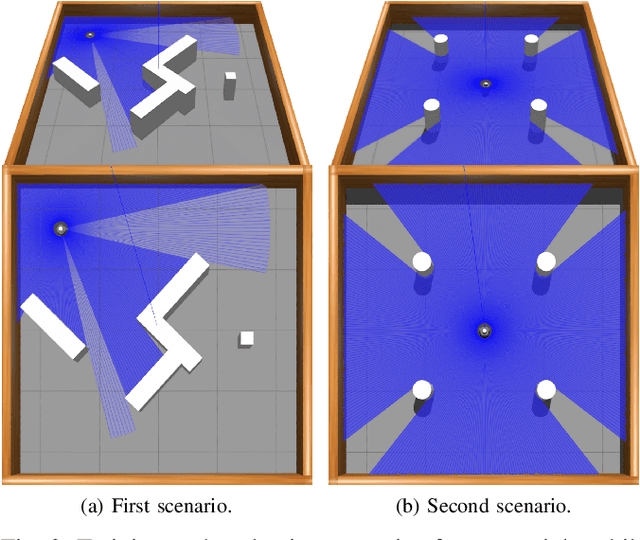
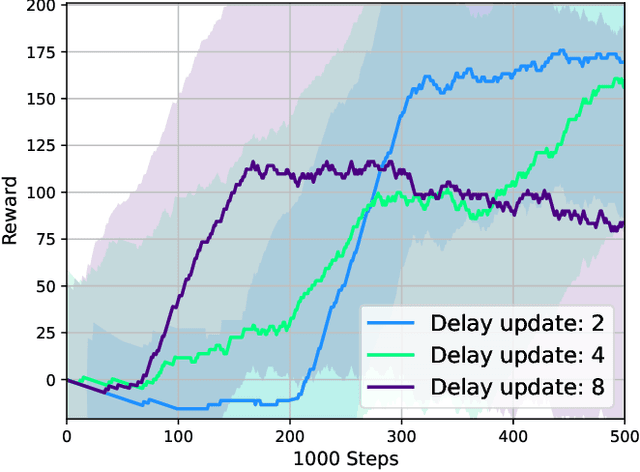
Deep Reinforcement Learning (DRL) has emerged as a promising approach to enhancing motion control and decision-making through a wide range of robotic applications. While prior research has demonstrated the efficacy of DRL algorithms in facilitating autonomous mapless navigation for aerial and terrestrial mobile robots, these methods often grapple with poor generalization when faced with unknown tasks and environments. This paper explores the impact of the Delayed Policy Updates (DPU) technique on fostering generalization to new situations, and bolstering the overall performance of agents. Our analysis of DPU in aerial and terrestrial mobile robots reveals that this technique significantly curtails the lack of generalization and accelerates the learning process for agents, enhancing their efficiency across diverse tasks and unknown scenarios.
DoCRL: Double Critic Deep Reinforcement Learning for Mapless Navigation of a Hybrid Aerial Underwater Vehicle with Medium Transition
Aug 18, 2023


Deep Reinforcement Learning (Deep-RL) techniques for motion control have been continuously used to deal with decision-making problems for a wide variety of robots. Previous works showed that Deep-RL can be applied to perform mapless navigation, including the medium transition of Hybrid Unmanned Aerial Underwater Vehicles (HUAUVs). These are robots that can operate in both air and water media, with future potential for rescue tasks in robotics. This paper presents new approaches based on the state-of-the-art Double Critic Actor-Critic algorithms to address the navigation and medium transition problems for a HUAUV. We show that double-critic Deep-RL with Recurrent Neural Networks using range data and relative localization solely improves the navigation performance of HUAUVs. Our DoCRL approaches achieved better navigation and transitioning capability, outperforming previous approaches.
EvCenterNet: Uncertainty Estimation for Object Detection using Evidential Learning
Mar 06, 2023Uncertainty estimation is crucial in safety-critical settings such as automated driving as it provides valuable information for several downstream tasks including high-level decision-making and path planning. In this work, we propose EvCenterNet, a novel uncertainty-aware 2D object detection framework utilizing evidential learning to directly estimate both classification and regression uncertainties. To employ evidential learning for object detection, we devise a combination of evidential and focal loss functions for the sparse heatmap inputs. We introduce class-balanced weighting for regression and heatmap prediction to tackle the class imbalance encountered by evidential learning. Moreover, we propose a learning scheme to actively utilize the predicted heatmap uncertainties to improve the detection performance by focusing on the most uncertain points. We train our model on the KITTI dataset and evaluate it on challenging out-of-distribution datasets including BDD100K and nuImages. Our experiments demonstrate that our approach improves the precision and minimizes the execution time loss in relation to the base model.
SkyEye: Self-Supervised Bird's-Eye-View Semantic Mapping Using Monocular Frontal View Images
Feb 08, 2023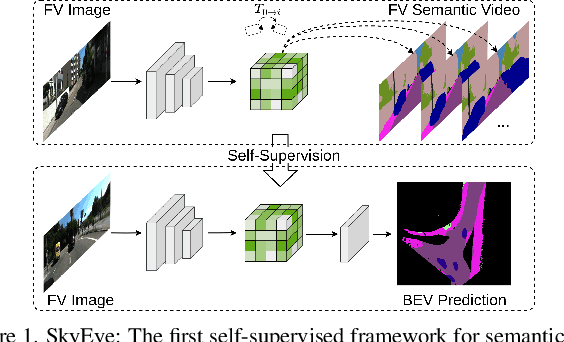



Bird's-Eye-View (BEV) semantic maps have become an essential component of automated driving pipelines due to the rich representation they provide for decision-making tasks. However, existing approaches for generating these maps still follow a fully supervised training paradigm and hence rely on large amounts of annotated BEV data. In this work, we address this limitation by proposing the first self-supervised approach for generating a BEV semantic map using a single monocular image from the frontal view (FV). During training, we overcome the need for BEV ground truth annotations by leveraging the more easily available FV semantic annotations of video sequences. Thus, we propose the SkyEye architecture that learns based on two modes of self-supervision, namely, implicit supervision and explicit supervision. Implicit supervision trains the model by enforcing spatial consistency of the scene over time based on FV semantic sequences, while explicit supervision exploits BEV pseudolabels generated from FV semantic annotations and self-supervised depth estimates. Extensive evaluations on the KITTI-360 dataset demonstrate that our self-supervised approach performs on par with the state-of-the-art fully supervised methods and achieves competitive results using only 1% of direct supervision in the BEV compared to fully supervised approaches. Finally, we publicly release both our code and the BEV datasets generated from the KITTI-360 and Waymo datasets.
Active Perception Applied To Unmanned Aerial Vehicles Through Deep Reinforcement Learning
Sep 13, 2022

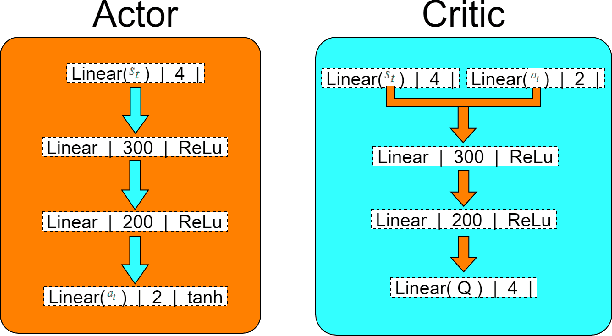
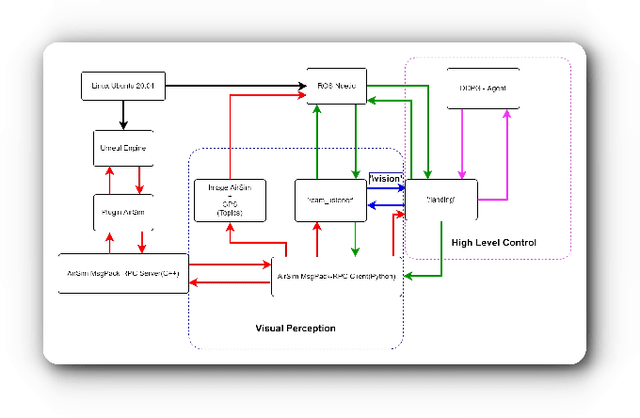
Unmanned Aerial Vehicles (UAV) have been standing out due to the wide range of applications in which they can be used autonomously. However, they need intelligent systems capable of providing a greater understanding of what they perceive to perform several tasks. They become more challenging in complex environments since there is a need to perceive the environment and act under environmental uncertainties to make a decision. In this context, a system that uses active perception can improve performance by seeking the best next view through the recognition of targets while displacement occurs. This work aims to contribute to the active perception of UAVs by tackling the problem of tracking and recognizing water surface structures to perform a dynamic landing. We show that our system with classical image processing techniques and a simple Deep Reinforcement Learning (Deep-RL) agent is capable of perceiving the environment and dealing with uncertainties without making the use of complex Convolutional Neural Networks (CNN) or Contrastive Learning (CL).
Mapless Navigation of a Hybrid Aerial Underwater Vehicle with Deep Reinforcement Learning Through Environmental Generalization
Sep 13, 2022

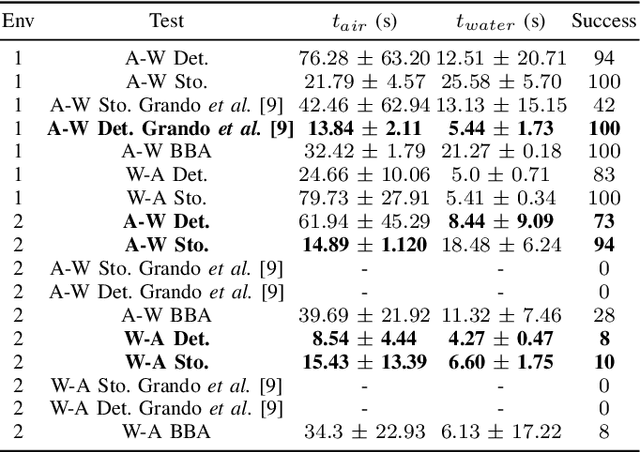

Previous works showed that Deep-RL can be applied to perform mapless navigation, including the medium transition of Hybrid Unmanned Aerial Underwater Vehicles (HUAUVs). This paper presents new approaches based on the state-of-the-art actor-critic algorithms to address the navigation and medium transition problems for a HUAUV. We show that a double critic Deep-RL with Recurrent Neural Networks improves the navigation performance of HUAUVs using solely range data and relative localization. Our Deep-RL approaches achieved better navigation and transitioning capabilities with a solid generalization of learning through distinct simulated scenarios, outperforming previous approaches.