 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement Learning for Control Systems with Time Delays: A Comprehensive Survey
Jan 30, 2026In the last decade, Reinforcement Learning (RL) has achieved remarkable success in the control and decision-making of complex dynamical systems. However, most RL algorithms rely on the Markov Decision Process assumption, which is violated in practical cyber-physical systems affected by sensing delays, actuation latencies, and communication constraints. Such time delays introduce memory effects that can significantly degrade performance and compromise stability, particularly in networked and multi-agent environments. This paper presents a comprehensive survey of RL methods designed to address time delays in control systems. We first formalize the main classes of delays and analyze their impact on the Markov property. We then systematically categorize existing approaches into five major families: state augmentation and history-based representations, recurrent policies with learned memory, predictor-based and model-aware methods, robust and domain-randomized training strategies, and safe RL frameworks with explicit constraint handling. For each family, we discuss underlying principles, practical advantages, and inherent limitations. A comparative analysis highlights key trade-offs among these approaches and provides practical guidelines for selecting suitable methods under different delay characteristics and safety requirements. Finally, we identify open challenges and promising research directions, including stability certification, large-delay learning, multi-agent communication co-design, and standardized benchmarking. This survey aims to serve as a unified reference for researchers and practitioners developing reliable RL-based controllers in delay-affected cyber-physical systems.
Robust Longitudinal Control for Vehicular Autonomous Platoons Using Deep Reinforcement Learning
May 31, 2022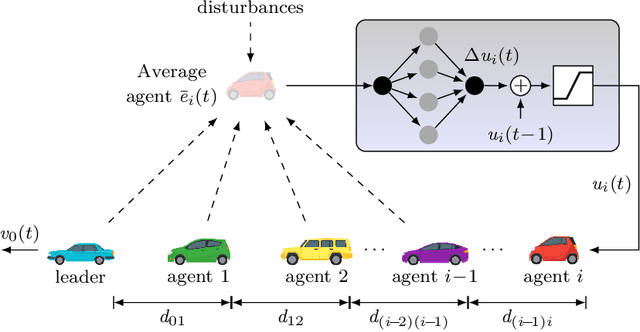
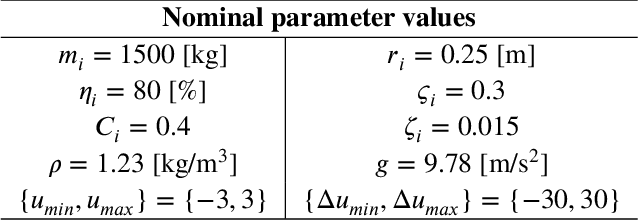
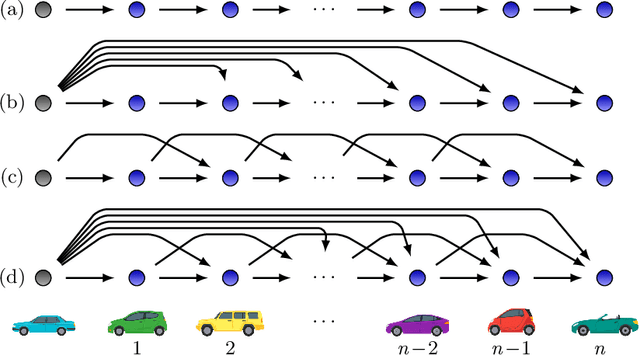
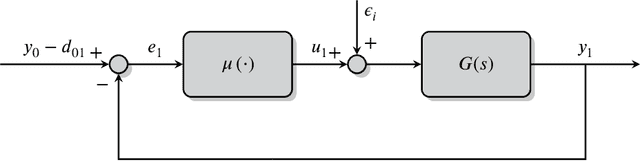
In the last few years, researchers have applied machine learning strategies in the context of vehicular platoons to increase the safety and efficiency of cooperative transportation. Reinforcement Learning methods have been employed in the longitudinal spacing control of Cooperative Adaptive Cruise Control systems, but to date, none of those studies have addressed problems of disturbance rejection in such scenarios. Characteristics such as uncertain parameters in the model and external interferences may prevent agents from reaching null-spacing errors when traveling at cruising speed. On the other hand, complex communication topologies lead to specific training processes that can not be generalized to other contexts, demanding re-training every time the configuration changes. Therefore, in this paper, we propose an approach to generalize the training process of a vehicular platoon, such that the acceleration command of each agent becomes independent of the network topology. Also, we have modeled the acceleration input as a term with integral action, such that the Convolutional Neural Network is capable of learning corrective actions when the states are disturbed by unknown effects. We illustrate the effectiveness of our proposal with experiments using different network topologies, uncertain parameters, and external forces. Comparative analyses, in terms of the steady-state error and overshoot response, were conducted against the state-of-the-art literature. The findings offer new insights concerning generalization and robustness of using Reinforcement Learning in the control of autonomous platoons.
Trajectory Planning for Hybrid Unmanned Aerial Underwater Vehicles with Smooth Media Transition
Dec 27, 2021



In the last decade, a great effort has been employed in the study of Hybrid Unmanned Aerial Underwater Vehicles, robots that can easily fly and dive into the water with different levels of mechanical adaptation. However, most of this literature is concentrated on physical design, practical issues of construction, and, more recently, low-level control strategies. Little has been done in the context of high-level intelligence, such as motion planning and interactions with the real world. Therefore, we proposed in this paper a trajectory planning approach that allows collision avoidance against unknown obstacles and smooth transitions between aerial and aquatic media. Our method is based on a variant of the classic Rapidly-exploring Random Tree, whose main advantages are the capability to deal with obstacles, complex nonlinear dynamics, model uncertainties, and external disturbances. The approach uses the dynamic model of the \hydrone, a hybrid vehicle proposed with high underwater performance, but we believe it can be easily generalized to other types of aerial/aquatic platforms. In the experimental section, we present simulated results in environments filled with obstacles, where the robot is commanded to perform different media movements, demonstrating the applicability of our strategy.
A Semi-Lagrangian Approach for the Minimal Exposure Path Problem in Wireless Sensor Networks
Aug 12, 2021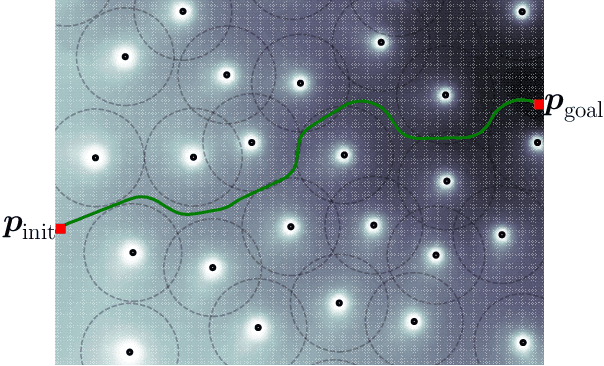
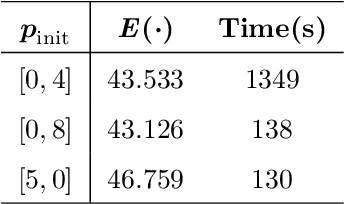

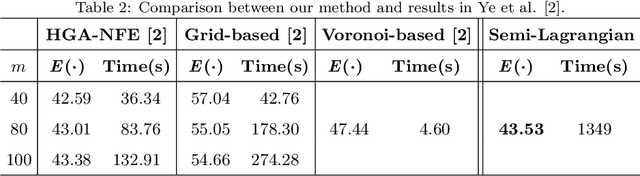
A critical metric of the coverage quality in Wireless Sensor Networks (WSNs) is the Minimal Exposure Path (MEP), a path through the environment that least exposes an intruder to the sensor detecting nodes. Many approaches have been proposed in the last decades to solve this optimization problem, ranging from classic (grid-based and Voronoi-based) planners to genetic meta-heuristics. However, most of them are limited to specific sensing models and obstacle-free spaces. Still, none of them guarantee an optimal solution, and the state-of-the-art is expensive in terms of run-time. Therefore, in this paper, we propose a novel method that models the MEP as an Optimal Control problem and solves it by using a Semi-Lagrangian approach. This framework is shown to converge to the optimal MEP while also incorporates different homogeneous and heterogeneous sensor models and geometric constraints (obstacles). Experiments show that our method dominates the state-of-the-art, improving the results by approximately 10% with a relatively lower execution time.
Deep Reinforcement Learning for Mapless Navigation of a Hybrid Aerial Underwater Vehicle with Medium Transition
Mar 28, 2021

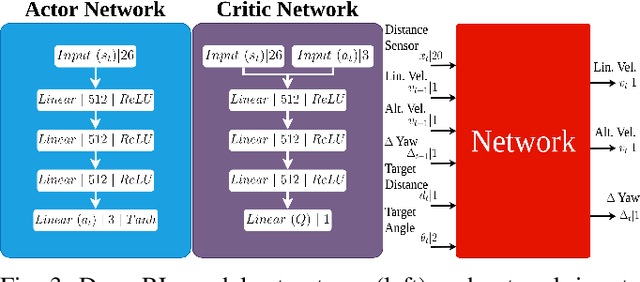
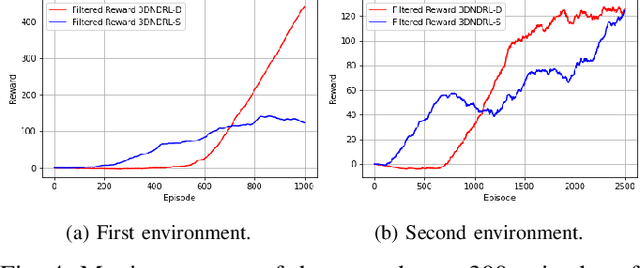
Since the application of Deep Q-Learning to the continuous action domain in Atari-like games, Deep Reinforcement Learning (Deep-RL) techniques for motion control have been qualitatively enhanced. Nowadays, modern Deep-RL can be successfully applied to solve a wide range of complex decision-making tasks for many types of vehicles. Based on this context, in this paper, we propose the use of Deep-RL to perform autonomous mapless navigation for Hybrid Unmanned Aerial Underwater Vehicles (HUAUVs), robots that can operate in both, air or water media. We developed two approaches, one deterministic and the other stochastic. Our system uses the relative localization of the vehicle and simple sparse range data to train the network. We compared our approaches with a traditional geometric tracking controller for mapless navigation. Based on experimental results, we can conclude that Deep-RL-based approaches can be successfully used to perform mapless navigation and obstacle avoidance for HUAUVs. Our vehicle accomplished the navigation in two scenarios, being capable to achieve the desired target through both environments, and even outperforming the geometric-based tracking controller on the obstacle-avoidance capability.
Minimal Exposure Dubins Orienteering Problem
Oct 22, 2020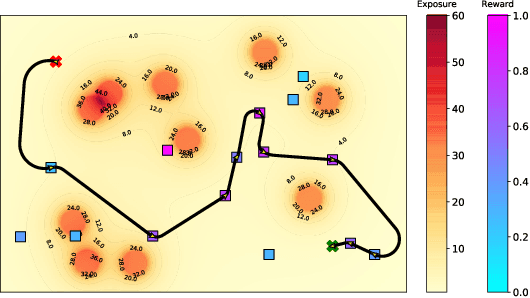
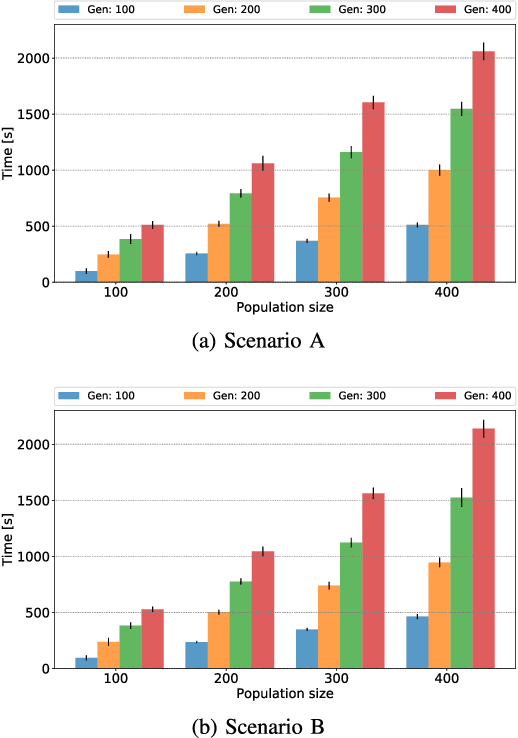
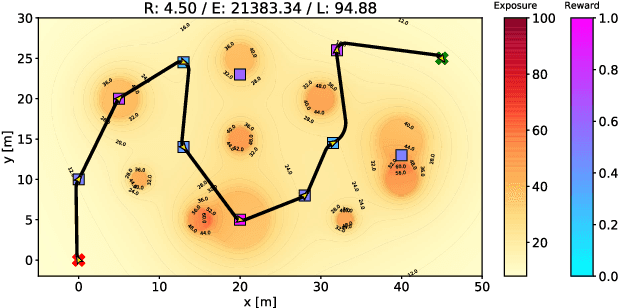
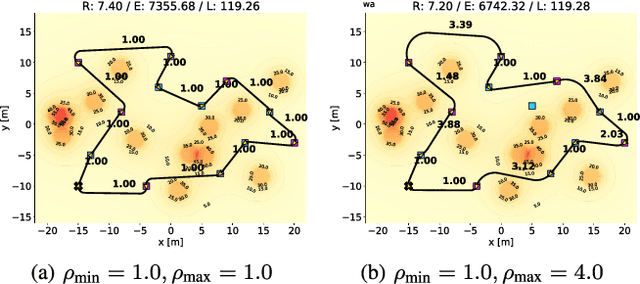
Different applications, such as environmental monitoring and military operations, demand the observation of predefined target locations, and an autonomous mobile robot can assist in these tasks. In this context, the Orienteering Problem (OP) is a well-known routing problem, in which the goal is to maximize the objective function by visiting the most rewarding locations, however, respecting a limited travel budget (e.g., length, time, energy). However, traditional formulations for routing problems generally neglect some environment peculiarities, such as obstacles or threatening zones. In this paper, we tackle the OP considering Dubins vehicles in the presence of a known deployed sensor field. We propose a novel multi-objective formulation called Minimal Exposure Dubins Orienteering Problem (MEDOP), whose main objectives are: (i) maximize the collected reward, and (ii) minimize the exposure of the agent, i.e., the probability of being detected. The solution is based on an evolutionary algorithm that iteratively varies the subset and sequence of locations to be visited, the orientations on each location, and the turning radius used to determine the paths. Results show that our approach can efficiently find a diverse set of solutions that simultaneously optimize both objectives.