 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOffline Policy Evaluation and Optimization under Confounding
Paper and Code
Dec 01, 2022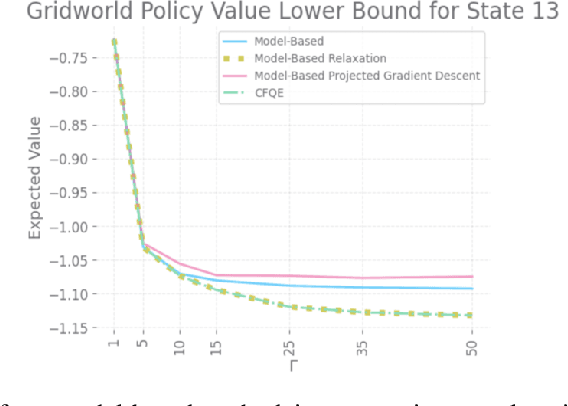
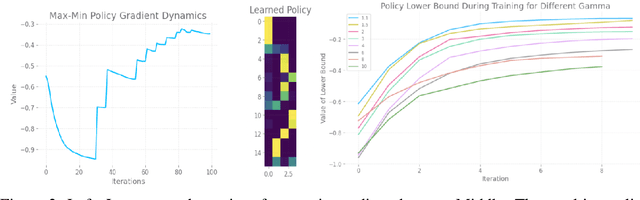
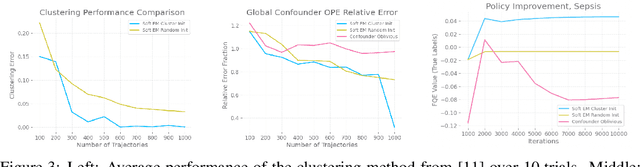
With a few exceptions, work in offline reinforcement learning (RL) has so far assumed that there is no confounding. In a classical regression setting, confounders introduce omitted variable bias and inhibit the identification of causal effects. In offline RL, they prevent the identification of a policy's value, and therefore make it impossible to perform policy improvement. Using conventional methods in offline RL in the presence of confounding can therefore not only lead to poor decisions and poor policies, but can also have disastrous effects in applications such as healthcare and education. We provide approaches for both off-policy evaluation (OPE) and local policy optimization in the settings of i.i.d. and global confounders. Theoretical and empirical results confirm the validity and viability of these methods.