 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafe Exploration via Policy Priors
Jan 27, 2026Safe exploration is a key requirement for reinforcement learning (RL) agents to learn and adapt online, beyond controlled (e.g. simulated) environments. In this work, we tackle this challenge by utilizing suboptimal yet conservative policies (e.g., obtained from offline data or simulators) as priors. Our approach, SOOPER, uses probabilistic dynamics models to optimistically explore, yet pessimistically fall back to the conservative policy prior if needed. We prove that SOOPER guarantees safety throughout learning, and establish convergence to an optimal policy by bounding its cumulative regret. Extensive experiments on key safe RL benchmarks and real-world hardware demonstrate that SOOPER is scalable, outperforms the state-of-the-art and validate our theoretical guarantees in practice.
SonoGym: High Performance Simulation for Challenging Surgical Tasks with Robotic Ultrasound
Jul 01, 2025Ultrasound (US) is a widely used medical imaging modality due to its real-time capabilities, non-invasive nature, and cost-effectiveness. Robotic ultrasound can further enhance its utility by reducing operator dependence and improving access to complex anatomical regions. For this, while deep reinforcement learning (DRL) and imitation learning (IL) have shown potential for autonomous navigation, their use in complex surgical tasks such as anatomy reconstruction and surgical guidance remains limited -- largely due to the lack of realistic and efficient simulation environments tailored to these tasks. We introduce SonoGym, a scalable simulation platform for complex robotic ultrasound tasks that enables parallel simulation across tens to hundreds of environments. Our framework supports realistic and real-time simulation of US data from CT-derived 3D models of the anatomy through both a physics-based and a generative modeling approach. Sonogym enables the training of DRL and recent IL agents (vision transformers and diffusion policies) for relevant tasks in robotic orthopedic surgery by integrating common robotic platforms and orthopedic end effectors. We further incorporate submodular DRL -- a recent method that handles history-dependent rewards -- for anatomy reconstruction and safe reinforcement learning for surgery. Our results demonstrate successful policy learning across a range of scenarios, while also highlighting the limitations of current methods in clinically relevant environments. We believe our simulation can facilitate research in robot learning approaches for such challenging robotic surgery applications. Dataset, codes, and videos are publicly available at https://sonogym.github.io/.
Finite-Sample-Based Reachability for Safe Control with Gaussian Process Dynamics
May 12, 2025Gaussian Process (GP) regression is shown to be effective for learning unknown dynamics, enabling efficient and safety-aware control strategies across diverse applications. However, existing GP-based model predictive control (GP-MPC) methods either rely on approximations, thus lacking guarantees, or are overly conservative, which limits their practical utility. To close this gap, we present a sampling-based framework that efficiently propagates the model's epistemic uncertainty while avoiding conservatism. We establish a novel sample complexity result that enables the construction of a reachable set using a finite number of dynamics functions sampled from the GP posterior. Building on this, we design a sampling-based GP-MPC scheme that is recursively feasible and guarantees closed-loop safety and stability with high probability. Finally, we showcase the effectiveness of our method on two numerical examples, highlighting accurate reachable set over-approximation and safe closed-loop performance.
Performance-driven Constrained Optimal Auto-Tuner for MPC
Mar 10, 2025A key challenge in tuning Model Predictive Control (MPC) cost function parameters is to ensure that the system performance stays consistently above a certain threshold. To address this challenge, we propose a novel method, COAT-MPC, Constrained Optimal Auto-Tuner for MPC. With every tuning iteration, COAT-MPC gathers performance data and learns by updating its posterior belief. It explores the tuning parameters' domain towards optimistic parameters in a goal-directed fashion, which is key to its sample efficiency. We theoretically analyze COAT-MPC, showing that it satisfies performance constraints with arbitrarily high probability at all times and provably converges to the optimum performance within finite time. Through comprehensive simulations and comparative analyses with a hardware platform, we demonstrate the effectiveness of COAT-MPC in comparison to classical Bayesian Optimization (BO) and other state-of-the-art methods. When applied to autonomous racing, our approach outperforms baselines in terms of constraint violations and cumulative regret over time.
SMART: Self-learning Meta-strategy Agent for Reasoning Tasks
Oct 21, 2024



Tasks requiring deductive reasoning, especially those involving multiple steps, often demand adaptive strategies such as intermediate generation of rationales or programs, as no single approach is universally optimal. While Language Models (LMs) can enhance their outputs through iterative self-refinement and strategy adjustments, they frequently fail to apply the most effective strategy in their first attempt. This inefficiency raises the question: Can LMs learn to select the optimal strategy in the first attempt, without a need for refinement? To address this challenge, we introduce SMART (Self-learning Meta-strategy Agent for Reasoning Tasks), a novel framework that enables LMs to autonomously learn and select the most effective strategies for various reasoning tasks. We model the strategy selection process as a Markov Decision Process and leverage reinforcement learning-driven continuous self-improvement to allow the model to find the suitable strategy to solve a given task. Unlike traditional self-refinement methods that rely on multiple inference passes or external feedback, SMART allows an LM to internalize the outcomes of its own reasoning processes and adjust its strategy accordingly, aiming for correct solutions on the first attempt. Our experiments across various reasoning datasets and with different model architectures demonstrate that SMART significantly enhances the ability of models to choose optimal strategies without external guidance (+15 points on the GSM8K dataset). By achieving higher accuracy with a single inference pass, SMART not only improves performance but also reduces computational costs for refinement-based strategies, paving the way for more efficient and intelligent reasoning in LMs.
Towards safe and tractable Gaussian process-based MPC: Efficient sampling within a sequential quadratic programming framework
Sep 13, 2024Learning uncertain dynamics models using Gaussian process~(GP) regression has been demonstrated to enable high-performance and safety-aware control strategies for challenging real-world applications. Yet, for computational tractability, most approaches for Gaussian process-based model predictive control (GP-MPC) are based on approximations of the reachable set that are either overly conservative or impede the controller's safety guarantees. To address these challenges, we propose a robust GP-MPC formulation that guarantees constraint satisfaction with high probability. For its tractable implementation, we propose a sampling-based GP-MPC approach that iteratively generates consistent dynamics samples from the GP within a sequential quadratic programming framework. We highlight the improved reachable set approximation compared to existing methods, as well as real-time feasible computation times, using two numerical examples.
Global Reinforcement Learning: Beyond Linear and Convex Rewards via Submodular Semi-gradient Methods
Jul 13, 2024In classic Reinforcement Learning (RL), the agent maximizes an additive objective of the visited states, e.g., a value function. Unfortunately, objectives of this type cannot model many real-world applications such as experiment design, exploration, imitation learning, and risk-averse RL to name a few. This is due to the fact that additive objectives disregard interactions between states that are crucial for certain tasks. To tackle this problem, we introduce Global RL (GRL), where rewards are globally defined over trajectories instead of locally over states. Global rewards can capture negative interactions among states, e.g., in exploration, via submodularity, positive interactions, e.g., synergetic effects, via supermodularity, while mixed interactions via combinations of them. By exploiting ideas from submodular optimization, we propose a novel algorithmic scheme that converts any GRL problem to a sequence of classic RL problems and solves it efficiently with curvature-dependent approximation guarantees. We also provide hardness of approximation results and empirically demonstrate the effectiveness of our method on several GRL instances.
Safe Guaranteed Exploration for Non-linear Systems
Feb 09, 2024


Safely exploring environments with a-priori unknown constraints is a fundamental challenge that restricts the autonomy of robots. While safety is paramount, guarantees on sufficient exploration are also crucial for ensuring autonomous task completion. To address these challenges, we propose a novel safe guaranteed exploration framework using optimal control, which achieves first-of-its-kind results: guaranteed exploration for non-linear systems with finite time sample complexity bounds, while being provably safe with arbitrarily high probability. The framework is general and applicable to many real-world scenarios with complex non-linear dynamics and unknown domains. Based on this framework we propose an efficient algorithm, SageMPC, SAfe Guaranteed Exploration using Model Predictive Control. SageMPC improves efficiency by incorporating three techniques: i) exploiting a Lipschitz bound, ii) goal-directed exploration, and iii) receding horizon style re-planning, all while maintaining the desired sample complexity, safety and exploration guarantees of the framework. Lastly, we demonstrate safe efficient exploration in challenging unknown environments using SageMPC with a car model.
Submodular Reinforcement Learning
Jul 25, 2023



In reinforcement learning (RL), rewards of states are typically considered additive, and following the Markov assumption, they are $\textit{independent}$ of states visited previously. In many important applications, such as coverage control, experiment design and informative path planning, rewards naturally have diminishing returns, i.e., their value decreases in light of similar states visited previously. To tackle this, we propose $\textit{submodular RL}$ (SubRL), a paradigm which seeks to optimize more general, non-additive (and history-dependent) rewards modelled via submodular set functions which capture diminishing returns. Unfortunately, in general, even in tabular settings, we show that the resulting optimization problem is hard to approximate. On the other hand, motivated by the success of greedy algorithms in classical submodular optimization, we propose SubPO, a simple policy gradient-based algorithm for SubRL that handles non-additive rewards by greedily maximizing marginal gains. Indeed, under some assumptions on the underlying Markov Decision Process (MDP), SubPO recovers optimal constant factor approximations of submodular bandits. Moreover, we derive a natural policy gradient approach for locally optimizing SubRL instances even in large state- and action- spaces. We showcase the versatility of our approach by applying SubPO to several applications, such as biodiversity monitoring, Bayesian experiment design, informative path planning, and coverage maximization. Our results demonstrate sample efficiency, as well as scalability to high-dimensional state-action spaces.
Near-Optimal Multi-Agent Learning for Safe Coverage Control
Oct 12, 2022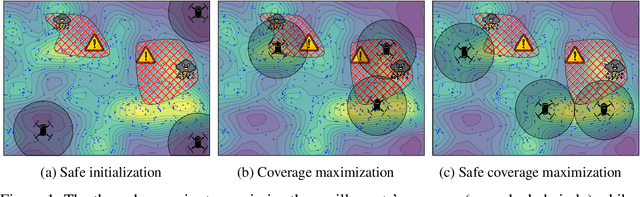
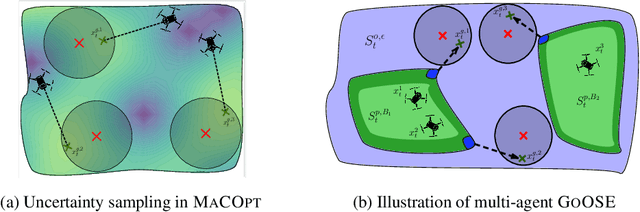
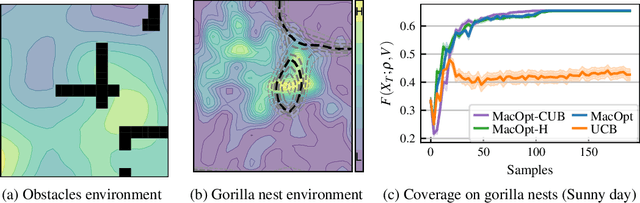
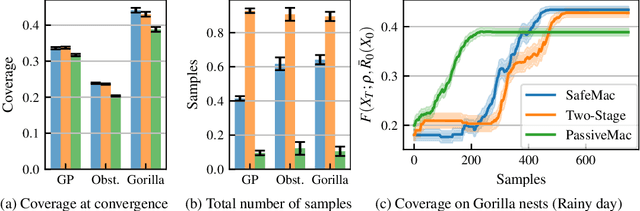
In multi-agent coverage control problems, agents navigate their environment to reach locations that maximize the coverage of some density. In practice, the density is rarely known $\textit{a priori}$, further complicating the original NP-hard problem. Moreover, in many applications, agents cannot visit arbitrary locations due to $\textit{a priori}$ unknown safety constraints. In this paper, we aim to efficiently learn the density to approximately solve the coverage problem while preserving the agents' safety. We first propose a conditionally linear submodular coverage function that facilitates theoretical analysis. Utilizing this structure, we develop MacOpt, a novel algorithm that efficiently trades off the exploration-exploitation dilemma due to partial observability, and show that it achieves sublinear regret. Next, we extend results on single-agent safe exploration to our multi-agent setting and propose SafeMac for safe coverage and exploration. We analyze SafeMac and give first of its kind results: near optimal coverage in finite time while provably guaranteeing safety. We extensively evaluate our algorithms on synthetic and real problems, including a bio-diversity monitoring task under safety constraints, where SafeMac outperforms competing methods.