 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExpert Composer Policy: Scalable Skill Repertoire for Quadruped Robots
Paper and Code
Mar 18, 2024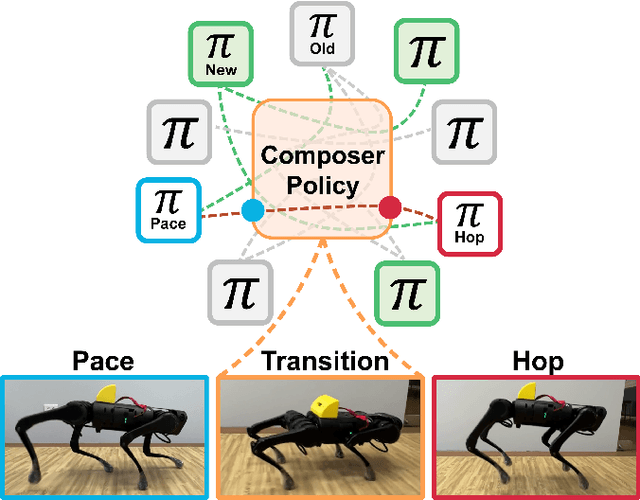
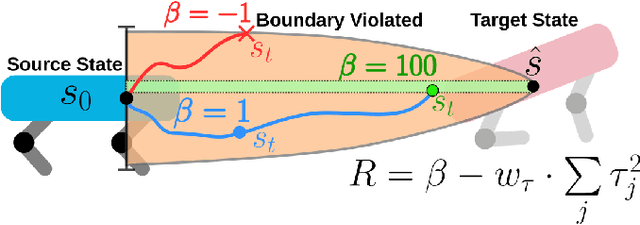

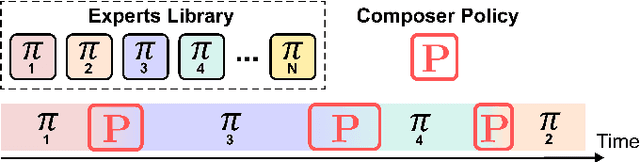
We propose the expert composer policy, a framework to reliably expand the skill repertoire of quadruped agents. The composer policy links pair of experts via transitions to a sampled target state, allowing experts to be composed sequentially. Each expert specializes in a single skill, such as a locomotion gait or a jumping motion. Instead of a hierarchical or mixture-of-experts architecture, we train a single composer policy in an independent process that is not conditioned on the other expert policies. By reusing the same composer policy, our approach enables adding new experts without affecting existing ones, enabling incremental repertoire expansion and preserving original motion quality. We measured the transition success rate of 72 transition pairs and achieved an average success rate of 99.99\%, which is over 10\% higher than the baseline random approach, and outperforms other state-of-the-art methods. Using domain randomization during training we ensure a successful transfer to the real world, where we achieve an average transition success rate of 97.22\% (N=360) in our experiments.