 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStatistical Inference for Explainable Boosting Machines
Jan 26, 2026Explainable boosting machines (EBMs) are popular "glass-box" models that learn a set of univariate functions using boosting trees. These achieve explainability through visualizations of each feature's effect. However, unlike linear model coefficients, uncertainty quantification for the learned univariate functions requires computationally intensive bootstrapping, making it hard to know which features truly matter. We provide an alternative using recent advances in statistical inference for gradient boosting, deriving methods for statistical inference as well as end-to-end theoretical guarantees. Using a moving average instead of a sum of trees (Boulevard regularization) allows the boosting process to converge to a feature-wise kernel ridge regression. This produces asymptotically normal predictions that achieve the minimax-optimal mean squared error for fitting Lipschitz GAMs with $p$ features at rate $O(pn^{-2/3})$, successfully avoiding the curse of dimensionality. We then construct prediction intervals for the response and confidence intervals for each learned univariate function with a runtime independent of the number of datapoints, enabling further explainability within EBMs.
Actor-Critics Can Achieve Optimal Sample Efficiency
May 06, 2025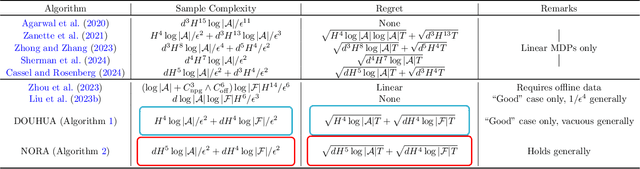
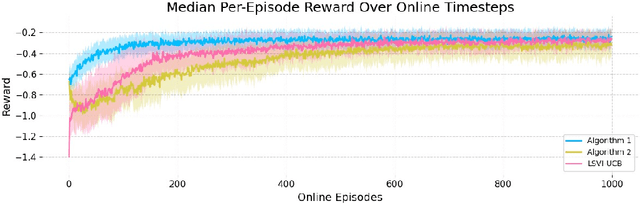
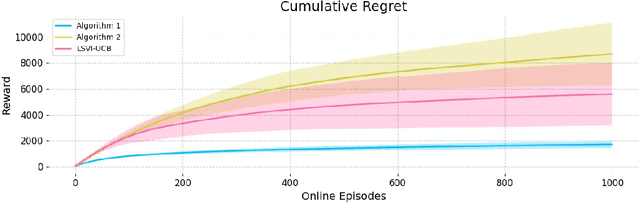
Actor-critic algorithms have become a cornerstone in reinforcement learning (RL), leveraging the strengths of both policy-based and value-based methods. Despite recent progress in understanding their statistical efficiency, no existing work has successfully learned an $\epsilon$-optimal policy with a sample complexity of $O(1/\epsilon^2)$ trajectories with general function approximation when strategic exploration is necessary. We address this open problem by introducing a novel actor-critic algorithm that attains a sample-complexity of $O(dH^5 \log|\mathcal{A}|/\epsilon^2 + d H^4 \log|\mathcal{F}|/ \epsilon^2)$ trajectories, and accompanying $\sqrt{T}$ regret when the Bellman eluder dimension $d$ does not increase with $T$ at more than a $\log T$ rate. Here, $\mathcal{F}$ is the critic function class, $\mathcal{A}$ is the action space, and $H$ is the horizon in the finite horizon MDP setting. Our algorithm integrates optimism, off-policy critic estimation targeting the optimal Q-function, and rare-switching policy resets. We extend this to the setting of Hybrid RL, showing that initializing the critic with offline data yields sample efficiency gains compared to purely offline or online RL. Further, utilizing access to offline data, we provide a \textit{non-optimistic} provably efficient actor-critic algorithm that only additionally requires $N_{\text{off}} \geq c_{\text{off}}^*dH^4/\epsilon^2$ in exchange for omitting optimism, where $c_{\text{off}}^*$ is the single-policy concentrability coefficient and $N_{\text{off}}$ is the number of offline samples. This addresses another open problem in the literature. We further provide numerical experiments to support our theoretical findings.
6D Pose Estimation on Spoons and Hands
May 05, 2025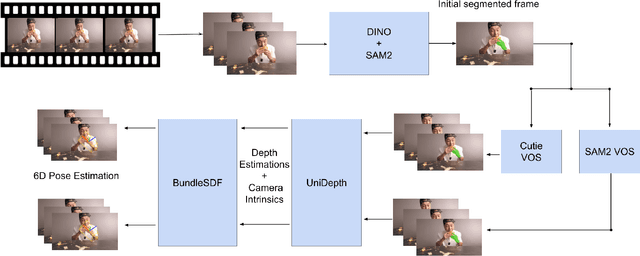



Accurate dietary monitoring is essential for promoting healthier eating habits. A key area of research is how people interact and consume food using utensils and hands. By tracking their position and orientation, it is possible to estimate the volume of food being consumed, or monitor eating behaviours, highly useful insights into nutritional intake that can be more reliable than popular methods such as self-reporting. Hence, this paper implements a system that analyzes stationary video feed of people eating, using 6D pose estimation to track hand and spoon movements to capture spatial position and orientation. In doing so, we examine the performance of two state-of-the-art (SOTA) video object segmentation (VOS) models, both quantitatively and qualitatively, and identify main sources of error within the system.
Interpretable Hierarchical Attention Network for Medical Condition Identification
Dec 04, 2024


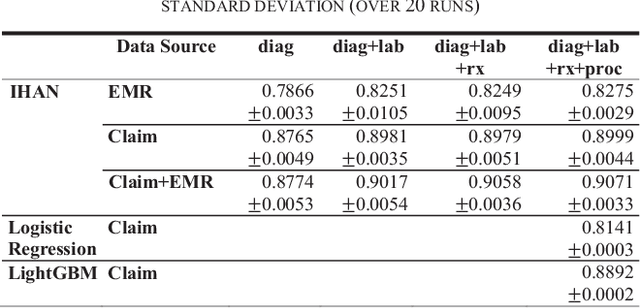
Accurate prediction of medical conditions with straight past clinical evidence is a long-sought topic in the medical management and health insurance field. Although great progress has been made with machine learning algorithms, the medical community is still skeptical about the model accuracy and interpretability. This paper presents an innovative hierarchical attention deep learning model to achieve better prediction and clear interpretability that can be easily understood by medical professionals. This paper developed an Interpretable Hierarchical Attention Network (IHAN). IHAN uses a hierarchical attention structure that matches naturally with the medical history data structure and reflects patients encounter (date of service) sequence. The model attention structure consists of 3 levels: (1) attention on the medical code types (diagnosis codes, procedure codes, lab test results, and prescription drugs), (2) attention on the sequential medical encounters within a type, (3) attention on the individual medical codes within an encounter and type. This model is applied to predict the occurrence of stage 3 chronic kidney disease (CKD), using three years medical history of Medicare Advantage (MA) members from an American nationwide health insurance company. The model takes members medical events, both claims and Electronic Medical Records (EMR) data, as input, makes a prediction of stage 3 CKD and calculates contribution from individual events to the predicted outcome.
Hybrid Reinforcement Learning Breaks Sample Size Barriers in Linear MDPs
Aug 08, 2024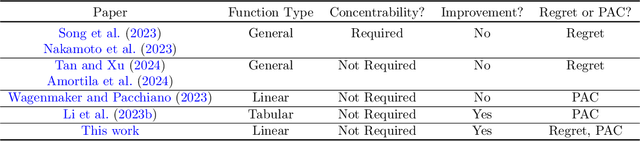
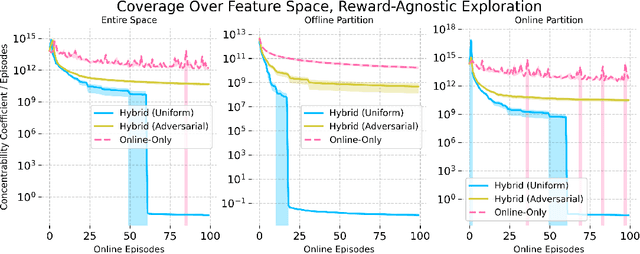

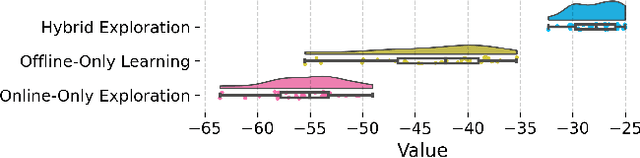
Hybrid Reinforcement Learning (RL), where an agent learns from both an offline dataset and online explorations in an unknown environment, has garnered significant recent interest. A crucial question posed by Xie et al. (2022) is whether hybrid RL can improve upon the existing lower bounds established in purely offline and purely online RL without relying on the single-policy concentrability assumption. While Li et al. (2023) provided an affirmative answer to this question in the tabular PAC RL case, the question remains unsettled for both the regret-minimizing RL case and the non-tabular case. In this work, building upon recent advancements in offline RL and reward-agnostic exploration, we develop computationally efficient algorithms for both PAC and regret-minimizing RL with linear function approximation, without single-policy concentrability. We demonstrate that these algorithms achieve sharper error or regret bounds that are no worse than, and can improve on, the optimal sample complexity in offline RL (the first algorithm, for PAC RL) and online RL (the second algorithm, for regret-minimizing RL) in linear Markov decision processes (MDPs), regardless of the quality of the behavior policy. To our knowledge, this work establishes the tightest theoretical guarantees currently available for hybrid RL in linear MDPs.
Accelerated Inference for Partially Observed Markov Processes using Automatic Differentiation
Jul 03, 2024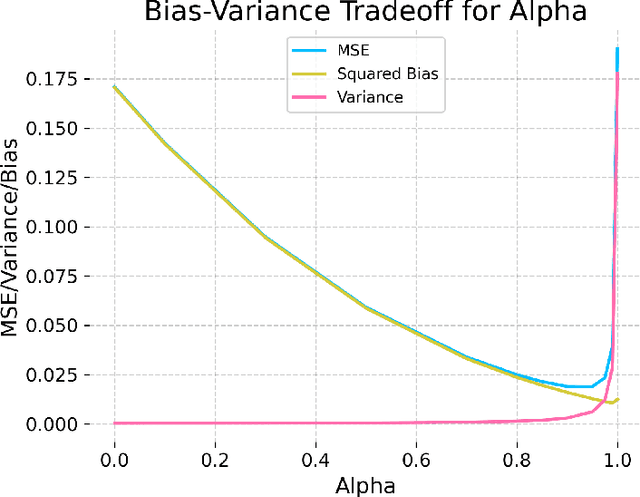

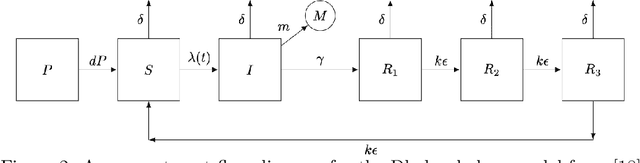
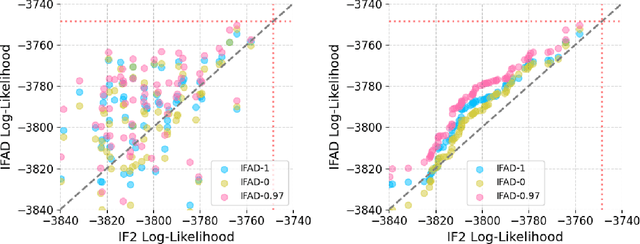
Automatic differentiation (AD) has driven recent advances in machine learning, including deep neural networks and Hamiltonian Markov Chain Monte Carlo methods. Partially observed nonlinear stochastic dynamical systems have proved resistant to AD techniques because widely used particle filter algorithms yield an estimated likelihood function that is discontinuous as a function of the model parameters. We show how to embed two existing AD particle filter methods in a theoretical framework that provides an extension to a new class of algorithms. This new class permits a bias/variance tradeoff and hence a mean squared error substantially lower than the existing algorithms. We develop likelihood maximization algorithms suited to the Monte Carlo properties of the AD gradient estimate. Our algorithms require only a differentiable simulator for the latent dynamic system; by contrast, most previous approaches to AD likelihood maximization for particle filters require access to the system's transition probabilities. Numerical results indicate that a hybrid algorithm that uses AD to refine a coarse solution from an iterated filtering algorithm show substantial improvement on current state-of-the-art methods for a challenging scientific benchmark problem.
Leveraging Offline Data in Linear Latent Bandits
May 27, 2024Sequential decision-making domains such as recommender systems, healthcare and education often have unobserved heterogeneity in the population that can be modeled using latent bandits $-$ a framework where an unobserved latent state determines the model for a trajectory. While the latent bandit framework is compelling, the extent of its generality is unclear. We first address this by establishing a de Finetti theorem for decision processes, and show that $\textit{every}$ exchangeable and coherent stateless decision process is a latent bandit. The latent bandit framework lends itself particularly well to online learning with offline datasets, a problem of growing interest in sequential decision-making. One can leverage offline latent bandit data to learn a complex model for each latent state, so that an agent can simply learn the latent state online to act optimally. We focus on a linear model for a latent bandit with $d_A$-dimensional actions, where the latent states lie in an unknown $d_K$-dimensional subspace for $d_K \ll d_A$. We present SOLD, a novel principled method to learn this subspace from short offline trajectories with guarantees. We then provide two methods to leverage this subspace online: LOCAL-UCB and ProBALL-UCB. We demonstrate that LOCAL-UCB enjoys $\tilde O(\min(d_A\sqrt{T}, d_K\sqrt{T}(1+\sqrt{d_AT/d_KN})))$ regret guarantees, where the effective dimension is lower when the size $N$ of the offline dataset is larger. ProBALL-UCB enjoys a slightly weaker guarantee, but is more practical and computationally efficient. Finally, we establish the efficacy of our methods using experiments on both synthetic data and real-life movie recommendation data from MovieLens.
Distributed Least Squares in Small Space via Sketching and Bias Reduction
May 08, 2024

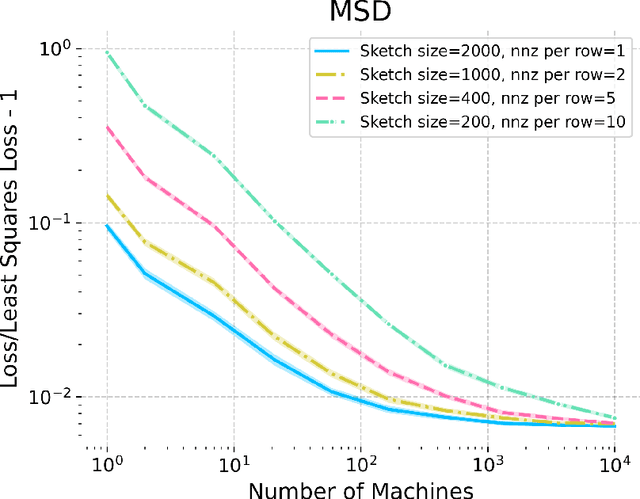

Matrix sketching is a powerful tool for reducing the size of large data matrices. Yet there are fundamental limitations to this size reduction when we want to recover an accurate estimator for a task such as least square regression. We show that these limitations can be circumvented in the distributed setting by designing sketching methods that minimize the bias of the estimator, rather than its error. In particular, we give a sparse sketching method running in optimal space and current matrix multiplication time, which recovers a nearly-unbiased least squares estimator using two passes over the data. This leads to new communication-efficient distributed averaging algorithms for least squares and related tasks, which directly improve on several prior approaches. Our key novelty is a new bias analysis for sketched least squares, giving a sharp characterization of its dependence on the sketch sparsity. The techniques include new higher-moment restricted Bai-Silverstein inequalities, which are of independent interest to the non-asymptotic analysis of deterministic equivalents for random matrices that arise from sketching.
A Natural Extension To Online Algorithms For Hybrid RL With Limited Coverage
Mar 07, 2024
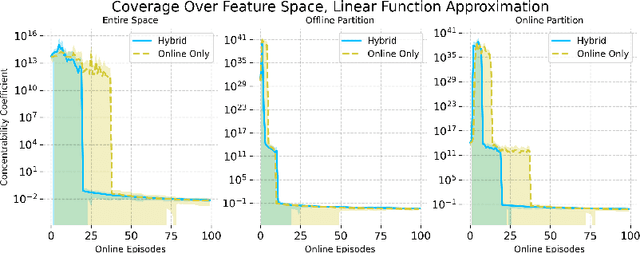


Hybrid Reinforcement Learning (RL), leveraging both online and offline data, has garnered recent interest, yet research on its provable benefits remains sparse. Additionally, many existing hybrid RL algorithms (Song et al., 2023; Nakamoto et al., 2023; Amortila et al., 2024) impose coverage assumptions on the offline dataset, but we show that this is unnecessary. A well-designed online algorithm should "fill in the gaps" in the offline dataset, exploring states and actions that the behavior policy did not explore. Unlike previous approaches that focus on estimating the offline data distribution to guide online exploration (Li et al., 2023b), we show that a natural extension to standard optimistic online algorithms -- warm-starting them by including the offline dataset in the experience replay buffer -- achieves similar provable gains from hybrid data even when the offline dataset does not have single-policy concentrability. We accomplish this by partitioning the state-action space into two, bounding the regret on each partition through an offline and an online complexity measure, and showing that the regret of this hybrid RL algorithm can be characterized by the best partition -- despite the algorithm not knowing the partition itself. As an example, we propose DISC-GOLF, a modification of an existing optimistic online algorithm with general function approximation called GOLF used in Jin et al. (2021); Xie et al. (2022a), and show that it demonstrates provable gains over both online-only and offline-only reinforcement learning, with competitive bounds when specialized to the tabular, linear and block MDP cases. Numerical simulations further validate our theory that hybrid data facilitates more efficient exploration, supporting the potential of hybrid RL in various scenarios.
Offline Policy Evaluation and Optimization under Confounding
Dec 01, 2022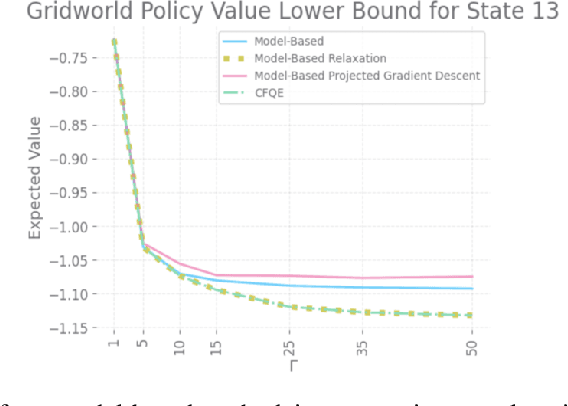
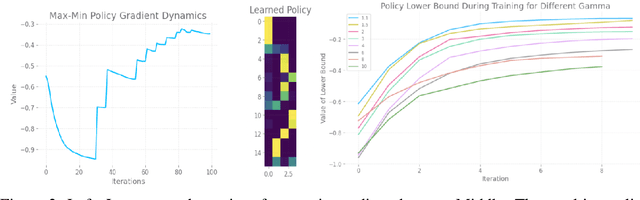
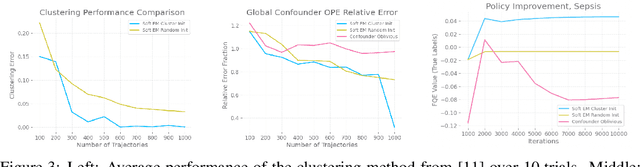
With a few exceptions, work in offline reinforcement learning (RL) has so far assumed that there is no confounding. In a classical regression setting, confounders introduce omitted variable bias and inhibit the identification of causal effects. In offline RL, they prevent the identification of a policy's value, and therefore make it impossible to perform policy improvement. Using conventional methods in offline RL in the presence of confounding can therefore not only lead to poor decisions and poor policies, but can also have disastrous effects in applications such as healthcare and education. We provide approaches for both off-policy evaluation (OPE) and local policy optimization in the settings of i.i.d. and global confounders. Theoretical and empirical results confirm the validity and viability of these methods.