 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReward Training Wheels: Adaptive Auxiliary Rewards for Robotics Reinforcement Learning
Paper and Code
Mar 19, 2025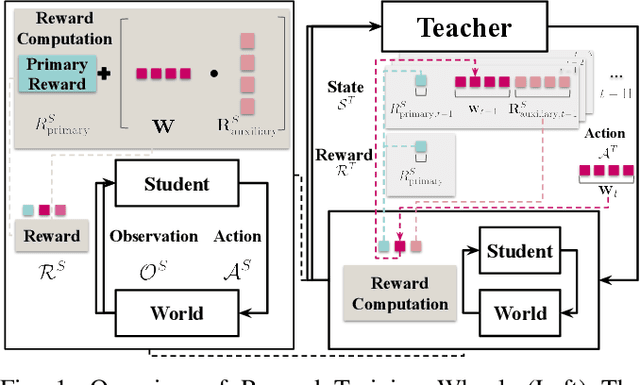
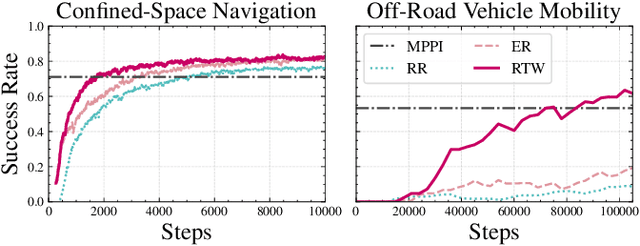

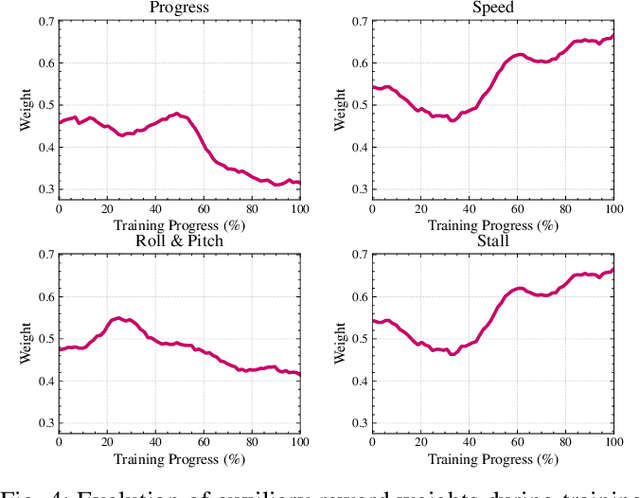
Robotics Reinforcement Learning (RL) often relies on carefully engineered auxiliary rewards to supplement sparse primary learning objectives to compensate for the lack of large-scale, real-world, trial-and-error data. While these auxiliary rewards accelerate learning, they require significant engineering effort, may introduce human biases, and cannot adapt to the robot's evolving capabilities during training. In this paper, we introduce Reward Training Wheels (RTW), a teacher-student framework that automates auxiliary reward adaptation for robotics RL. To be specific, the RTW teacher dynamically adjusts auxiliary reward weights based on the student's evolving capabilities to determine which auxiliary reward aspects require more or less emphasis to improve the primary objective. We demonstrate RTW on two challenging robot tasks: navigation in highly constrained spaces and off-road vehicle mobility on vertically challenging terrain. In simulation, RTW outperforms expert-designed rewards by 2.35% in navigation success rate and improves off-road mobility performance by 122.62%, while achieving 35% and 3X faster training efficiency, respectively. Physical robot experiments further validate RTW's effectiveness, achieving a perfect success rate (5/5 trials vs. 2/5 for expert-designed rewards) and improving vehicle stability with up to 47.4% reduction in orientation angles.