 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStatistical Reinforcement Learning in the Real World: A Survey of Challenges and Future Directions
Jan 21, 2026Reinforcement learning (RL) has achieved remarkable success in real-world decision-making across diverse domains, including gaming, robotics, online advertising, public health, and natural language processing. Despite these advances, a substantial gap remains between RL research and its deployment in many practical settings. Two recurring challenges often underlie this gap. First, many settings offer limited opportunity for the agent to interact extensively with the target environment due to practical constraints. Second, many target environments often undergo substantial changes, requiring redesign and redeployment of RL systems (e.g., advancements in science and technology that change the landscape of healthcare delivery). Addressing these challenges and bridging the gap between basic research and application requires theory and methodology that directly inform the design, implementation, and continual improvement of RL systems in real-world settings. In this paper, we frame the application of RL in practice as a three-component process: (i) online learning and optimization during deployment, (ii) post- or between-deployment offline analyses, and (iii) repeated cycles of deployment and redeployment to continually improve the RL system. We provide a narrative review of recent advances in statistical RL that address these components, including methods for maximizing data utility for between-deployment inference, enhancing sample efficiency for online learning within-deployment, and designing sequences of deployments for continual improvement. We also outline future research directions in statistical RL that are use-inspired -- aiming for impactful application of RL in practice.
Active Measuring in Reinforcement Learning With Delayed Negative Effects
Oct 16, 2025Measuring states in reinforcement learning (RL) can be costly in real-world settings and may negatively influence future outcomes. We introduce the Actively Observable Markov Decision Process (AOMDP), where an agent not only selects control actions but also decides whether to measure the latent state. The measurement action reveals the true latent state but may have a negative delayed effect on the environment. We show that this reduced uncertainty may provably improve sample efficiency and increase the value of the optimal policy despite these costs. We formulate an AOMDP as a periodic partially observable MDP and propose an online RL algorithm based on belief states. To approximate the belief states, we further propose a sequential Monte Carlo method to jointly approximate the posterior of unknown static environment parameters and unobserved latent states. We evaluate the proposed algorithm in a digital health application, where the agent decides when to deliver digital interventions and when to assess users' health status through surveys.
The Fallacy of Minimizing Local Regret in the Sequential Task Setting
Mar 16, 2024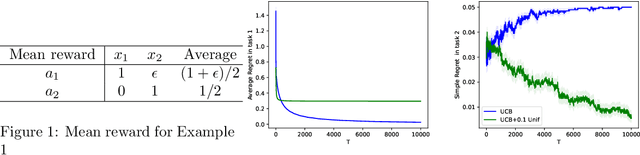
In the realm of Reinforcement Learning (RL), online RL is often conceptualized as an optimization problem, where an algorithm interacts with an unknown environment to minimize cumulative regret. In a stationary setting, strong theoretical guarantees, like a sublinear ($\sqrt{T}$) regret bound, can be obtained, which typically implies the convergence to an optimal policy and the cessation of exploration. However, these theoretical setups often oversimplify the complexities encountered in real-world RL implementations, where tasks arrive sequentially with substantial changes between tasks and the algorithm may not be allowed to adaptively learn within certain tasks. We study the changes beyond the outcome distributions, encompassing changes in the reward designs (mappings from outcomes to rewards) and the permissible policy spaces. Our results reveal the fallacy of myopically minimizing regret within each task: obtaining optimal regret rates in the early tasks may lead to worse rates in the subsequent ones, even when the outcome distributions stay the same. To realize the optimal cumulative regret bound across all the tasks, the algorithm has to overly explore in the earlier tasks. This theoretical insight is practically significant, suggesting that due to unanticipated changes (e.g., rapid technological development or human-in-the-loop involvement) between tasks, the algorithm needs to explore more than it would in the usual stationary setting within each task. Such implication resonates with the common practice of using clipped policies in mobile health clinical trials and maintaining a fixed rate of $\epsilon$-greedy exploration in robotic learning.
A Natural Extension To Online Algorithms For Hybrid RL With Limited Coverage
Mar 07, 2024
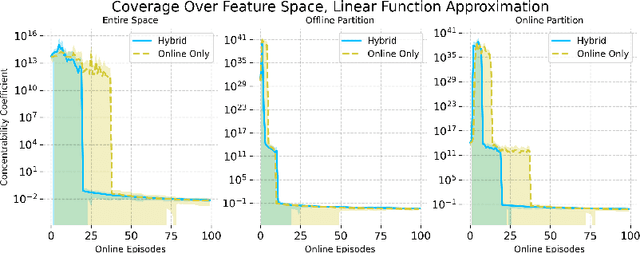


Hybrid Reinforcement Learning (RL), leveraging both online and offline data, has garnered recent interest, yet research on its provable benefits remains sparse. Additionally, many existing hybrid RL algorithms (Song et al., 2023; Nakamoto et al., 2023; Amortila et al., 2024) impose coverage assumptions on the offline dataset, but we show that this is unnecessary. A well-designed online algorithm should "fill in the gaps" in the offline dataset, exploring states and actions that the behavior policy did not explore. Unlike previous approaches that focus on estimating the offline data distribution to guide online exploration (Li et al., 2023b), we show that a natural extension to standard optimistic online algorithms -- warm-starting them by including the offline dataset in the experience replay buffer -- achieves similar provable gains from hybrid data even when the offline dataset does not have single-policy concentrability. We accomplish this by partitioning the state-action space into two, bounding the regret on each partition through an offline and an online complexity measure, and showing that the regret of this hybrid RL algorithm can be characterized by the best partition -- despite the algorithm not knowing the partition itself. As an example, we propose DISC-GOLF, a modification of an existing optimistic online algorithm with general function approximation called GOLF used in Jin et al. (2021); Xie et al. (2022a), and show that it demonstrates provable gains over both online-only and offline-only reinforcement learning, with competitive bounds when specialized to the tabular, linear and block MDP cases. Numerical simulations further validate our theory that hybrid data facilitates more efficient exploration, supporting the potential of hybrid RL in various scenarios.
Sample Efficient Myopic Exploration Through Multitask Reinforcement Learning with Diverse Tasks
Mar 06, 2024



Multitask Reinforcement Learning (MTRL) approaches have gained increasing attention for its wide applications in many important Reinforcement Learning (RL) tasks. However, while recent advancements in MTRL theory have focused on the improved statistical efficiency by assuming a shared structure across tasks, exploration--a crucial aspect of RL--has been largely overlooked. This paper addresses this gap by showing that when an agent is trained on a sufficiently diverse set of tasks, a generic policy-sharing algorithm with myopic exploration design like $\epsilon$-greedy that are inefficient in general can be sample-efficient for MTRL. To the best of our knowledge, this is the first theoretical demonstration of the "exploration benefits" of MTRL. It may also shed light on the enigmatic success of the wide applications of myopic exploration in practice. To validate the role of diversity, we conduct experiments on synthetic robotic control environments, where the diverse task set aligns with the task selection by automatic curriculum learning, which is empirically shown to improve sample-efficiency.
Adaptive Learning for Discovery
Jun 03, 2022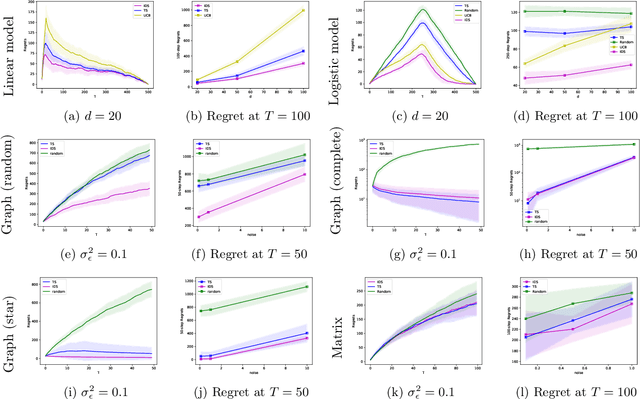
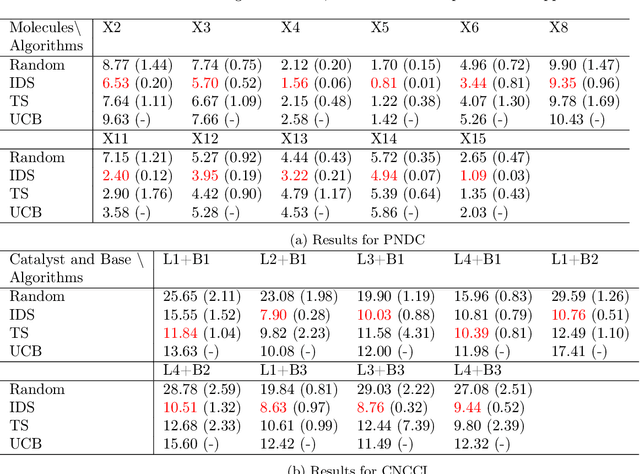
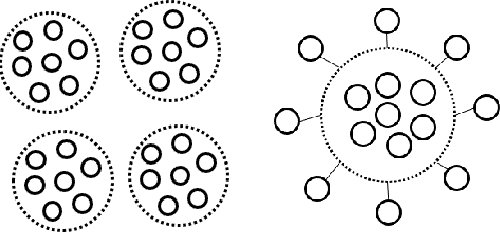
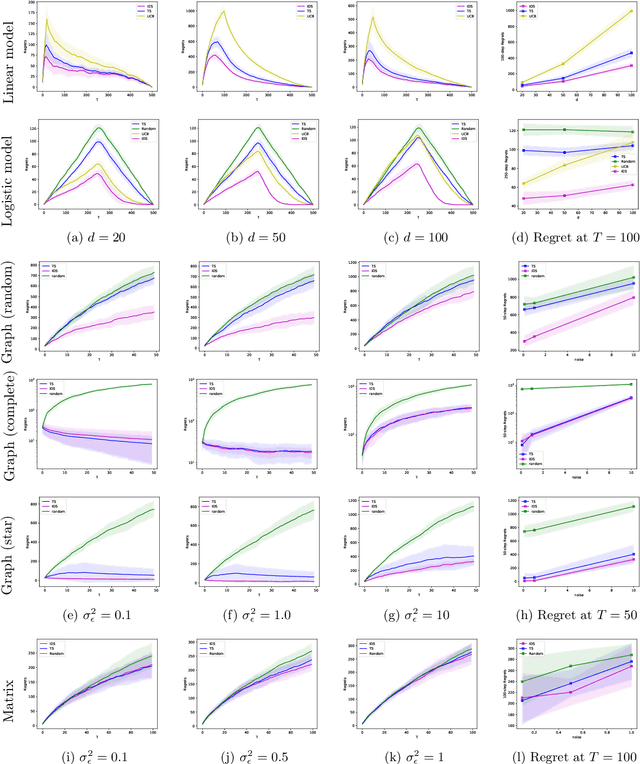
In this paper, we study a sequential decision-making problem, called Adaptive Sampling for Discovery (ASD). Starting with a large unlabeled dataset, algorithms for ASD adaptively label the points with the goal to maximize the sum of responses. This problem has wide applications to real-world discovery problems, for example drug discovery with the help of machine learning models. ASD algorithms face the well-known exploration-exploitation dilemma. The algorithm needs to choose points that yield information to improve model estimates but it also needs to exploit the model. We rigorously formulate the problem and propose a general information-directed sampling (IDS) algorithm. We provide theoretical guarantees for the performance of IDS in linear, graph and low-rank models. The benefits of IDS are shown in both simulation experiments and real-data experiments for discovering chemical reaction conditions.
On the Statistical Benefits of Curriculum Learning
Nov 13, 2021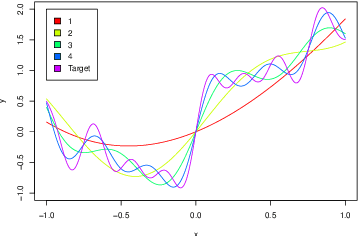
Curriculum learning (CL) is a commonly used machine learning training strategy. However, we still lack a clear theoretical understanding of CL's benefits. In this paper, we study the benefits of CL in the multitask linear regression problem under both structured and unstructured settings. For both settings, we derive the minimax rates for CL with the oracle that provides the optimal curriculum and without the oracle, where the agent has to adaptively learn a good curriculum. Our results reveal that adaptive learning can be fundamentally harder than the oracle learning in the unstructured setting, but it merely introduces a small extra term in the structured setting. To connect theory with practice, we provide justification for a popular empirical method that selects tasks with highest local prediction gain by comparing its guarantees with the minimax rates mentioned above.
Bandit Algorithms for Precision Medicine
Aug 10, 2021The Oxford English Dictionary defines precision medicine as "medical care designed to optimize efficiency or therapeutic benefit for particular groups of patients, especially by using genetic or molecular profiling." It is not an entirely new idea: physicians from ancient times have recognized that medical treatment needs to consider individual variations in patient characteristics. However, the modern precision medicine movement has been enabled by a confluence of events: scientific advances in fields such as genetics and pharmacology, technological advances in mobile devices and wearable sensors, and methodological advances in computing and data sciences. This chapter is about bandit algorithms: an area of data science of special relevance to precision medicine. With their roots in the seminal work of Bellman, Robbins, Lai and others, bandit algorithms have come to occupy a central place in modern data science ( Lattimore and Szepesvari, 2020). Bandit algorithms can be used in any situation where treatment decisions need to be made to optimize some health outcome. Since precision medicine focuses on the use of patient characteristics to guide treatment, contextual bandit algorithms are especially useful since they are designed to take such information into account. The role of bandit algorithms in areas of precision medicine such as mobile health and digital phenotyping has been reviewed before (Tewari and Murphy, 2017; Rabbi et al., 2019). Since these reviews were published, bandit algorithms have continued to find uses in mobile health and several new topics have emerged in the research on bandit algorithms. This chapter is written for quantitative researchers in fields such as statistics, machine learning, and operations research who might be interested in knowing more about the algorithmic and mathematical details of bandit algorithms that have been used in mobile health.
Safe Exploration by Solving Early Terminated MDP
Jul 09, 2021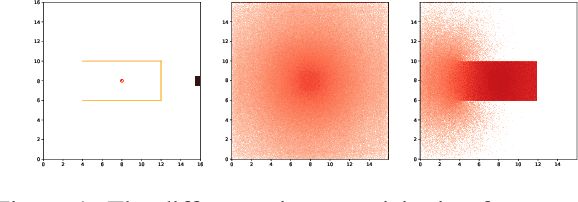


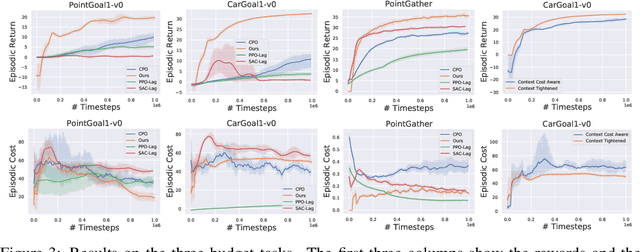
Safe exploration is crucial for the real-world application of reinforcement learning (RL). Previous works consider the safe exploration problem as Constrained Markov Decision Process (CMDP), where the policies are being optimized under constraints. However, when encountering any potential dangers, human tends to stop immediately and rarely learns to behave safely in danger. Motivated by human learning, we introduce a new approach to address safe RL problems under the framework of Early Terminated MDP (ET-MDP). We first define the ET-MDP as an unconstrained MDP with the same optimal value function as its corresponding CMDP. An off-policy algorithm based on context models is then proposed to solve the ET-MDP, which thereby solves the corresponding CMDP with better asymptotic performance and improved learning efficiency. Experiments on various CMDP tasks show a substantial improvement over previous methods that directly solve CMDP.
Representation Learning Beyond Linear Prediction Functions
May 31, 2021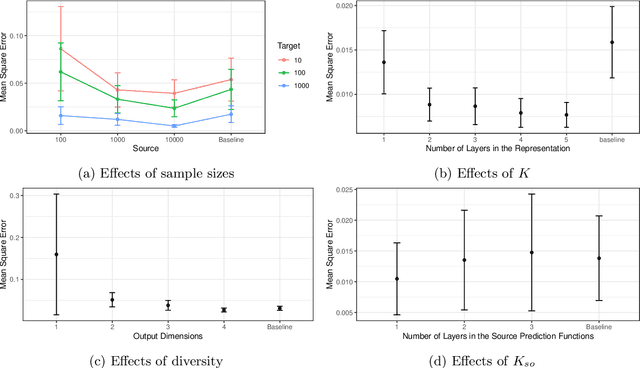
Recent papers on the theory of representation learning has shown the importance of a quantity called diversity when generalizing from a set of source tasks to a target task. Most of these papers assume that the function mapping shared representations to predictions is linear, for both source and target tasks. In practice, researchers in deep learning use different numbers of extra layers following the pretrained model based on the difficulty of the new task. This motivates us to ask whether diversity can be achieved when source tasks and the target task use different prediction function spaces beyond linear functions. We show that diversity holds even if the target task uses a neural network with multiple layers, as long as source tasks use linear functions. If source tasks use nonlinear prediction functions, we provide a negative result by showing that depth-1 neural networks with ReLu activation function need exponentially many source tasks to achieve diversity. For a general function class, we find that eluder dimension gives a lower bound on the number of tasks required for diversity. Our theoretical results imply that simpler tasks generalize better. Though our theoretical results are shown for the global minimizer of empirical risks, their qualitative predictions still hold true for gradient-based optimization algorithms as verified by our simulations on deep neural networks.