 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLetsMap: Unsupervised Representation Learning for Semantic BEV Mapping
May 29, 2024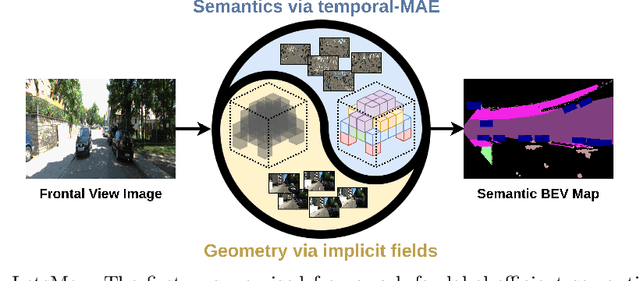
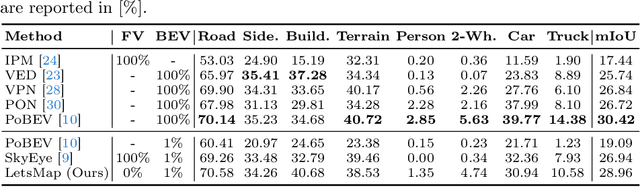
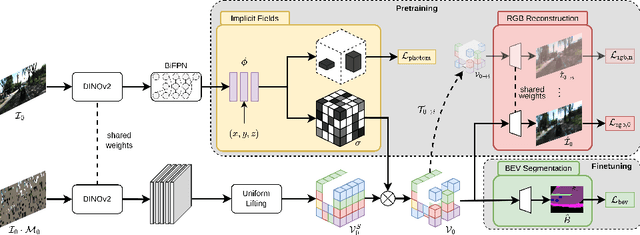
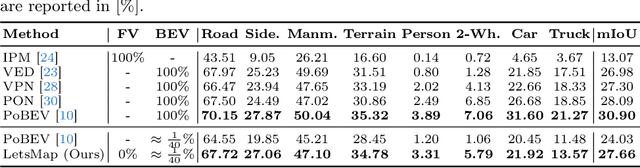
Semantic Bird's Eye View (BEV) maps offer a rich representation with strong occlusion reasoning for various decision making tasks in autonomous driving. However, most BEV mapping approaches employ a fully supervised learning paradigm that relies on large amounts of human-annotated BEV ground truth data. In this work, we address this limitation by proposing the first unsupervised representation learning approach to generate semantic BEV maps from a monocular frontal view (FV) image in a label-efficient manner. Our approach pretrains the network to independently reason about scene geometry and scene semantics using two disjoint neural pathways in an unsupervised manner and then finetunes it for the task of semantic BEV mapping using only a small fraction of labels in the BEV. We achieve label-free pretraining by exploiting spatial and temporal consistency of FV images to learn scene geometry while relying on a novel temporal masked autoencoder formulation to encode the scene representation. Extensive evaluations on the KITTI-360 and nuScenes datasets demonstrate that our approach performs on par with the existing state-of-the-art approaches while using only 1% of BEV labels and no additional labeled data.
Evaluation of a Smart Mobile Robotic System for Industrial Plant Inspection and Supervision
Feb 12, 2024



Automated and autonomous industrial inspection is a longstanding research field, driven by the necessity to enhance safety and efficiency within industrial settings. In addressing this need, we introduce an autonomously navigating robotic system designed for comprehensive plant inspection. This innovative system comprises a robotic platform equipped with a diverse array of sensors integrated to facilitate the detection of various process and infrastructure parameters. These sensors encompass optical (LiDAR, Stereo, UV/IR/RGB cameras), olfactory (electronic nose), and acoustic (microphone array) capabilities, enabling the identification of factors such as methane leaks, flow rates, and infrastructural anomalies. The proposed system underwent individual evaluation at a wastewater treatment site within a chemical plant, providing a practical and challenging environment for testing. The evaluation process encompassed key aspects such as object detection, 3D localization, and path planning. Furthermore, specific evaluations were conducted for optical methane leak detection and localization, as well as acoustic assessments focusing on pump equipment and gas leak localization.
Multi-camera Bird's Eye View Perception for Autonomous Driving
Sep 19, 2023Most automated driving systems comprise a diverse sensor set, including several cameras, Radars, and LiDARs, ensuring a complete 360\deg coverage in near and far regions. Unlike Radar and LiDAR, which measure directly in 3D, cameras capture a 2D perspective projection with inherent depth ambiguity. However, it is essential to produce perception outputs in 3D to enable the spatial reasoning of other agents and structures for optimal path planning. The 3D space is typically simplified to the BEV space by omitting the less relevant Z-coordinate, which corresponds to the height dimension.The most basic approach to achieving the desired BEV representation from a camera image is IPM, assuming a flat ground surface. Surround vision systems that are pretty common in new vehicles use the IPM principle to generate a BEV image and to show it on display to the driver. However, this approach is not suited for autonomous driving since there are severe distortions introduced by this too-simplistic transformation method. More recent approaches use deep neural networks to output directly in BEV space. These methods transform camera images into BEV space using geometric constraints implicitly or explicitly in the network. As CNN has more context information and a learnable transformation can be more flexible and adapt to image content, the deep learning-based methods set the new benchmark for BEV transformation and achieve state-of-the-art performance. First, this chapter discusses the contemporary trends of multi-camera-based DNN (deep neural network) models outputting object representations directly in the BEV space. Then, we discuss how this approach can extend to effective sensor fusion and coupling downstream tasks like situation analysis and prediction. Finally, we show challenges and open problems in BEV perception.
A Smart Robotic System for Industrial Plant Supervision
Sep 01, 2023


In today's chemical plants, human field operators perform frequent integrity checks to guarantee high safety standards, and thus are possibly the first to encounter dangerous operating conditions. To alleviate their task, we present a system consisting of an autonomously navigating robot integrated with various sensors and intelligent data processing. It is able to detect methane leaks and estimate its flow rate, detect more general gas anomalies, recognize oil films, localize sound sources and detect failure cases, map the environment in 3D, and navigate autonomously, employing recognition and avoidance of dynamic obstacles. We evaluate our system at a wastewater facility in full working conditions. Our results demonstrate that the system is able to robustly navigate the plant and provide useful information about critical operating conditions.
INoD: Injected Noise Discriminator for Self-Supervised Representation Learning in Agricultural Fields
Mar 31, 2023Perception datasets for agriculture are limited both in quantity and diversity which hinders effective training of supervised learning approaches. Self-supervised learning techniques alleviate this problem, however, existing methods are not optimized for dense prediction tasks in agriculture domains which results in degraded performance. In this work, we address this limitation with our proposed Injected Noise Discriminator (INoD) which exploits principles of feature replacement and dataset discrimination for self-supervised representation learning. INoD interleaves feature maps from two disjoint datasets during their convolutional encoding and predicts the dataset affiliation of the resultant feature map as a pretext task. Our approach enables the network to learn unequivocal representations of objects seen in one dataset while observing them in conjunction with similar features from the disjoint dataset. This allows the network to reason about higher-level semantics of the entailed objects, thus improving its performance on various downstream tasks. Additionally, we introduce the novel Fraunhofer Potato 2022 dataset consisting of over 16,800 images for object detection in potato fields. Extensive evaluations of our proposed INoD pretraining strategy for the tasks of object detection, semantic segmentation, and instance segmentation on the Sugar Beets 2016 and our potato dataset demonstrate that it achieves state-of-the-art performance.
SkyEye: Self-Supervised Bird's-Eye-View Semantic Mapping Using Monocular Frontal View Images
Feb 08, 2023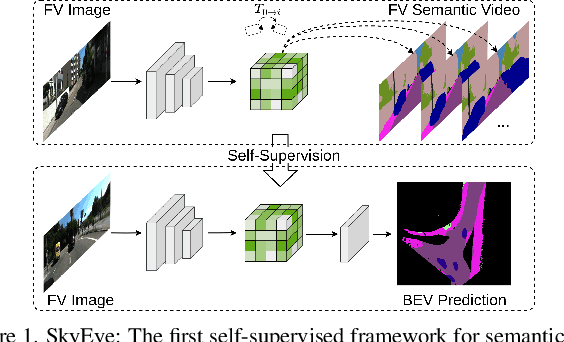



Bird's-Eye-View (BEV) semantic maps have become an essential component of automated driving pipelines due to the rich representation they provide for decision-making tasks. However, existing approaches for generating these maps still follow a fully supervised training paradigm and hence rely on large amounts of annotated BEV data. In this work, we address this limitation by proposing the first self-supervised approach for generating a BEV semantic map using a single monocular image from the frontal view (FV). During training, we overcome the need for BEV ground truth annotations by leveraging the more easily available FV semantic annotations of video sequences. Thus, we propose the SkyEye architecture that learns based on two modes of self-supervision, namely, implicit supervision and explicit supervision. Implicit supervision trains the model by enforcing spatial consistency of the scene over time based on FV semantic sequences, while explicit supervision exploits BEV pseudolabels generated from FV semantic annotations and self-supervised depth estimates. Extensive evaluations on the KITTI-360 dataset demonstrate that our self-supervised approach performs on par with the state-of-the-art fully supervised methods and achieves competitive results using only 1% of direct supervision in the BEV compared to fully supervised approaches. Finally, we publicly release both our code and the BEV datasets generated from the KITTI-360 and Waymo datasets.
Unsupervised Domain Adaptation for LiDAR Panoptic Segmentation
Sep 30, 2021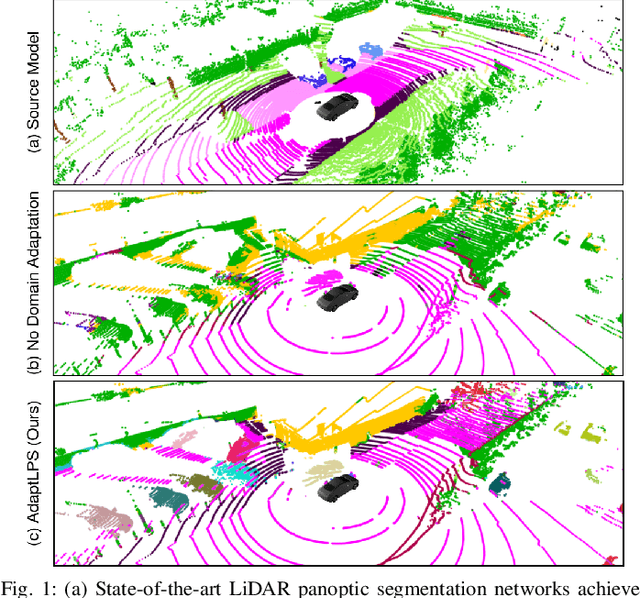
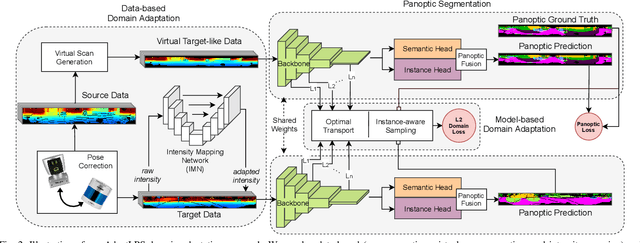
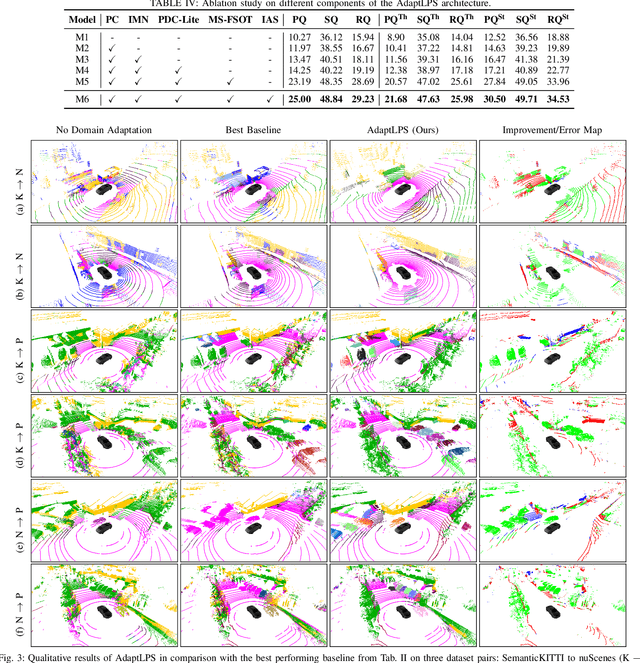
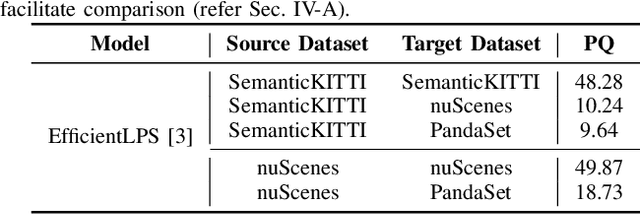
Scene understanding is a pivotal task for autonomous vehicles to safely navigate in the environment. Recent advances in deep learning enable accurate semantic reconstruction of the surroundings from LiDAR data. However, these models encounter a large domain gap while deploying them on vehicles equipped with different LiDAR setups which drastically decreases their performance. Fine-tuning the model for every new setup is infeasible due to the expensive and cumbersome process of recording and manually labeling new data. Unsupervised Domain Adaptation (UDA) techniques are thus essential to fill this domain gap and retain the performance of models on new sensor setups without the need for additional data labeling. In this paper, we propose AdaptLPS, a novel UDA approach for LiDAR panoptic segmentation that leverages task-specific knowledge and accounts for variation in the number of scan lines, mounting position, intensity distribution, and environmental conditions. We tackle the UDA task by employing two complementary domain adaptation strategies, data-based and model-based. While data-based adaptations reduce the domain gap by processing the raw LiDAR scans to resemble the scans in the target domain, model-based techniques guide the network in extracting features that are representative for both domains. Extensive evaluations on three pairs of real-world autonomous driving datasets demonstrate that AdaptLPS outperforms existing UDA approaches by up to 6.41 pp in terms of the PQ score.
Bird's-Eye-View Panoptic Segmentation Using Monocular Frontal View Images
Aug 06, 2021



Bird's-Eye-View (BEV) maps have emerged as one of the most powerful representations for scene understanding due to their ability to provide rich spatial context while being easy to interpret and process. However, generating BEV maps requires complex multi-stage paradigms that encapsulate a series of distinct tasks such as depth estimation, ground plane estimation, and semantic segmentation. These sub-tasks are often learned in a disjoint manner which prevents the model from holistic reasoning and results in erroneous BEV maps. Moreover, existing algorithms only predict the semantics in the BEV space, which limits their use in applications where the notion of object instances is critical. In this work, we present the first end-to-end learning approach for directly predicting dense panoptic segmentation maps in the BEV, given a single monocular image in the frontal view (FV). Our architecture follows the top-down paradigm and incorporates a novel dense transformer module consisting of two distinct transformers that learn to independently map vertical and flat regions in the input image from the FV to the BEV. Additionally, we derive a mathematical formulation for the sensitivity of the FV-BEV transformation which allows us to intelligently weight pixels in the BEV space to account for the varying descriptiveness across the FV image. Extensive evaluations on the KITTI-360 and nuScenes datasets demonstrate that our approach exceeds the state-of-the-art in the PQ metric by 3.61 pp and 4.93 pp respectively.
AMZ Driverless: The Full Autonomous Racing System
May 13, 2019

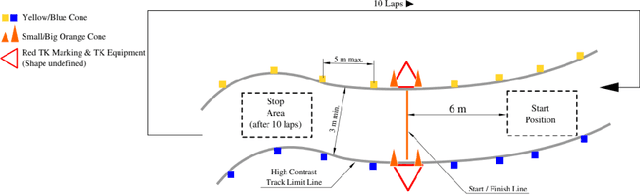

This paper presents the algorithms and system architecture of an autonomous racecar. The introduced vehicle is powered by a software stack designed for robustness, reliability, and extensibility. In order to autonomously race around a previously unknown track, the proposed solution combines state of the art techniques from different fields of robotics. Specifically, perception, estimation, and control are incorporated into one high-performance autonomous racecar. This complex robotic system, developed by AMZ Driverless and ETH Zurich, finished 1st overall at each competition we attended: Formula Student Germany 2017, Formula Student Italy 2018 and Formula Student Germany 2018. We discuss the findings and learnings from these competitions and present an experimental evaluation of each module of our solution.