 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafe Exploration by Solving Early Terminated MDP
Paper and Code
Jul 09, 2021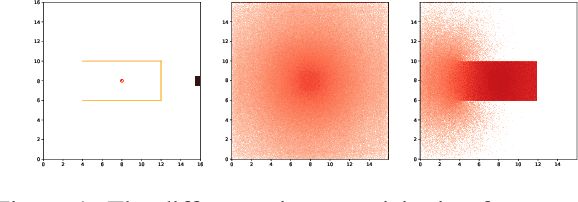


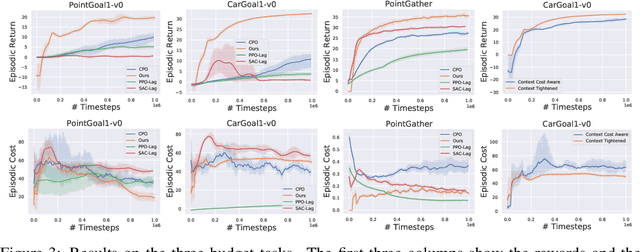
Safe exploration is crucial for the real-world application of reinforcement learning (RL). Previous works consider the safe exploration problem as Constrained Markov Decision Process (CMDP), where the policies are being optimized under constraints. However, when encountering any potential dangers, human tends to stop immediately and rarely learns to behave safely in danger. Motivated by human learning, we introduce a new approach to address safe RL problems under the framework of Early Terminated MDP (ET-MDP). We first define the ET-MDP as an unconstrained MDP with the same optimal value function as its corresponding CMDP. An off-policy algorithm based on context models is then proposed to solve the ET-MDP, which thereby solves the corresponding CMDP with better asymptotic performance and improved learning efficiency. Experiments on various CMDP tasks show a substantial improvement over previous methods that directly solve CMDP.