 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTabular Foundation Models Can Do Survival Analysis
Jan 29, 2026While tabular foundation models have achieved remarkable success in classification and regression, adapting them to model time-to-event outcomes for survival analysis is non-trivial due to right-censoring, where data observations may end before the event occurs. We develop a classification-based framework that reformulates both static and dynamic survival analysis as a series of binary classification problems by discretizing event times. Censored observations are naturally handled as examples with missing labels at certain time points. This classification formulation enables existing tabular foundation models to perform survival analysis through in-context learning without explicit training. We prove that under standard censoring assumptions, minimizing our binary classification loss recovers the true survival probabilities as the training set size increases. We demonstrate through evaluation across $53$ real-world datasets that off-the-shelf tabular foundation models with this classification formulation outperform classical and deep learning baselines on average over multiple survival metrics.
Statistical Reinforcement Learning in the Real World: A Survey of Challenges and Future Directions
Jan 21, 2026Reinforcement learning (RL) has achieved remarkable success in real-world decision-making across diverse domains, including gaming, robotics, online advertising, public health, and natural language processing. Despite these advances, a substantial gap remains between RL research and its deployment in many practical settings. Two recurring challenges often underlie this gap. First, many settings offer limited opportunity for the agent to interact extensively with the target environment due to practical constraints. Second, many target environments often undergo substantial changes, requiring redesign and redeployment of RL systems (e.g., advancements in science and technology that change the landscape of healthcare delivery). Addressing these challenges and bridging the gap between basic research and application requires theory and methodology that directly inform the design, implementation, and continual improvement of RL systems in real-world settings. In this paper, we frame the application of RL in practice as a three-component process: (i) online learning and optimization during deployment, (ii) post- or between-deployment offline analyses, and (iii) repeated cycles of deployment and redeployment to continually improve the RL system. We provide a narrative review of recent advances in statistical RL that address these components, including methods for maximizing data utility for between-deployment inference, enhancing sample efficiency for online learning within-deployment, and designing sequences of deployments for continual improvement. We also outline future research directions in statistical RL that are use-inspired -- aiming for impactful application of RL in practice.
Contextual Thompson Sampling via Generation of Missing Data
Feb 10, 2025We introduce a framework for Thompson sampling contextual bandit algorithms, in which the algorithm's ability to quantify uncertainty and make decisions depends on the quality of a generative model that is learned offline. Instead of viewing uncertainty in the environment as arising from unobservable latent parameters, our algorithm treats uncertainty as stemming from missing, but potentially observable, future outcomes. If these future outcomes were all observed, one could simply make decisions using an "oracle" policy fit on the complete dataset. Inspired by this conceptualization, at each decision-time, our algorithm uses a generative model to probabilistically impute missing future outcomes, fits a policy using the imputed complete dataset, and uses that policy to select the next action. We formally show that this algorithm is a generative formulation of Thompson Sampling and prove a state-of-the-art regret bound for it. Notably, our regret bound i) depends on the probabilistic generative model only through the quality of its offline prediction loss, and ii) applies to any method of fitting the "oracle" policy, which easily allows one to adapt Thompson sampling to decision-making settings with fairness and/or resource constraints.
Impatient Bandits: Optimizing for the Long-Term Without Delay
Jan 14, 2025


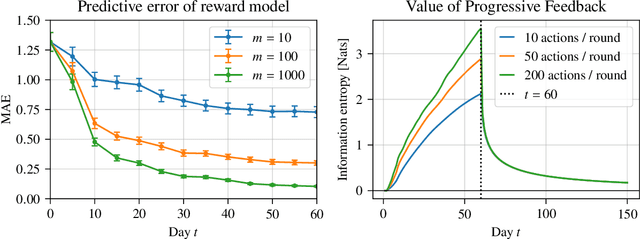
Increasingly, recommender systems are tasked with improving users' long-term satisfaction. In this context, we study a content exploration task, which we formalize as a bandit problem with delayed rewards. There is an apparent trade-off in choosing the learning signal: waiting for the full reward to become available might take several weeks, slowing the rate of learning, whereas using short-term proxy rewards reflects the actual long-term goal only imperfectly. First, we develop a predictive model of delayed rewards that incorporates all information obtained to date. Rewards as well as shorter-term surrogate outcomes are combined through a Bayesian filter to obtain a probabilistic belief. Second, we devise a bandit algorithm that quickly learns to identify content aligned with long-term success using this new predictive model. We prove a regret bound for our algorithm that depends on the \textit{Value of Progressive Feedback}, an information theoretic metric that captures the quality of short-term leading indicators that are observed prior to the long-term reward. We apply our approach to a podcast recommendation problem, where we seek to recommend shows that users engage with repeatedly over two months. We empirically validate that our approach significantly outperforms methods that optimize for short-term proxies or rely solely on delayed rewards, as demonstrated by an A/B test in a recommendation system that serves hundreds of millions of users.
A Deployed Online Reinforcement Learning Algorithm In An Oral Health Clinical Trial
Sep 03, 2024



Dental disease is a prevalent chronic condition associated with substantial financial burden, personal suffering, and increased risk of systemic diseases. Despite widespread recommendations for twice-daily tooth brushing, adherence to recommended oral self-care behaviors remains sub-optimal due to factors such as forgetfulness and disengagement. To address this, we developed Oralytics, a mHealth intervention system designed to complement clinician-delivered preventative care for marginalized individuals at risk for dental disease. Oralytics incorporates an online reinforcement learning algorithm to determine optimal times to deliver intervention prompts that encourage oral self-care behaviors. We have deployed Oralytics in a registered clinical trial. The deployment required careful design to manage challenges specific to the clinical trials setting in the U.S. In this paper, we (1) highlight key design decisions of the RL algorithm that address these challenges and (2) conduct a re-sampling analysis to evaluate algorithm design decisions. A second phase (randomized control trial) of Oralytics is planned to start in spring 2025.
Oralytics Reinforcement Learning Algorithm
Jun 19, 2024
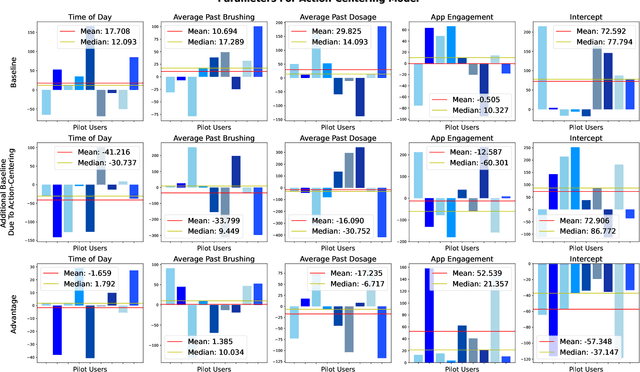


Dental disease is still one of the most common chronic diseases in the United States. While dental disease is preventable through healthy oral self-care behaviors (OSCB), this basic behavior is not consistently practiced. We have developed Oralytics, an online, reinforcement learning (RL) algorithm that optimizes the delivery of personalized intervention prompts to improve OSCB. In this paper, we offer a full overview of algorithm design decisions made using prior data, domain expertise, and experiments in a simulation test bed. The finalized RL algorithm was deployed in the Oralytics clinical trial, conducted from fall 2023 to summer 2024.
The Fallacy of Minimizing Local Regret in the Sequential Task Setting
Mar 16, 2024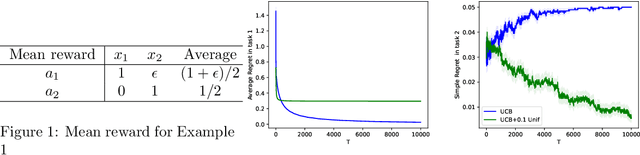
In the realm of Reinforcement Learning (RL), online RL is often conceptualized as an optimization problem, where an algorithm interacts with an unknown environment to minimize cumulative regret. In a stationary setting, strong theoretical guarantees, like a sublinear ($\sqrt{T}$) regret bound, can be obtained, which typically implies the convergence to an optimal policy and the cessation of exploration. However, these theoretical setups often oversimplify the complexities encountered in real-world RL implementations, where tasks arrive sequentially with substantial changes between tasks and the algorithm may not be allowed to adaptively learn within certain tasks. We study the changes beyond the outcome distributions, encompassing changes in the reward designs (mappings from outcomes to rewards) and the permissible policy spaces. Our results reveal the fallacy of myopically minimizing regret within each task: obtaining optimal regret rates in the early tasks may lead to worse rates in the subsequent ones, even when the outcome distributions stay the same. To realize the optimal cumulative regret bound across all the tasks, the algorithm has to overly explore in the earlier tasks. This theoretical insight is practically significant, suggesting that due to unanticipated changes (e.g., rapid technological development or human-in-the-loop involvement) between tasks, the algorithm needs to explore more than it would in the usual stationary setting within each task. Such implication resonates with the common practice of using clipped policies in mobile health clinical trials and maintaining a fixed rate of $\epsilon$-greedy exploration in robotic learning.
Monitoring Fidelity of Online Reinforcement Learning Algorithms in Clinical Trials
Feb 26, 2024
Online reinforcement learning (RL) algorithms offer great potential for personalizing treatment for participants in clinical trials. However, deploying an online, autonomous algorithm in the high-stakes healthcare setting makes quality control and data quality especially difficult to achieve. This paper proposes algorithm fidelity as a critical requirement for deploying online RL algorithms in clinical trials. It emphasizes the responsibility of the algorithm to (1) safeguard participants and (2) preserve the scientific utility of the data for post-trial analyses. We also present a framework for pre-deployment planning and real-time monitoring to help algorithm developers and clinical researchers ensure algorithm fidelity. To illustrate our framework's practical application, we present real-world examples from the Oralytics clinical trial. Since Spring 2023, this trial successfully deployed an autonomous, online RL algorithm to personalize behavioral interventions for participants at risk for dental disease.
Reward Design For An Online Reinforcement Learning Algorithm Supporting Oral Self-Care
Aug 15, 2022
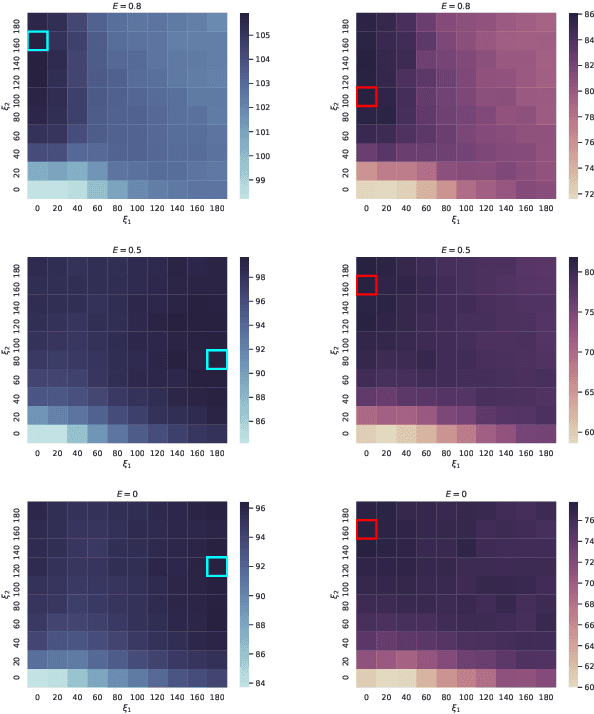

Dental disease is one of the most common chronic diseases despite being largely preventable. However, professional advice on optimal oral hygiene practices is often forgotten or abandoned by patients. Therefore patients may benefit from timely and personalized encouragement to engage in oral self-care behaviors. In this paper, we develop an online reinforcement learning (RL) algorithm for use in optimizing the delivery of mobile-based prompts to encourage oral hygiene behaviors. One of the main challenges in developing such an algorithm is ensuring that the algorithm considers the impact of the current action on the effectiveness of future actions (i.e., delayed effects), especially when the algorithm has been made simple in order to run stably and autonomously in a constrained, real-world setting (i.e., highly noisy, sparse data). We address this challenge by designing a quality reward which maximizes the desired health outcome (i.e., high-quality brushing) while minimizing user burden. We also highlight a procedure for optimizing the hyperparameters of the reward by building a simulation environment test bed and evaluating candidates using the test bed. The RL algorithm discussed in this paper will be deployed in Oralytics, an oral self-care app that provides behavioral strategies to boost patient engagement in oral hygiene practices.
A Bayesian Approach to Learning Bandit Structure in Markov Decision Processes
Jul 30, 2022
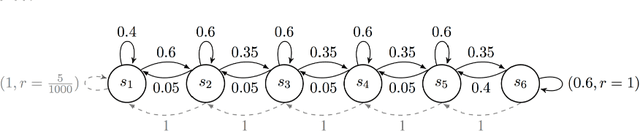


In the reinforcement learning literature, there are many algorithms developed for either Contextual Bandit (CB) or Markov Decision Processes (MDP) environments. However, when deploying reinforcement learning algorithms in the real world, even with domain expertise, it is often difficult to know whether it is appropriate to treat a sequential decision making problem as a CB or an MDP. In other words, do actions affect future states, or only the immediate rewards? Making the wrong assumption regarding the nature of the environment can lead to inefficient learning, or even prevent the algorithm from ever learning an optimal policy, even with infinite data. In this work we develop an online algorithm that uses a Bayesian hypothesis testing approach to learn the nature of the environment. Our algorithm allows practitioners to incorporate prior knowledge about whether the environment is that of a CB or an MDP, and effectively interpolate between classical CB and MDP-based algorithms to mitigate against the effects of misspecifying the environment. We perform simulations and demonstrate that in CB settings our algorithm achieves lower regret than MDP-based algorithms, while in non-bandit MDP settings our algorithm is able to learn the optimal policy, often achieving comparable regret to MDP-based algorithms.