 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Domain Adaptation for LiDAR Panoptic Segmentation
Sep 30, 2021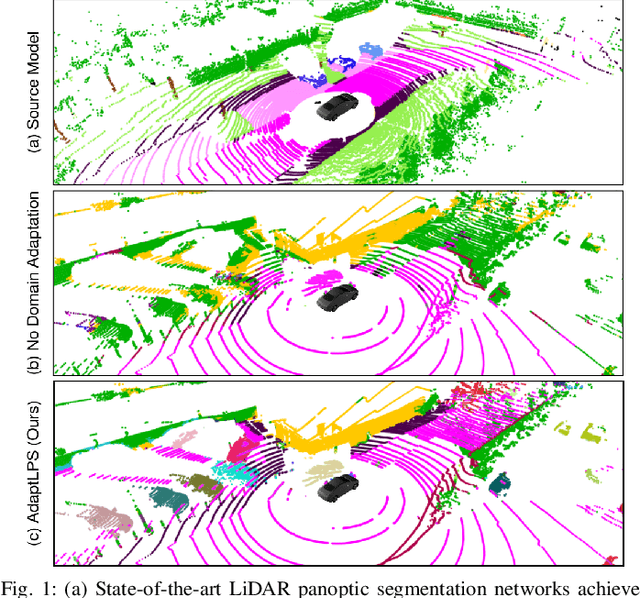
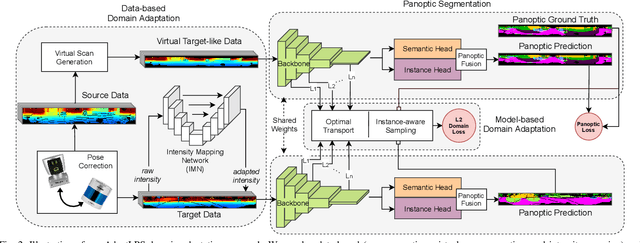
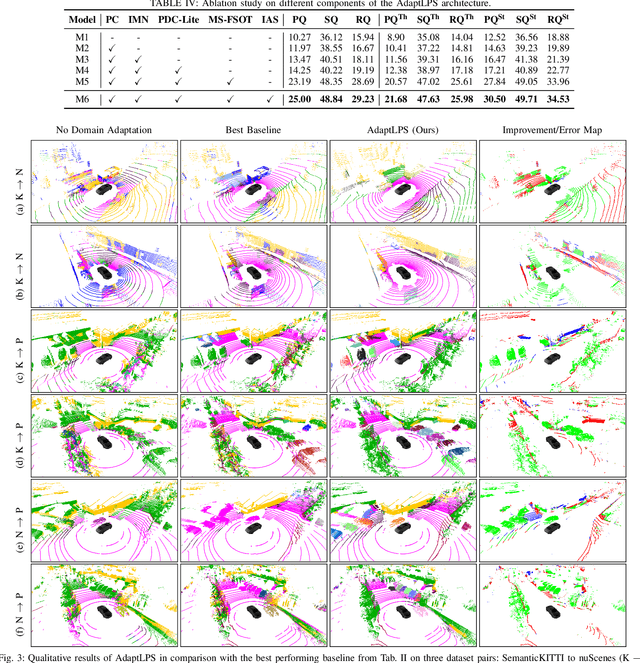
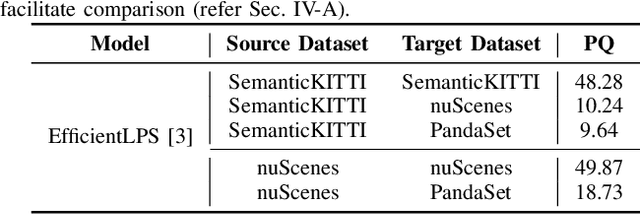
Scene understanding is a pivotal task for autonomous vehicles to safely navigate in the environment. Recent advances in deep learning enable accurate semantic reconstruction of the surroundings from LiDAR data. However, these models encounter a large domain gap while deploying them on vehicles equipped with different LiDAR setups which drastically decreases their performance. Fine-tuning the model for every new setup is infeasible due to the expensive and cumbersome process of recording and manually labeling new data. Unsupervised Domain Adaptation (UDA) techniques are thus essential to fill this domain gap and retain the performance of models on new sensor setups without the need for additional data labeling. In this paper, we propose AdaptLPS, a novel UDA approach for LiDAR panoptic segmentation that leverages task-specific knowledge and accounts for variation in the number of scan lines, mounting position, intensity distribution, and environmental conditions. We tackle the UDA task by employing two complementary domain adaptation strategies, data-based and model-based. While data-based adaptations reduce the domain gap by processing the raw LiDAR scans to resemble the scans in the target domain, model-based techniques guide the network in extracting features that are representative for both domains. Extensive evaluations on three pairs of real-world autonomous driving datasets demonstrate that AdaptLPS outperforms existing UDA approaches by up to 6.41 pp in terms of the PQ score.
Dynamic Object Removal and Spatio-Temporal RGB-D Inpainting via Geometry-Aware Adversarial Learning
Aug 12, 2020
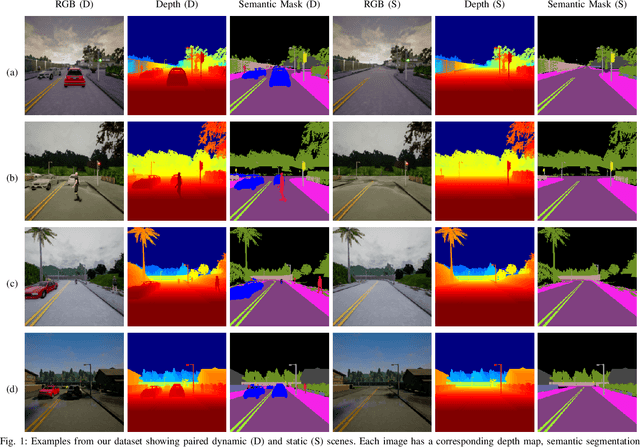
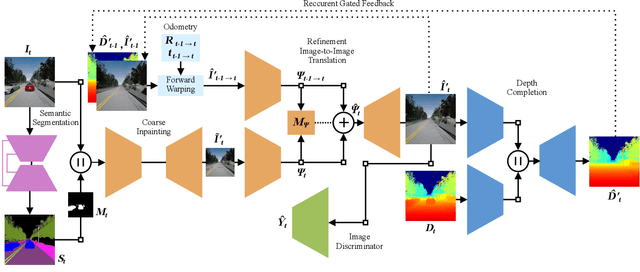
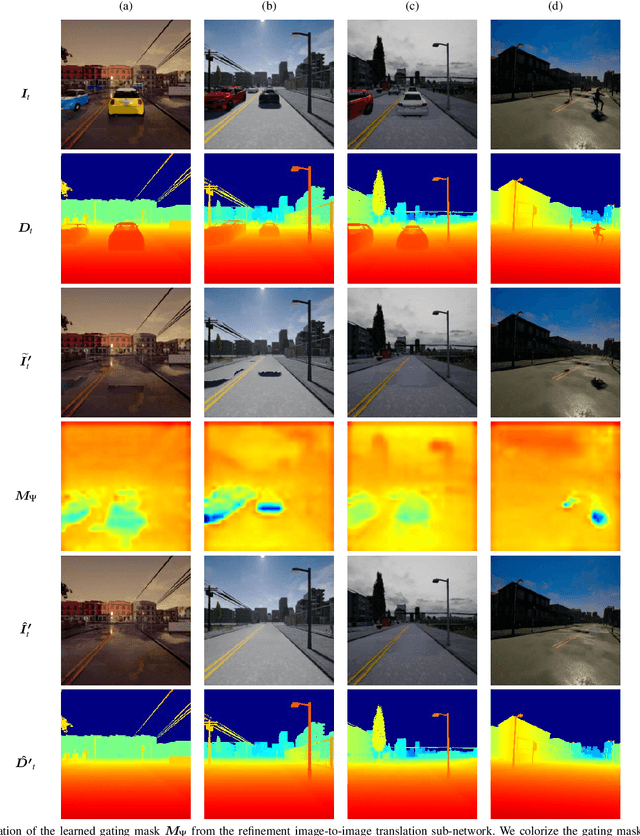
Dynamic objects have a significant impact on the robot's perception of the environment which degrades the performance of essential tasks such as localization and mapping. In this work, we address this problem by synthesizing plausible color, texture and geometry in regions occluded by dynamic objects. We propose the novel geometry-aware DynaFill architecture that follows a coarse-to-fine topology and incorporates our gated recurrent feedback mechanism to adaptively fuse information from previous timesteps. We optimize our architecture using adversarial training to synthesize fine realistic textures which enables it to hallucinate color and depth structure in occluded regions online in a spatially and temporally coherent manner, without relying on future frame information. Casting our inpainting problem as an image-to-image translation task, our model also corrects regions correlated with the presence of dynamic objects in the scene, such as shadows or reflections. We introduce a large-scale hyperrealistic dataset with RGB-D images, semantic segmentation labels, camera poses as well as ground truth RGB-D information of occluded regions. Extensive quantitative and qualitative evaluations show that our approach achieves state-of-the-art performance, even in challenging weather conditions. Furthermore, we present results for retrieval-based visual localization with the synthesized images that demonstrate the utility of our approach.