 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContextual Thompson Sampling via Generation of Missing Data
Feb 10, 2025We introduce a framework for Thompson sampling contextual bandit algorithms, in which the algorithm's ability to quantify uncertainty and make decisions depends on the quality of a generative model that is learned offline. Instead of viewing uncertainty in the environment as arising from unobservable latent parameters, our algorithm treats uncertainty as stemming from missing, but potentially observable, future outcomes. If these future outcomes were all observed, one could simply make decisions using an "oracle" policy fit on the complete dataset. Inspired by this conceptualization, at each decision-time, our algorithm uses a generative model to probabilistically impute missing future outcomes, fits a policy using the imputed complete dataset, and uses that policy to select the next action. We formally show that this algorithm is a generative formulation of Thompson Sampling and prove a state-of-the-art regret bound for it. Notably, our regret bound i) depends on the probabilistic generative model only through the quality of its offline prediction loss, and ii) applies to any method of fitting the "oracle" policy, which easily allows one to adapt Thompson sampling to decision-making settings with fairness and/or resource constraints.
C-Learner: Constrained Learning for Causal Inference and Semiparametric Statistics
May 22, 2024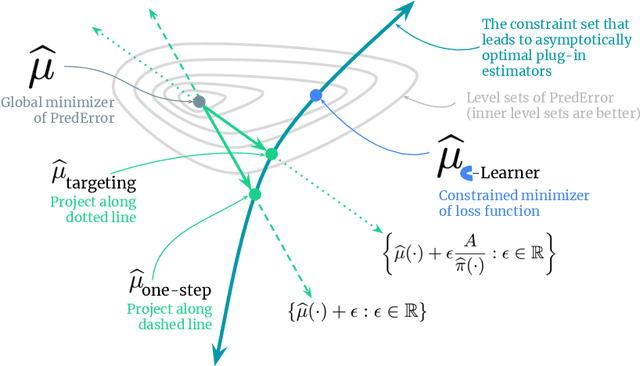
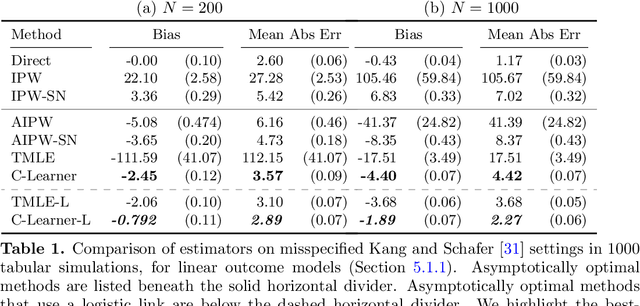
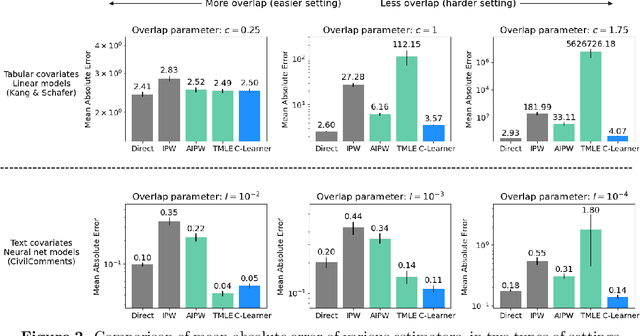
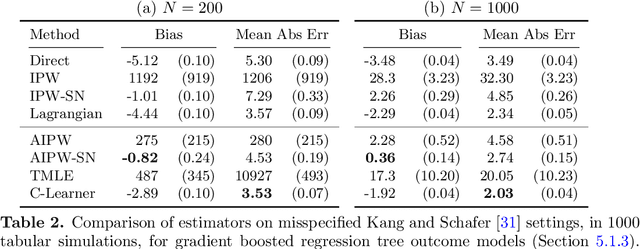
Causal estimation (e.g. of the average treatment effect) requires estimating complex nuisance parameters (e.g. outcome models). To adjust for errors in nuisance parameter estimation, we present a novel correction method that solves for the best plug-in estimator under the constraint that the first-order error of the estimator with respect to the nuisance parameter estimate is zero. Our constrained learning framework provides a unifying perspective to prominent first-order correction approaches including one-step estimation (a.k.a. augmented inverse probability weighting) and targeting (a.k.a. targeted maximum likelihood estimation). Our semiparametric inference approach, which we call the "C-Learner", can be implemented with modern machine learning methods such as neural networks and tree ensembles, and enjoys standard guarantees like semiparametric efficiency and double robustness. Empirically, we demonstrate our approach on several datasets, including those with text features that require fine-tuning language models. We observe the C-Learner matches or outperforms other asymptotically optimal estimators, with better performance in settings with less estimated overlap.
Constrained Learning for Causal Inference and Semiparametric Statistics
May 15, 2024Causal estimation (e.g. of the average treatment effect) requires estimating complex nuisance parameters (e.g. outcome models). To adjust for errors in nuisance parameter estimation, we present a novel correction method that solves for the best plug-in estimator under the constraint that the first-order error of the estimator with respect to the nuisance parameter estimate is zero. Our constrained learning framework provides a unifying perspective to prominent first-order correction approaches including debiasing (a.k.a. augmented inverse probability weighting) and targeting (a.k.a. targeted maximum likelihood estimation). Our semiparametric inference approach, which we call the "C-Learner", can be implemented with modern machine learning methods such as neural networks and tree ensembles, and enjoys standard guarantees like semiparametric efficiency and double robustness. Empirically, we demonstrate our approach on several datasets, including those with text features that require fine-tuning language models. We observe the C-Learner matches or outperforms other asymptotically optimal estimators, with better performance in settings with less estimated overlap.
Diagnosing Model Performance Under Distribution Shift
Mar 10, 2023Prediction models can perform poorly when deployed to target distributions different from the training distribution. To understand these operational failure modes, we develop a method, called DIstribution Shift DEcomposition (DISDE), to attribute a drop in performance to different types of distribution shifts. Our approach decomposes the performance drop into terms for 1) an increase in harder but frequently seen examples from training, 2) changes in the relationship between features and outcomes, and 3) poor performance on examples infrequent or unseen during training. These terms are defined by fixing a distribution on $X$ while varying the conditional distribution of $Y \mid X$ between training and target, or by fixing the conditional distribution of $Y \mid X$ while varying the distribution on $X$. In order to do this, we define a hypothetical distribution on $X$ consisting of values common in both training and target, over which it is easy to compare $Y \mid X$ and thus predictive performance. We estimate performance on this hypothetical distribution via reweighting methods. Empirically, we show how our method can 1) inform potential modeling improvements across distribution shifts for employment prediction on tabular census data, and 2) help to explain why certain domain adaptation methods fail to improve model performance for satellite image classification.
Are all negatives created equal in contrastive instance discrimination?
Oct 25, 2020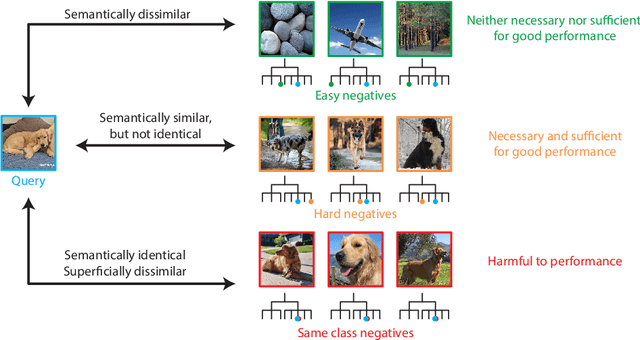
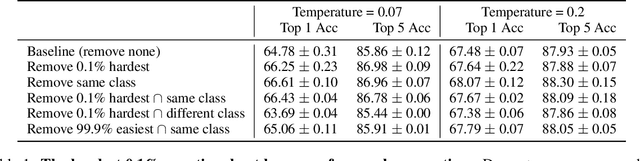
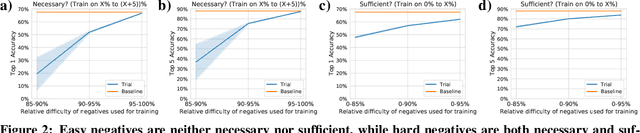
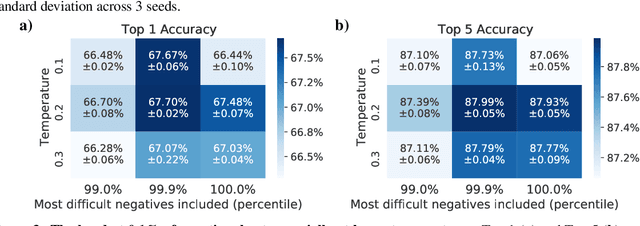
Self-supervised learning has recently begun to rival supervised learning on computer vision tasks. Many of the recent approaches have been based on contrastive instance discrimination (CID), in which the network is trained to recognize two augmented versions of the same instance (a query and positive) while discriminating against a pool of other instances (negatives). The learned representation is then used on downstream tasks such as image classification. Using methodology from MoCo v2 (Chen et al., 2020), we divided negatives by their difficulty for a given query and studied which difficulty ranges were most important for learning useful representations. We found a minority of negatives -- the hardest 5% -- were both necessary and sufficient for the downstream task to reach nearly full accuracy. Conversely, the easiest 95% of negatives were unnecessary and insufficient. Moreover, the very hardest 0.1% of negatives were unnecessary and sometimes detrimental. Finally, we studied the properties of negatives that affect their hardness, and found that hard negatives were more semantically similar to the query, and that some negatives were more consistently easy or hard than we would expect by chance. Together, our results indicate that negatives vary in importance and that CID may benefit from more intelligent negative treatment.