 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretable Hierarchical Attention Network for Medical Condition Identification
Dec 04, 2024


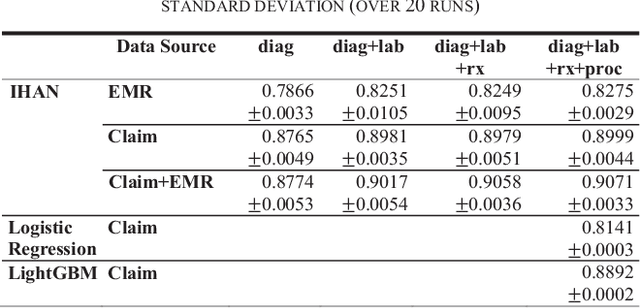
Accurate prediction of medical conditions with straight past clinical evidence is a long-sought topic in the medical management and health insurance field. Although great progress has been made with machine learning algorithms, the medical community is still skeptical about the model accuracy and interpretability. This paper presents an innovative hierarchical attention deep learning model to achieve better prediction and clear interpretability that can be easily understood by medical professionals. This paper developed an Interpretable Hierarchical Attention Network (IHAN). IHAN uses a hierarchical attention structure that matches naturally with the medical history data structure and reflects patients encounter (date of service) sequence. The model attention structure consists of 3 levels: (1) attention on the medical code types (diagnosis codes, procedure codes, lab test results, and prescription drugs), (2) attention on the sequential medical encounters within a type, (3) attention on the individual medical codes within an encounter and type. This model is applied to predict the occurrence of stage 3 chronic kidney disease (CKD), using three years medical history of Medicare Advantage (MA) members from an American nationwide health insurance company. The model takes members medical events, both claims and Electronic Medical Records (EMR) data, as input, makes a prediction of stage 3 CKD and calculates contribution from individual events to the predicted outcome.
A Common-Factor Approach for Multivariate Data Cleaning with an Application to Mars Phoenix Mission Data
Oct 07, 2015



Data quality is fundamentally important to ensure the reliability of data for stakeholders to make decisions. In real world applications, such as scientific exploration of extreme environments, it is unrealistic to require raw data collected to be perfect. As data miners, when it is infeasible to physically know the why and the how in order to clean up the data, we propose to seek the intrinsic structure of the signal to identify the common factors of multivariate data. Using our new data driven learning method, the common-factor data cleaning approach, we address an interdisciplinary challenge on multivariate data cleaning when complex external impacts appear to interfere with multiple data measurements. Existing data analyses typically process one signal measurement at a time without considering the associations among all signals. We analyze all signal measurements simultaneously to find the hidden common factors that drive all measurements to vary together, but not as a result of the true data measurements. We use common factors to reduce the variations in the data without changing the base mean level of the data to avoid altering the physical meaning.