 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeasibility-Guided Planning over Multi-Specialized Locomotion Policies
Feb 08, 2026Planning over unstructured terrain presents a significant challenge in the field of legged robotics. Although recent works in reinforcement learning have yielded various locomotion strategies, planning over multiple experts remains a complex issue. Existing approaches encounter several constraints: traditional planners are unable to integrate skill-specific policies, whereas hierarchical learning frameworks often lose interpretability and require retraining whenever new policies are added. In this paper, we propose a feasibility-guided planning framework that successfully incorporates multiple terrain-specific policies. Each policy is paired with a Feasibility-Net, which learned to predict feasibility tensors based on the local elevation maps and task vectors. This integration allows classical planning algorithms to derive optimal paths. Through both simulated and real-world experiments, we demonstrate that our method efficiently generates reliable plans across diverse and challenging terrains, while consistently aligning with the capabilities of the underlying policies.
Benchmarking Smoothness and Reducing High-Frequency Oscillations in Continuous Control Policies
Oct 22, 2024
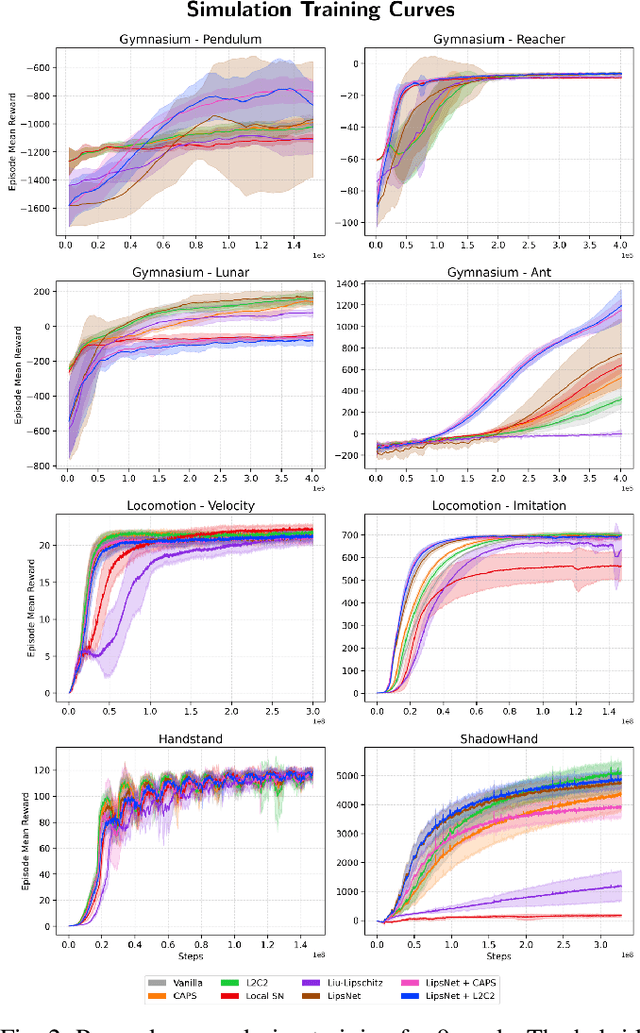
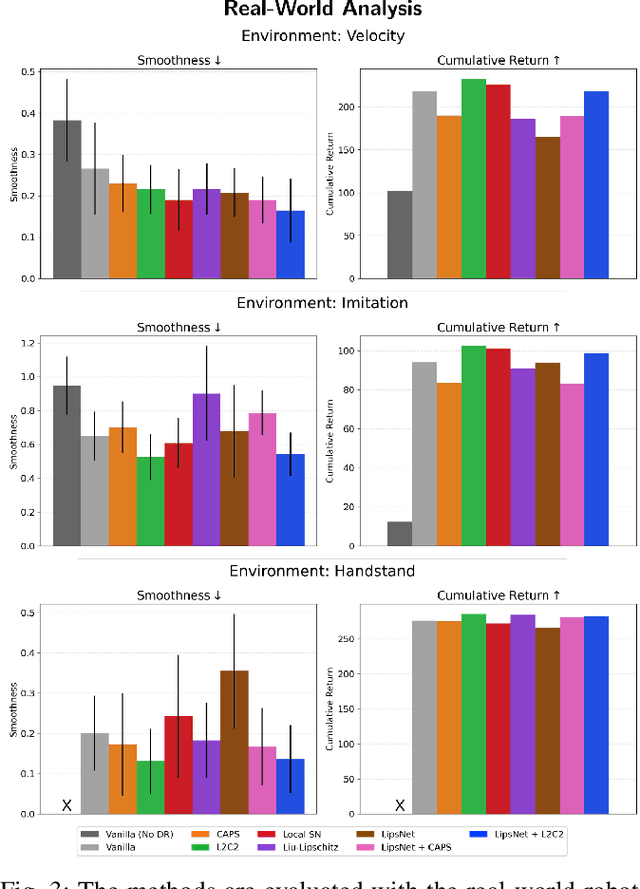
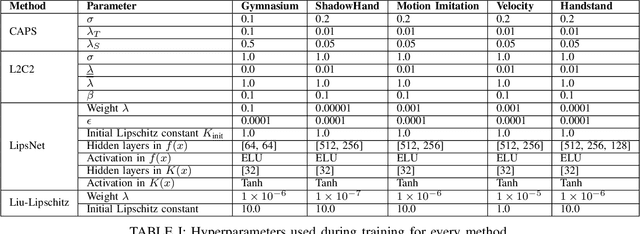
Reinforcement learning (RL) policies are prone to high-frequency oscillations, especially undesirable when deploying to hardware in the real-world. In this paper, we identify, categorize, and compare methods from the literature that aim to mitigate high-frequency oscillations in deep RL. We define two broad classes: loss regularization and architectural methods. At their core, these methods incentivize learning a smooth mapping, such that nearby states in the input space produce nearby actions in the output space. We present benchmarks in terms of policy performance and control smoothness on traditional RL environments from the Gymnasium and a complex manipulation task, as well as three robotics locomotion tasks that include deployment and evaluation with real-world hardware. Finally, we also propose hybrid methods that combine elements from both loss regularization and architectural methods. We find that the best-performing hybrid outperforms other methods, and improves control smoothness by 26.8% over the baseline, with a worst-case performance degradation of just 2.8%.
Expert Composer Policy: Scalable Skill Repertoire for Quadruped Robots
Mar 18, 2024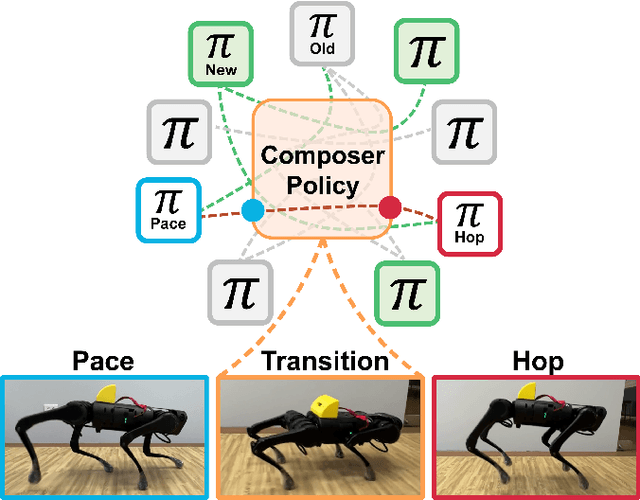
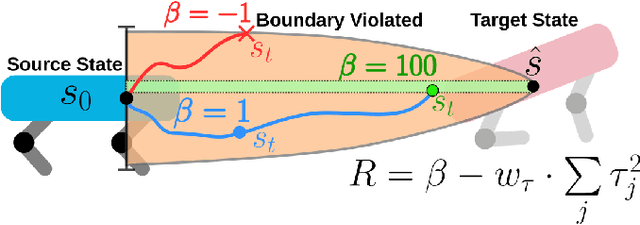

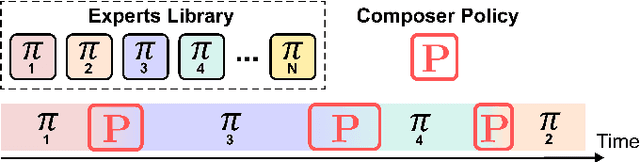
We propose the expert composer policy, a framework to reliably expand the skill repertoire of quadruped agents. The composer policy links pair of experts via transitions to a sampled target state, allowing experts to be composed sequentially. Each expert specializes in a single skill, such as a locomotion gait or a jumping motion. Instead of a hierarchical or mixture-of-experts architecture, we train a single composer policy in an independent process that is not conditioned on the other expert policies. By reusing the same composer policy, our approach enables adding new experts without affecting existing ones, enabling incremental repertoire expansion and preserving original motion quality. We measured the transition success rate of 72 transition pairs and achieved an average success rate of 99.99\%, which is over 10\% higher than the baseline random approach, and outperforms other state-of-the-art methods. Using domain randomization during training we ensure a successful transfer to the real world, where we achieve an average transition success rate of 97.22\% (N=360) in our experiments.
Expanding Versatility of Agile Locomotion through Policy Transitions Using Latent State Representation
Jun 14, 2023
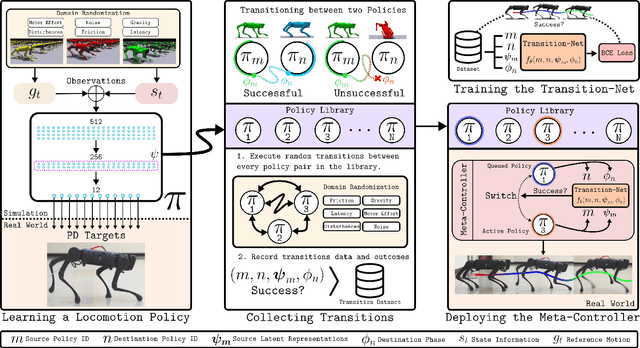
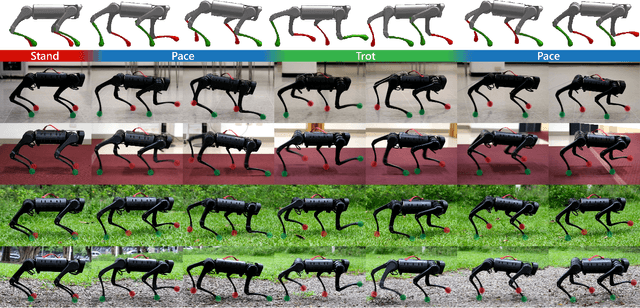
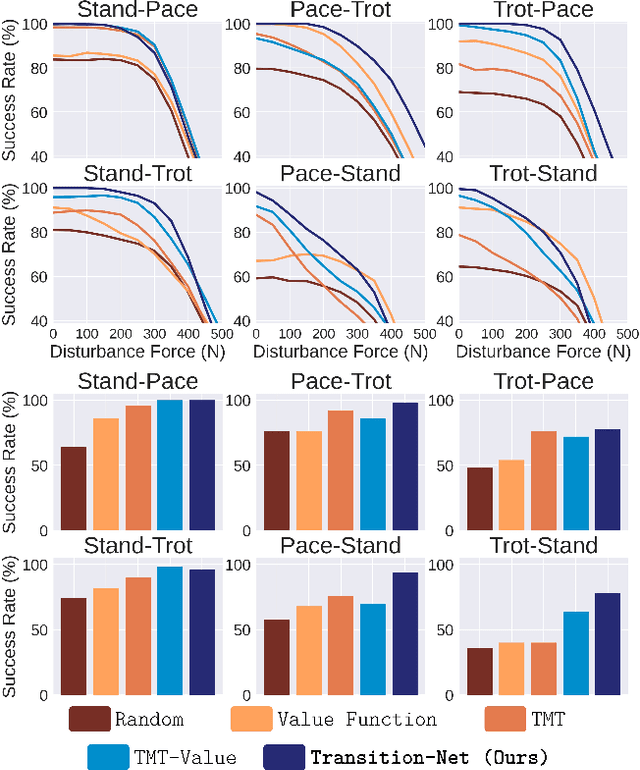
This paper proposes the transition-net, a robust transition strategy that expands the versatility of robot locomotion in the real-world setting. To this end, we start by distributing the complexity of different gaits into dedicated locomotion policies applicable to real-world robots. Next, we expand the versatility of the robot by unifying the policies with robust transitions into a single coherent meta-controller by examining the latent state representations. Our approach enables the robot to iteratively expand its skill repertoire and robustly transition between any policy pair in a library. In our framework, adding new skills does not introduce any process that alters the previously learned skills. Moreover, training of a locomotion policy takes less than an hour with a single consumer GPU. Our approach is effective in the real-world and achieves a 19% higher average success rate for the most challenging transition pairs in our experiments compared to existing approaches.
Development of a deep learning-based tool to assist wound classification
Mar 29, 2023



This paper presents a deep learning-based wound classification tool that can assist medical personnel in non-wound care specialization to classify five key wound conditions, namely deep wound, infected wound, arterial wound, venous wound, and pressure wound, given color images captured using readily available cameras. The accuracy of the classification is vital for appropriate wound management. The proposed wound classification method adopts a multi-task deep learning framework that leverages the relationships among the five key wound conditions for a unified wound classification architecture. With differences in Cohen's kappa coefficients as the metrics to compare our proposed model with humans, the performance of our model was better or non-inferior to those of all human medical personnel. Our convolutional neural network-based model is the first to classify five tasks of deep, infected, arterial, venous, and pressure wounds simultaneously with good accuracy. The proposed model is compact and matches or exceeds the performance of human doctors and nurses. Medical personnel who do not specialize in wound care can potentially benefit from an app equipped with the proposed deep learning model.
Transition Motion Tensor: A Data-Driven Approach for Versatile and Controllable Agents in Physically Simulated Environments
Nov 30, 2021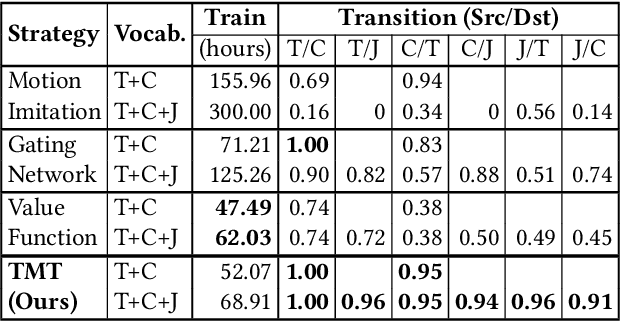
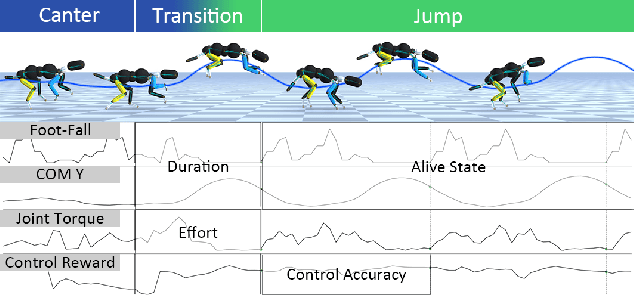
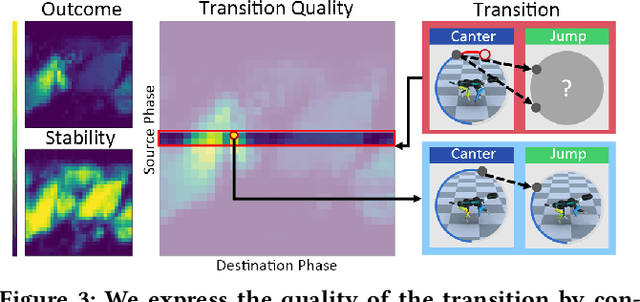
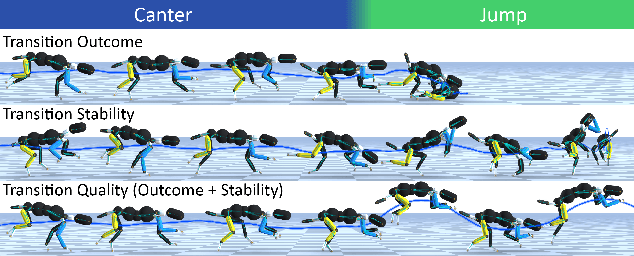
This paper proposes the Transition Motion Tensor, a data-driven framework that creates novel and physically accurate transitions outside of the motion dataset. It enables simulated characters to adopt new motion skills efficiently and robustly without modifying existing ones. Given several physically simulated controllers specializing in different motions, the tensor serves as a temporal guideline to transition between them. Through querying the tensor for transitions that best fit user-defined preferences, we can create a unified controller capable of producing novel transitions and solving complex tasks that may require multiple motions to work coherently. We apply our framework on both quadrupeds and bipeds, perform quantitative and qualitative evaluations on transition quality, and demonstrate its capability of tackling complex motion planning problems while following user control directives.
CARL: Controllable Agent with Reinforcement Learning for Quadruped Locomotion
May 11, 2020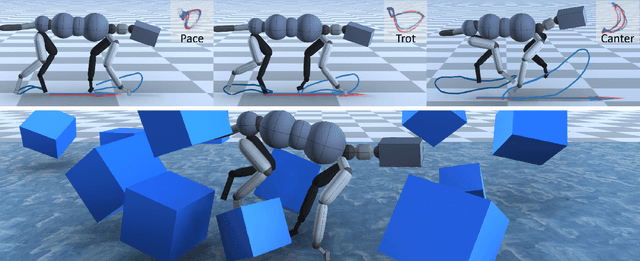
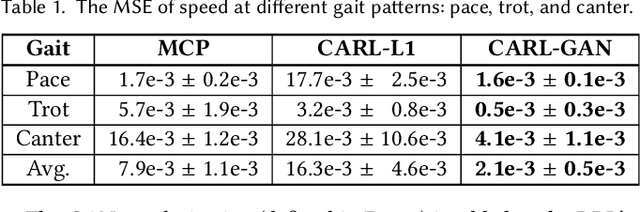
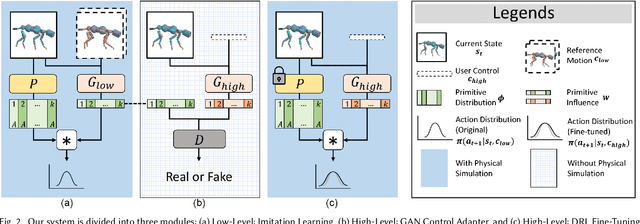
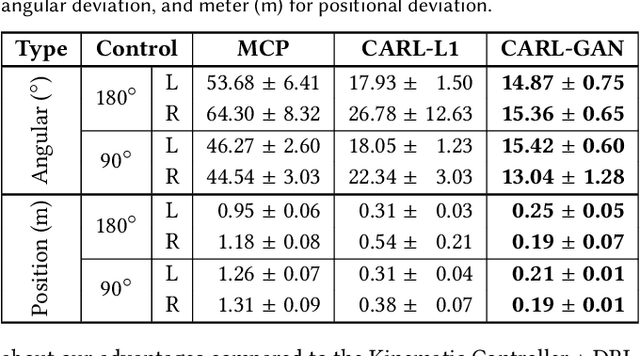
Motion synthesis in a dynamic environment has been a long-standing problem for character animation. Methods using motion capture data tend to scale poorly in complex environments because of their larger capturing and labeling requirement. Physics-based controllers are effective in this regard, albeit less controllable. In this paper, we present CARL, a quadruped agent that can be controlled with high-level directives and react naturally to dynamic environments. Starting with an agent that can imitate individual animation clips, we use Generative Adversarial Networks to adapt high-level controls, such as speed and heading, to action distributions that correspond to the original animations. Further fine-tuning through the deep reinforcement learning enables the agent to recover from unseen external perturbations while producing smooth transitions. It then becomes straightforward to create autonomous agents in dynamic environments by adding navigation modules over the entire process. We evaluate our approach by measuring the agent's ability to follow user control and provide a visual analysis of the generated motion to show its effectiveness.