 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeII-NVM: Enhancing Map Accuracy and Consistency with Normal Vector-Assisted Mapping
Apr 11, 2025SLAM technology plays a crucial role in indoor mapping and localization. A common challenge in indoor environments is the "double-sided mapping issue", where closely positioned walls, doors, and other surfaces are mistakenly identified as a single plane, significantly hindering map accuracy and consistency. To address this issue this paper introduces a SLAM approach that ensures accurate mapping using normal vector consistency. We enhance the voxel map structure to store both point cloud data and normal vector information, enabling the system to evaluate consistency during nearest neighbor searches and map updates. This process distinguishes between the front and back sides of surfaces, preventing incorrect point-to-plane constraints. Moreover, we implement an adaptive radius KD-tree search method that dynamically adjusts the search radius based on the local density of the point cloud, thereby enhancing the accuracy of normal vector calculations. To further improve realtime performance and storage efficiency, we incorporate a Least Recently Used (LRU) cache strategy, which facilitates efficient incremental updates of the voxel map. The code is released as open-source and validated in both simulated environments and real indoor scenarios. Experimental results demonstrate that this approach effectively resolves the "double-sided mapping issue" and significantly improves mapping precision. Additionally, we have developed and open-sourced the first simulation and real world dataset specifically tailored for the "double-sided mapping issue".
Decremental Dynamics Planning for Robot Navigation
Mar 26, 2025



Most, if not all, robot navigation systems employ a decomposed planning framework that includes global and local planning. To trade-off onboard computation and plan quality, current systems have to limit all robot dynamics considerations only within the local planner, while leveraging an extremely simplified robot representation (e.g., a point-mass holonomic model without dynamics) in the global level. However, such an artificial decomposition based on either full or zero consideration of robot dynamics can lead to gaps between the two levels, e.g., a global path based on a holonomic point-mass model may not be realizable by a non-holonomic robot, especially in highly constrained obstacle environments. Motivated by such a limitation, we propose a novel paradigm, Decremental Dynamics Planning that integrates dynamic constraints into the entire planning process, with a focus on high-fidelity dynamics modeling at the beginning and a gradual fidelity reduction as the planning progresses. To validate the effectiveness of this paradigm, we augment three different planners with DDP and show overall improved planning performance. We also develop a new DDP-based navigation system, which achieves first place in the simulation phase of the 2025 BARN Challenge. Both simulated and physical experiments validate DDP's hypothesized benefits.
Reward Training Wheels: Adaptive Auxiliary Rewards for Robotics Reinforcement Learning
Mar 19, 2025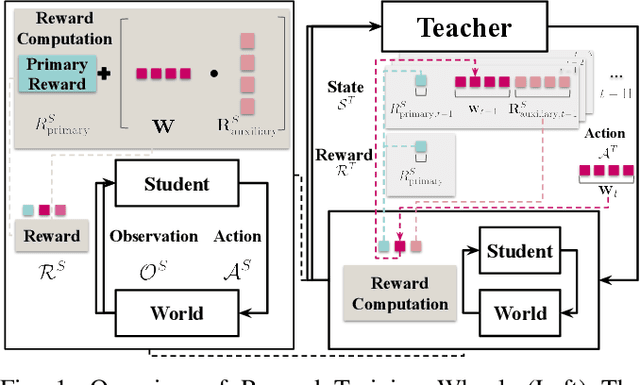
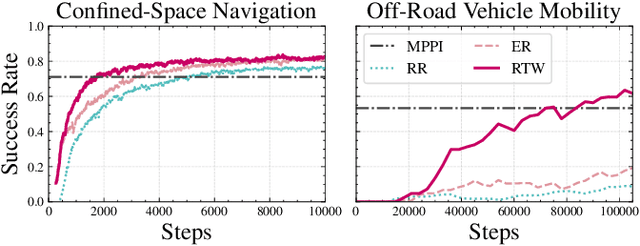

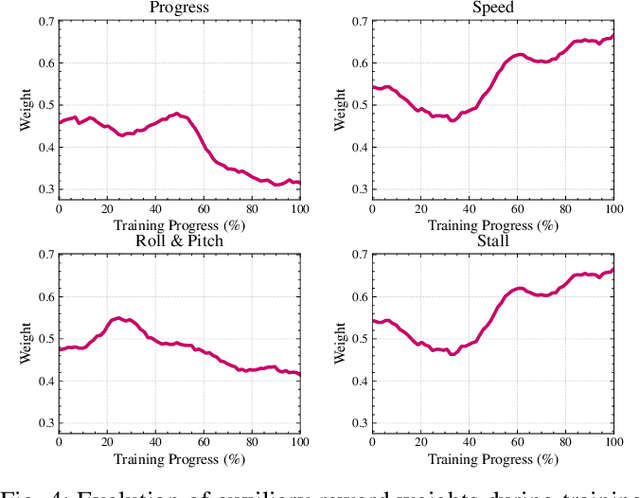
Robotics Reinforcement Learning (RL) often relies on carefully engineered auxiliary rewards to supplement sparse primary learning objectives to compensate for the lack of large-scale, real-world, trial-and-error data. While these auxiliary rewards accelerate learning, they require significant engineering effort, may introduce human biases, and cannot adapt to the robot's evolving capabilities during training. In this paper, we introduce Reward Training Wheels (RTW), a teacher-student framework that automates auxiliary reward adaptation for robotics RL. To be specific, the RTW teacher dynamically adjusts auxiliary reward weights based on the student's evolving capabilities to determine which auxiliary reward aspects require more or less emphasis to improve the primary objective. We demonstrate RTW on two challenging robot tasks: navigation in highly constrained spaces and off-road vehicle mobility on vertically challenging terrain. In simulation, RTW outperforms expert-designed rewards by 2.35% in navigation success rate and improves off-road mobility performance by 122.62%, while achieving 35% and 3X faster training efficiency, respectively. Physical robot experiments further validate RTW's effectiveness, achieving a perfect success rate (5/5 trials vs. 2/5 for expert-designed rewards) and improving vehicle stability with up to 47.4% reduction in orientation angles.
Grounded Curriculum Learning
Sep 29, 2024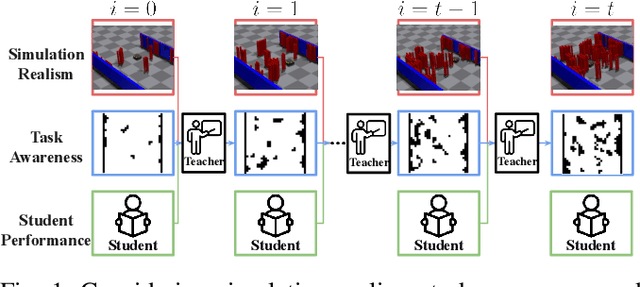
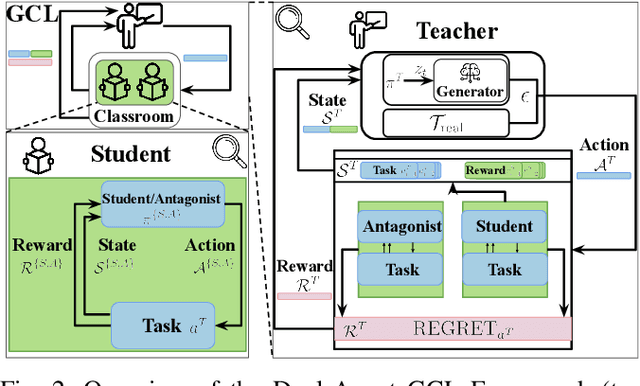
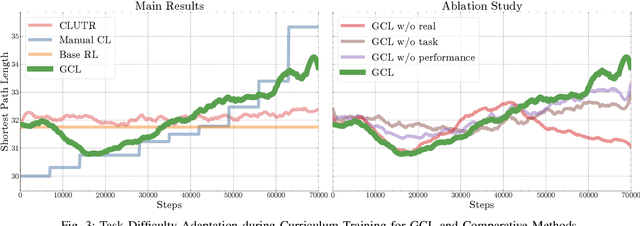
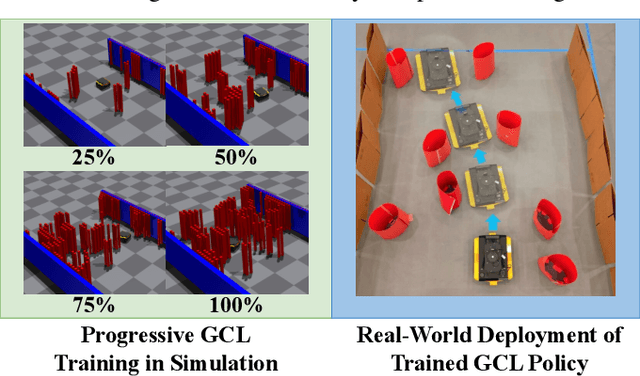
The high cost of real-world data for robotics Reinforcement Learning (RL) leads to the wide usage of simulators. Despite extensive work on building better dynamics models for simulators to match with the real world, there is another, often-overlooked mismatch between simulations and the real world, namely the distribution of available training tasks. Such a mismatch is further exacerbated by existing curriculum learning techniques, which automatically vary the simulation task distribution without considering its relevance to the real world. Considering these challenges, we posit that curriculum learning for robotics RL needs to be grounded in real-world task distributions. To this end, we propose Grounded Curriculum Learning (GCL), which aligns the simulated task distribution in the curriculum with the real world, as well as explicitly considers what tasks have been given to the robot and how the robot has performed in the past. We validate GCL using the BARN dataset on complex navigation tasks, achieving a 6.8% and 6.5% higher success rate compared to a state-of-the-art CL method and a curriculum designed by human experts, respectively. These results show that GCL can enhance learning efficiency and navigation performance by grounding the simulation task distribution in the real world within an adaptive curriculum.